Internet utility testing can finest be described as looking for a needle in a haystack. Besides that the needle strikes, and the haystack grows. The significance of internet utility testing grows greater than ever earlier than in 2024. Why? As a result of customers are transferring to zero endurance relating to glitches, bugs, or something lower than excellent. With the ever-increasing value of internet utility improvement, the necessity to guarantee that your app works seamlessly is now not an excellent idea-rather, it has grow to be an crucial. So, whether or not you’re a testing veteran or simply dipping your toes within the internet testing pool, let’s dive in with the highest ten finest practices to nail it in 2024.
Begin Early and Take a look at Typically
You might have heard the saying, “The early chicken catches the worm.” Properly, within the internet app testing world, the early tester catches the bugs. Having your check up and working early in improvement goes to avoid wasting you a headache of points down the street. It’s very similar to tending a backyard: you wouldn’t let it develop for weed-infested harvest time after which attempt to pull weeds, would you? Identical factor with testing internet purposes: begin early, and let it’s part of your improvement cycle.
Testing shouldn’t be a one-time factor. Continued testing implies that whereas your internet utility is rising and growing, new bugs will make their methods out. Steady testing could improve value of internet utility improvement however retains your app in good working order so these little buggers don’t chew again.
Key advantages of early testing:
Detects bugs and points early, decreasing the complexity and value of fixes.
Permits for smoother integration and fewer disruptions in later improvement levels.
Improves total high quality and stability of the applying.
Steadiness Automated and Guide Internet Software Testing
Automated internet utility testing is very similar to a robotic sidekick-efficient, tireless, excellent for any repetitive work. However allow us to not neglect the human contact on this too. Guide testing of internet purposes is equally vital and acquires particular significance within the area of consumer expertise. No robotic actually understands the nuances of human habits in any case (no less than not but).
What’s so good with automation is regression testing, load testing-just something the place you need accuracy. On the similar time, guide testing pays off in areas the place you really want to place in your consumer’s sneakers. It’s all in regards to the candy spot-automation of no matter you may however not at the price of human perception.
Prioritize Safety Testing
In case your internet utility had been a fortress, then safety testing can be the moat stuffed with alligators. The cyber threats in 2024 are very advanced. Hackers are constantly in search of vulnerabilities, and the very last thing any given enterprise would need is to be their subsequent goal.
How do you retain your utility safe? Run safety testing recurrently to catch and patch vulnerabilities. Consider it like locking all the doorways and home windows in your own home earlier than you go to mattress. Yeah, it’s somewhat bit of labor, however peace of thoughts is effectively value it.
Frequent safety checks to carry out:
Don’t Overlook Usability Testing
Think about strolling right into a restaurant with a complicated menu, tiny print, and a surly waiter who doesn’t perceive your order. Irritating, appropriate? That’s what it looks like when a consumer experiences a poorly designed internet utility. Usability testing ensures that your app shall be as user-friendly as doable.
They wish to intuitively use your app in 2024-no guide required. Take a look at for usability in your app by having some actual folks attempt to use it. Take heed to their suggestions and make changes accordingly. If they’re having an excellent consumer expertise, they’re extra more likely to stick round.
Embrace Cross-Browser Testing
In a perfect world, each consumer would have the identical browser on the identical machine. Actuality is a bit messy. With numerous combos of browsers, units, and working methods, cross-browser testing turns into a should.
Consider it like catering a multicourse dinner to a room of individuals with completely different sorts of dietary restrictions. You need all people to have the ability to take pleasure in their meal it doesn’t matter what they will or can’t eat. Cross-browser testing makes positive that your internet app performs because it ought to, whether or not your customers are on Chrome, Firefox, or Safari, or something in between.
Plan for Efficiency Testing
Efficiency is the unsung hero of internet app testing. It’s not solely about whether or not the app does its job; it’s additionally about how effectively it might do it. That mainly means a extremely quick load time, easy interplay, and no lag. Efficiency testing helps pinpoint any bottlenecks or points that decelerate your app.
Consider efficiency testing as a tune-up in your automobile. You actually would by no means drive in a automobile with squeaky brakes or a malfunctioning engine, proper? Your internet app isn’t any completely different. Common efficiency testing retains it going easy and ensures an amazing consumer expertise.
Leverage Actual Consumer Monitoring (RUM)
Now, that’s the place issues get attention-grabbing. Actual consumer monitoring lets you view exactly how actual customers are interacting along with your internet utility. You’ll be able to grow to be that fly on the wall taking a look at what they’re doing proper now. RUM provides actually invaluable perception into precisely how your app is performing within the wild.
As a consequence of RUM, you may find out about points that you’ll have missed within the managed check. Your utility crashes on one machine sort solely, or it’s actually gradual to load at one geographical location. This data is now in a position for use to enhance your utility and therefore the expertise in your customers.
Doc All the things
Any testing performed on an online utility might be advanced and at occasions chaotic. That’s the reason documentation is so necessary. It’s essential to have detailed information of your testing course of, check outcomes, and issues that come up. You might be leaving trails of breadcrumbs for your self so that you just may discover your method backward, if want be.
It additionally helps within the onboarding of latest workforce members, monitoring of progress, and assurance of consistency in your testing. So, don’t skip this step. This may not be probably the most glamorous a part of internet app testing, however it’s undoubtedly among the many most necessary ones.
Adapt to Agile Testing
2024, and the times of a protracted improvement cycle are undoubtedly behind us. That’s agile improvement for you, so internet testing has to maneuver on the similar tempo, too. Agile testing is equal to being versatile, adaptive, and ready to pivot because the mission evolves. It’s like a jazz musician, improvising and staying in sync with the remainder of the band.
Agile testing assists in catching points earlier and adjustment on-the-fly, offering a functionality to ship a greater product quicker. It’s collaboration, communication, and fixed iteration. So, when you’re nonetheless mired in outdated methods of testing, then it’s time to embrace the longer term.
Keep Up to date with the Newest Instruments and Developments
Expertise is altering at an ever-increasing tempo. What labored for you final 12 months could now not be related right this moment. Staying present with the newest instruments and developments in internet testing is vital to success in 2024. Just a few of the important thing instruments and developments that needs to be on everybody’s radar embody:
AI-powered Testing Instruments: Make the most of AI for extra environment friendly check case era and anomaly detection.
Visible Testing Instruments: Guarantee your app’s visible parts render appropriately throughout completely different units.
Efficiency Monitoring Instruments: Monitor your utility’s efficiency to determine any potential bottlenecks.
It implies that investing time in staying updated won’t solely enhance the way you check but in addition retains you aggressive in an ever-changing business. , like holding match, it’s important to maintain exercising that testing muscle to maintain that muscle form.
In Conclusion: The Artwork and Science of Internet Software Testing
Testing an online utility in 2024 is an artwork and a science in equal measure. It’s balancing automated and guide testing, guaranteeing safety, specializing in efficiency, and staying agile. However greater than the rest, it’s being human. Which means entering into the sneakers of 1’s customers and developing with an expertise that’s not solely purposeful however pleasing.
Testing internet purposes isn’t in search of bugs; it’s about making one thing your customers will love. Sure, the price of internet utility improvement is excessive. However the price of not testing? Even greater. So begin early, check usually, and by no means cease enhancing.
Additionally bear in mind, identical to the needle in a haystack, typically the tiny issues may trigger the biggest complications. With good follow, although, you’ll greater than be able to deal with something that comes your method. Completely satisfied testing!
Cybercrime is escalating globally. Prison teams are leveraging superior know-how to function throughout borders, necessitating that legislation enforcement businesses have the capabilities to stop, examine, and prosecute these crimes whereas additionally defending human rights. Efficient worldwide cooperation is important to fight these threats and uphold shared values. Whereas the lately adopted UN Conference towards Cybercrime addresses necessary points across the want for elevated cyber capability constructing, it raises considerations across the safety of shared rights and values, and requires extra consideration earlier than ratification by member states.
Considerations for human rights and liberal democracies values within the UN Conference towards Cybercrime
Given the ability of networks to rework how we reside, work, study, and play, it’s pure that felony teams additionally use extra advances in know-how to function extra effectively than up to now with out regard for nationwide borders. In response, we have to guarantee legislation enforcement businesses have the mandatory capabilities to stop, examine, and prosecute transnational cybercrimes. We should additionally uphold and defend the significance of fundamental human rights and the rule of legislation.
Sadly, the UN Conference, because it stands, doesn’t sufficiently defend fundamental human rights and poses dangers to the rule of legislation.
Reasonably than particularly specializing in hacking and cybercrimes, it broadly goals on the misuse of laptop networks to disseminate objectionable info. This represents a misalignment with the values of free speech in liberal democracies, which ought to be addressed through an modification earlier than the Conference is taken up by member states for adoption.
As suppliers of foundational services and products very important to financial development and stability, know-how leaders like Cisco have our personal obligations to drive adoption of concrete practices that enhance the security and safety of the shared community we more and more depend on. We share considerations about how greatest to allow governments, legislation enforcement, and nationwide safety officers to guard their residents towards crime and terror whilst the mandatory info requires the help of different governments. On the identical time, our societies should successfully stability the reputable wants of governments to pursue cybercriminals throughout borders with our shared values and long-standing commitments.
Extra alignment with present worldwide legislation enforcement frameworks wanted
We must also not overlook the significance of the unique cybercrime settlement. The Council of Europe Cybercrime Treaty, typically known as the Budapest Conference, has been round for 20-plus years. This present settlement ought to be extra broadly adopted, and it’s regrettable that the brand new UN settlement doesn’t align extra tightly with present worldwide legislation enforcement frameworks, which mirror rigorously negotiated balances between competing equities.
For instance, the Budapest Conference ensures that signatory nations have a 24/7 level of contact that may be reached within the occasion of an emergency. The settlement serves as a default framework for cross-border cooperation the place there is no such thing as a present mutual or bilateral authorized help treaty. Importantly it allowed the US authorities to not signal on to components of it that will have required the prosecution of crimes that will violate the First Modification of the US Structure. Even when we want a separate UN treaty, it ought to parallel beforehand agreed norms of governmental habits.
Capability constructing effort: a welcome addition to the battle towards cybercrime
The UN treaty consists of an necessary capability constructing effort that’s not contemplated by the Budapest Conference. That’s a welcome addition to worldwide cybercrime conversations. Coaching and schooling will help set up a standard understanding in regards to the forms of info accessible and the best way to examine and prosecute crimes.
These packages additionally assist guarantee that there’s not solely schooling but in addition sources to have the ability to do these sorts of issues. The outcome will likely be larger confidence, settlement, and certainty about what sorts of acts are felony, assuming the challenges in regards to the scope I outlined above are addressed.
Discovering the appropriate stability for the pursuit of cybercrime whereas defending human rights and due course of
There’s definitely a path ahead the place the capabilities of an efficient device for cross border device pursuit of cyber criminals is mixed with capability constructing sources for creating and rising economies inside a framework that honors shared values and prior commitments to guard human rights and due course of.
Cisco stands able to accomplice with governments on getting the reply to those powerful questions proper. We urge UN member states to take a cautious have a look at the textual content of the UN Conference and take into account the best way to higher align it with the authorities and protections already within the Budapest Conference earlier than continuing to ratify its present model.
Posted by Robbie McLachlan – Developer Advertising and marketing
Final yr #WeArePlay went on a digital tour of India, Europe and Japan to highlight the tales of app and recreation founders. Immediately, we’re persevering with our tour the world over with our subsequent cease: Australia
From an app serving to individuals throughout pure disasters to a recreation selling wellbeing by houseplants, meet the 50 apps and video games corporations constructing rising companies on Google Play.
Let’s take a fast street journey throughout the territories.
Tristan’s app offers correct data to individuals throughout pure disasters
Tristan, founding father of Catastrophe Science
Meet Tristan from Canberra, founding father of Catastrophe Science. When Tristan was stranded by a bushfire with pals throughout a vacation, he realized the necessity to have correct data in a disaster scenario. Moved to assist others, he leveraged his software program improvement expertise to create his app, Bushfire.io. It collects knowledge from a number of sources to provide individuals an outline of fires, floods, street closures, and very important climate updates.
He has lately added real-time satellite tv for pc imagery and has plans to develop additional internationally, with protection of region-specific occasions like cyclones, earthquakes, evacuations and warmth warnings.
Christine and Lauren’s promotes wellbeing by houseplants
Christine and Lauren, co-founders of Kinder World
Associates Christine and Lauren from Melbourne co-founded gaming firm Kinder World. As a toddler, Lauren used video video games to assuage the ache of her persistent ear infections. That was how she found they could possibly be a therapeutic expertise for individuals—a sentiment she devoted her profession to. She partnered with engineer Christina to make Kinder World: Cozy Vegetation.
Within the recreation, gamers enter the comforting, botanical world of houseplants, dwelling ornament, steaming scorching espresso, and freshly baked cookies. Since going viral on a number of social media platforms, the app has seen large development.
Kathryn’s app helps cut back stress and anxiousness in youngsters
Kathryn, founding father of Brave Youngsters
Kathryn from Melbourne is the founding father of Brave Youngsters. When Kathryn’s son was anxious and fearful each time she dropped him off in school, as a health care provider, her instincts for early intervention kicked in. She sought recommendation from pediatric colleagues to create tales to clarify his day, making him the principle character. Associates in the same scenario started to ask her for recommendation and use the tales for their very own youngsters so she created Brave Youngsters.
A library of real-world tales for folks to personalize, Brave Youngsters helps youngsters to visualise their day and handle their expectations. Her app has grow to be in style amongst households of delicate and autistic youngsters, and Kathryn is now working with preschools to provide much more youngsters the instruments to really feel assured.
As a UX skilled in in the present day’s data-driven panorama, it’s more and more seemingly that you just’ve been requested to design a customized digital expertise, whether or not it’s a public web site, consumer portal, or native software. But whereas there continues to be no scarcity of selling hype round personalization platforms, we nonetheless have only a few standardized approaches for implementing customized UX.
Article Continues Beneath
That’s the place we are available. After finishing dozens of personalization tasks over the previous few years, we gave ourselves a objective: might you create a holistic personalization framework particularly for UX practitioners? The Personalization Pyramid is a designer-centric mannequin for standing up human-centered personalization packages, spanning knowledge, segmentation, content material supply, and general targets. By utilizing this strategy, it is possible for you to to grasp the core parts of a up to date, UX-driven personalization program (or on the very least know sufficient to get began).
Rising instruments for personalization: In keeping with a Dynamic Yield survey, 39% of respondents felt assist is accessible on-demand when a enterprise case is made for it (up 15% from 2020).
Supply: “The State of Personalization Maturity – This fall 2021” Dynamic Yield performed its annual maturity survey throughout roles and sectors within the Americas (AMER), Europe and the Center East (EMEA), and the Asia-Pacific (APAC) areas. This marks the fourth consecutive 12 months publishing our analysis, which incorporates greater than 450 responses from people within the C-Suite, Advertising, Merchandising, CX, Product, and IT.
For the sake of this text, we’ll assume you’re already aware of the fundamentals of digital personalization. A superb overview will be discovered right here: Web site Personalization Planning. Whereas UX tasks on this space can tackle many alternative kinds, they usually stem from comparable beginning factors.
Frequent eventualities for beginning a personalization challenge:
Your group or consumer bought a content material administration system (CMS) or advertising and marketing automation platform (MAP) or associated know-how that helps personalization
The CMO, CDO, or CIO has recognized personalization as a objective
Buyer knowledge is disjointed or ambiguous
You’re working some remoted concentrating on campaigns or A/B testing
Stakeholders disagree on personalization strategy
Mandate of buyer privateness guidelines (e.g. GDPR) requires revisiting present consumer concentrating on practices
Workshopping personalization at a convention.
No matter the place you start, a profitable personalization program would require the identical core constructing blocks. We’ve captured these because the “ranges” on the pyramid. Whether or not you’re a UX designer, researcher, or strategist, understanding the core parts can assist make your contribution profitable.
From the bottom up: Soup-to-nuts personalization, with out going nuts.
From high to backside, the degrees embrace:
North Star: What bigger strategic goal is driving the personalization program?
Objectives: What are the precise, measurable outcomes of this system?
Touchpoints: The place will the customized expertise be served?
Contexts and Campaigns: What personalization content material will the consumer see?
Person Segments: What constitutes a novel, usable viewers?
Actionable Knowledge: What dependable and authoritative knowledge is captured by our technical platform to drive personalization?
Uncooked Knowledge: What wider set of information is conceivably out there (already in our setting) permitting you to personalize?
We’ll undergo every of those ranges in flip. To assist make this actionable, we created an accompanying deck of playing cards as an example particular examples from every degree. We’ve discovered them useful in personalization brainstorming classes, and can embrace examples for you right here.
Personalization pack: Deck of playing cards to assist kickstart your personalization brainstorming.
A north star is what you might be aiming for general together with your personalization program (huge or small). The North Star defines the (one) general mission of the personalization program. What do you want to accomplish? North Stars forged a shadow. The larger the star, the larger the shadow. Instance of North Begins may embrace:
Operate: Personalize based mostly on fundamental consumer inputs. Examples: “Uncooked” notifications, fundamental search outcomes, system consumer settings and configuration choices, normal customization, fundamental optimizations
Function: Self-contained personalization componentry. Examples: “Cooked” notifications, superior optimizations (geolocation), fundamental dynamic messaging, personalized modules, automations, recommenders
Expertise: Customized consumer experiences throughout a number of interactions and consumer flows. Examples: Electronic mail campaigns, touchdown pages, superior messaging (i.e. C2C chat) or conversational interfaces, bigger consumer flows and content-intensive optimizations (localization).
Product: Extremely differentiating customized product experiences. Examples: Standalone, branded experiences with personalization at their core, just like the “algotorial” playlists by Spotify reminiscent of Uncover Weekly.
North star playing cards. These can assist orient your staff in direction of a typical objective that personalization will assist obtain; Additionally, these are helpful for characterizing the end-state ambition of the presently said personalization effort.
As in any good UX design, personalization can assist speed up designing with buyer intentions. Objectives are the tactical and measurable metrics that may show the general program is profitable. A superb place to begin is together with your present analytics and measurement program and metrics you may benchmark in opposition to. In some instances, new targets could also be applicable. The important thing factor to recollect is that personalization itself is just not a objective, relatively it’s a means to an finish. Frequent targets embrace:
Conversion
Time on job
Web promoter rating (NPS)
Buyer satisfaction
Objective playing cards. Examples of some widespread KPIs associated to personalization which might be concrete and measurable.
Touchpoints are the place the personalization occurs. As a UX designer, this might be considered one of your largest areas of duty. The touchpoints out there to you’ll rely upon how your personalization and related know-how capabilities are instrumented, and must be rooted in bettering a consumer’s expertise at a specific level within the journey. Touchpoints will be multi-device (cellular, in-store, web site) but additionally extra granular (net banner, net pop-up and so forth.). Listed here are some examples:
Channel-level Touchpoints
Electronic mail: Position
Electronic mail: Time of open
In-store show (JSON endpoint)
Native app
Search
Wireframe-level Touchpoints
Internet overlay
Internet alert bar
Internet banner
Internet content material block
Internet menu
Touchpoint playing cards. Examples of widespread personalization touchpoints: these can range from slim (e.g., e mail) to broad (e.g., in-store).
For those who’re designing for net interfaces, for instance, you’ll seemingly want to incorporate customized “zones” in your wireframes. The content material for these will be offered programmatically in touchpoints based mostly on our subsequent step, contexts and campaigns.
Focused Zones: Examples from Kibo of customized “zones” on page-level wireframes occurring at numerous phases of a consumer journey (Engagement part at left and Buy part at proper.)
Supply: “Important Information to Finish-to-Finish Personaliztion” by Kibo.
When you’ve outlined some touchpoints, you may think about the precise customized content material a consumer will obtain. Many personalization instruments will refer to those as “campaigns” (so, for instance, a marketing campaign on an internet banner for brand spanking new guests to the web site). These will programmatically be proven at sure touchpoints to sure consumer segments, as outlined by consumer knowledge. At this stage, we discover it useful to contemplate two separate fashions: a context mannequin and a content material mannequin. The context helps you think about the extent of engagement of the consumer on the personalization second, for instance a consumer casually looking info vs. doing a deep-dive. Consider it when it comes to info retrieval behaviors. The content material mannequin can then assist you to decide what sort of personalization to serve based mostly on the context (for instance, an “Enrich” marketing campaign that reveals associated articles could also be an acceptable complement to extant content material).
Marketing campaign and Context playing cards: This degree of the pyramid can assist your staff focus across the sorts of personalization to ship finish customers and the use-cases by which they’ll expertise it.
Person segments will be created prescriptively or adaptively, based mostly on consumer analysis (e.g. by way of guidelines and logic tied to set consumer behaviors or by way of A/B testing). At a minimal you’ll seemingly want to contemplate how you can deal with the unknown or first-time customer, the visitor or returning customer for whom you might have a stateful cookie (or equal post-cookie identifier), or the authenticated customer who’s logged in. Listed here are some examples from the personalization pyramid:
Unknown
Visitor
Authenticated
Default
Referred
Position
Cohort
Distinctive ID
Section playing cards. Examples of widespread personalization segments: at a minimal, you will have to contemplate the nameless, visitor, and logged in consumer sorts. Segmentation can get dramatically extra complicated from there.
Each group with any digital presence has knowledge. It’s a matter of asking what knowledge you may ethically accumulate on customers, its inherent reliability and worth, as to how are you going to use it (typically often known as “knowledge activation.”) Happily, the tide is popping to first-party knowledge: a latest examine by Twilio estimates some 80% of companies are utilizing at the very least some sort of first-party knowledge to personalize the client expertise.
Supply: “The State of Personalization 2021” by Twilio. Survey respondents had been n=2,700 grownup shoppers who’ve bought one thing on-line up to now 6 months, and n=300 grownup supervisor+ decision-makers at consumer-facing firms that present items and/or companies on-line. Respondents had been from the USA, United Kingdom, Australia, and New Zealand.Knowledge was collected from April 8 to April 20, 2021.
First-party knowledge represents a number of benefits on the UX entrance, together with being comparatively easy to gather, extra more likely to be correct, and fewer inclined to the “creep issue” of third-party knowledge. So a key a part of your UX technique must be to find out what the very best type of knowledge assortment is in your audiences. Listed here are some examples:
Determine 1.1.2: Instance of a personalization maturity curve, exhibiting development from fundamental suggestions performance to true individualization. Credit score: https://kibocommerce.com/weblog/kibos-personalization-maturity-chart/
There’s a development of profiling in the case of recognizing and making decisioning about totally different audiences and their indicators. It tends to maneuver in direction of extra granular constructs about smaller and smaller cohorts of customers as time and confidence and knowledge quantity develop.
Whereas some mixture of implicit / expressknowledge is mostly a prerequisite for any implementation (extra generally known as first celebration and third-party knowledge) ML efforts are sometimes not cost-effective immediately out of the field. It is because a powerful knowledge spine and content material repository is a prerequisite for optimization. However these approaches must be thought-about as a part of the bigger roadmap and should certainly assist speed up the group’s general progress. Usually at this level you’ll associate with key stakeholders and product house owners to design a profiling mannequin. The profiling mannequin contains defining strategy to configuring profiles, profile keys, profile playing cards and sample playing cards. A multi-faceted strategy to profiling which makes it scalable.
Whereas the playing cards comprise the place to begin to a list of kinds (we offer blanks so that you can tailor your individual), a set of potential levers and motivations for the type of personalization actions you aspire to ship, they’re extra priceless when considered in a grouping.
In assembling a card “hand”, one can start to hint your entire trajectory from management focus down by a strategic and tactical execution. Additionally it is on the coronary heart of the way in which each co-authors have performed workshops in assembling a program backlog—which is a advantageous topic for an additional article.
Within the meantime, what’s necessary to notice is that every coloured class of card is useful to survey in understanding the vary of decisions probably at your disposal, it’s threading by and making concrete selections about for whom this decisioning might be made: the place, when, and the way.
State of affairs A: We need to use personalization to enhance buyer satisfaction on the web site. For unknown customers, we’ll create a brief quiz to raised determine what the consumer has come to do. That is typically known as “badging” a consumer in onboarding contexts, to raised characterize their current intent and context.
Any sustainable personalization technique should think about close to, mid and long-term targets. Even with the main CMS platforms like Sitecore and Adobe or essentially the most thrilling composable CMS DXP on the market, there may be merely no “simple button” whereby a personalization program will be stood up and instantly view significant outcomes. That mentioned, there’s a widespread grammar to all personalization actions, identical to each sentence has nouns and verbs. These playing cards try and map that territory.
Retrieval-augmented era (RAG) programs are remodeling AI by enabling giant language fashions (LLMs) to entry and combine data from exterior vector databases with no need fine-tuning. This method permits LLMs to ship correct, up-to-date responses by dynamically retrieving the newest information, decreasing computational prices, and enhancing real-time decision-making.
For instance, firms like JPMorgan Chase use RAG programs to automate the evaluation of monetary paperwork, extracting key insights essential for funding choices. These programs have allowed monetary giants to course of 1000’s of monetary statements, contracts, and studies, extracting key monetary metrics and insights which are important for funding choices. Nevertheless, a problem arises when coping with non-machine-readable codecs like scanned PDFs, which require Optical Character Recognition (OCR) for correct information extraction. With out OCR expertise, important monetary information from paperwork like S-1 filings and Ok-1 types can’t be precisely extracted and built-in, limiting the effectiveness of the RAG system in retrieving related data.
On this article, we’ll stroll you thru a step-by-step information to constructing a monetary RAG system. We’ll additionally discover efficient options by Nanonets for dealing with monetary paperwork which are machine-unreadable, making certain that your system can course of all related information effectively.
Understanding RAG Methods
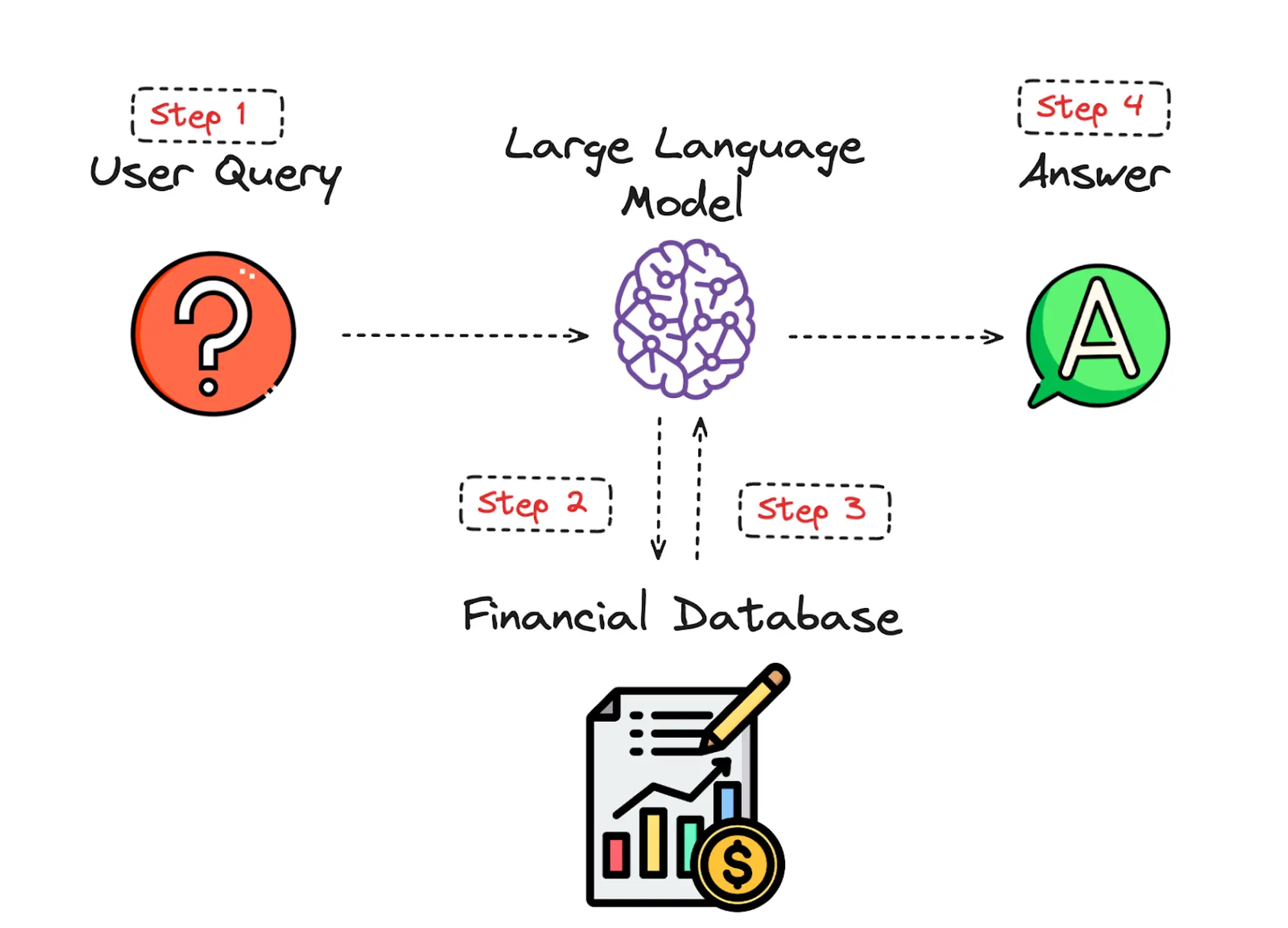
Constructing a Retrieval-Augmented Era (RAG) system includes a number of key elements that work collectively to boost the system’s skill to generate related and contextually correct responses by retrieving and using exterior data. To higher perceive how RAG programs function, let’s shortly evaluate the 4 primary steps, ranging from when the person enters their question to when the mannequin returns its reply.
How does data circulation in a RAG app
1. Person Enters Question
The person inputs a question via a person interface, comparable to an online type, chat window, or voice command. The system processes this enter, making certain it’s in an acceptable format for additional evaluation. This may contain fundamental textual content preprocessing like normalization or tokenization.
The question is handed to the Massive Language Mannequin (LLM), comparable to Llama 3, which interprets the question and identifies key ideas and phrases. The LLM assesses the context and necessities of the question to formulate what data must be retrieved from the database.
2. LLM Retrieves Knowledge from the Vector Database
The LLM constructs a search question primarily based on its understanding and sends it to a vector database comparable to FAISS, which is a library developed by Fb AI that gives environment friendly similarity search and clustering of dense vectors, and is broadly used for duties like nearest neighbor search in giant datasets.
The embeddings which is the numerical representations of the textual information that’s used to be able to seize the semantic which means of every phrase within the monetary dataset, are saved in a vector database, a system that indexes these embeddings right into a high-dimensional area. Transferring on, a similarity search is carried out which is the method of discovering essentially the most comparable objects primarily based on their vector representations, permitting us to extract information from essentially the most related paperwork.
The database returns a listing of the highest paperwork or information snippets which are semantically just like the question.
3. Up-to-date RAG Knowledge is Returned to the LLM
The LLM receives the retrieved paperwork or information snippets from the database. This data serves because the context or background information that the LLM makes use of to generate a complete response.
The LLM integrates this retrieved information into its response-generation course of, making certain that essentially the most present and related data is taken into account.
4. LLM Replies Utilizing the New Identified Knowledge and Sends it to the Person
Utilizing each the unique question and the retrieved information, the LLM generates an in depth and coherent response. This response is crafted to deal with the person’s question precisely, leveraging the up-to-date data offered by the retrieval course of.
The system delivers the response again to the person via the identical interface they used to enter their question.
Step-by-Step Tutorial: Constructing the RAG App
How you can Construct Your Personal Rag Workflows?
As we acknowledged earlier, RAG programs are extremely useful within the monetary sector for superior information retrieval and evaluation. On this instance, we’re going to analyze an organization often known as Allbirds. We’re going to rework the Allbirds S-1 doc into phrase embeddings—numerical values that machine studying fashions can course of—we allow the RAG system to interpret and extract related data from the doc successfully.
This setup permits us to ask Llama LLM fashions questions that they have not been particularly skilled on, with the solutions being sourced from the vector database. This methodology leverages the semantic understanding of the embedded S-1 content material, offering correct and contextually related responses, thus enhancing monetary information evaluation and decision-making capabilities.
For our instance, we’re going to make the most of S-1 monetary paperwork which include important information about an organization’s monetary well being and operations. These paperwork are wealthy in each structured information, comparable to monetary tables, and unstructured information, comparable to narrative descriptions of enterprise operations, danger elements, and administration’s dialogue and evaluation. This combine of knowledge varieties makes S-1 filings supreme candidates for integrating them into RAG programs. Having mentioned that, let’s begin with our code.
Step 1: Putting in the Needed Packages
Initially, we’re going to be sure that all crucial libraries and packages are put in. These libraries embrace instruments for information manipulation (numpy, pandas), machine studying (sci-kit-learn), textual content processing (langchain, tiktoken), vector databases (faiss-cpu), transformers (transformers, torch), and embeddings (sentence-transformers).
!pip set up numpy pandas scikit-learn
!pip set up langchain tiktoken faiss-cpu transformers pandas torch openai
!pip set up sentence-transformers
!pip set up -U langchain-community
!pip set up beautifulsoup4
!pip set up -U langchain-huggingface
Step 2: Importing Libraries and Initialize Fashions
On this part, we can be importing the mandatory libraries for information dealing with, machine studying, and pure language processing.
As an illustration, the Hugging Face Transformers library offers us with highly effective instruments for working with LLMs like Llama 3. It permits us to simply load pre-trained fashions and tokenizers, and to create pipelines for numerous duties like textual content era. Hugging Face’s flexibility and huge assist for various fashions make it a go-to alternative for NLP duties. The utilization of such library is dependent upon the mannequin at hand,you may make the most of any library that provides a functioning LLM.
One other vital library is FAISS. Which is a extremely environment friendly library for similarity search and clustering of dense vectors. It allows the RAG system to carry out fast searches over giant datasets, which is crucial for real-time data retrieval. Related libraries that may carry out the identical job do embrace Pinecone.
Different libraries which are used all through the code embrace such pandas and numpy which permit for environment friendly information manipulation and numerical operations, that are important in processing and analyzing giant datasets.
Be aware: RAG programs provide an excessive amount of flexibility, permitting you to tailor them to your particular wants. Whether or not you are working with a selected LLM, dealing with numerous information codecs, or selecting a selected vector database, you may choose and customise libraries to greatest fit your objectives. This adaptability ensures that your RAG system could be optimized for the duty at hand, delivering extra correct and environment friendly outcomes.
import os
import pandas as pd
import numpy as np
import faiss
from bs4 import BeautifulSoup
from langchain.vectorstores import FAISS
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, pipeline
import torch
from langchain.llms import HuggingFacePipeline
from sentence_transformers import SentenceTransformer
from transformers import AutoModelForCausalLM, AutoTokenizer
Step 3: Defining Our Llama Mannequin
Outline the mannequin checkpoint path in your Llama 3 mannequin.
The above part initializes the Llama 3 mannequin and its tokenizer. It masses the mannequin configuration, adjusts the rope_scaling parameters to make sure they’re appropriately formatted, after which masses the mannequin and tokenizer.
Transferring on, we are going to create a textual content era pipeline with blended precision (fp16).
text_generation_pipeline = pipeline(
"text-generation",
mannequin=mannequin,
tokenizer=tokenizer,
torch_dtype=torch.float16,
max_length=256, # Additional scale back the max size to avoid wasting reminiscence
device_map="auto",
truncation=True # Guarantee sequences are truncated to max_length
)
immediate = """
person
Hiya it's good to satisfy you!
assistant
"""
output = llm(immediate)
print(output)
This creates a textual content era pipeline utilizing the Llama 3 mannequin and verifies its performance by producing a easy response to a greeting immediate.
Step 4: Defining the Helper Capabilities
load_and_process_html(file_path) Operate
The load_and_process_html perform is accountable for loading the HTML content material of monetary paperwork and extracting the related textual content from them. Since monetary paperwork could include a mixture of structured and unstructured information, this perform tries to extract textual content from numerous HTML tags like
,
, and . By doing so, it ensures that every one the important data embedded inside completely different components of the doc is captured.
With out this perform, it will be difficult to effectively parse and extract significant content material from HTML paperwork, particularly given their complexity. The perform additionally incorporates debugging steps to confirm that the right content material is being extracted, making it simpler to troubleshoot points with information extraction.
def load_and_process_html(file_path):
with open(file_path, 'r', encoding='latin-1') as file:
raw_html = file.learn()
# Debugging: Print the start of the uncooked HTML content material
print(f"Uncooked HTML content material (first 500 characters): {raw_html[:500]}")
soup = BeautifulSoup(raw_html, 'html.parser')
# Strive completely different tags if
does not exist
texts = [p.get_text() for p in soup.find_all('p')]
# If no
tags discovered, attempt different tags like
if not texts:
texts = [div.get_text() for div in soup.find_all('div')]
# If nonetheless no texts discovered, attempt or print extra of the HTML content material
if not texts:
texts = [span.get_text() for span in soup.find_all('span')]
# Closing debugging print to make sure texts are populated
print(f"Pattern texts after parsing: {texts[:5]}")
return texts
create_and_store_embeddings(texts) Operate
The create_and_store_embeddings perform converts the extracted texts into embeddings, that are numerical representations of the textual content. These embeddings are important as a result of they permit the RAG system to grasp and course of the textual content material semantically. The embeddings are then saved in a vector database utilizing FAISS, enabling environment friendly similarity search.
def create_and_store_embeddings(texts):
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
if not texts:
elevate ValueError("The texts checklist is empty. Make sure the HTML file is appropriately parsed and accommodates textual content tags.")
vectors = mannequin.encode(texts, convert_to_tensor=True)
vectors = vectors.cpu().detach().numpy() # Convert tensor to numpy array
# Debugging: Print shapes to make sure they're right
print(f"Vectors form: {vectors.form}")
# Guarantee that there's no less than one vector and it has the right dimensions
if vectors.form[0] == 0 or len(vectors.form) != 2:
elevate ValueError("The vectors array is empty or has incorrect dimensions.")
index = faiss.IndexFlatL2(vectors.form[1]) # Initialize FAISS index
index.add(vectors) # Add vectors to the index
return index, vectors, texts
The retrieve perform handles the core retrieval strategy of the RAG system. It takes a person’s question, converts it into an embedding, after which performs a similarity search throughout the vector database to search out essentially the most related texts. The perform returns the highest okay most comparable paperwork, which the LLM will use to generate a response. As an illustration, in our instance we can be returning the highest 5 comparable paperwork.
def retrieve_and_generate(question, index, texts, vectors, okay=1):
torch.cuda.empty_cache() # Clear the cache
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
query_vector = mannequin.encode([query], convert_to_tensor=True)
query_vector = query_vector.cpu().detach().numpy()
# Debugging: Print shapes to make sure they're right
print(f"Question vector form: {query_vector.form}")
if query_vector.form[1] != vectors.form[1]:
elevate ValueError("Question vector dimension doesn't match the index vectors dimension.")
D, I = index.search(query_vector, okay)
retrieved_texts = [texts[i] for i in I[0]] # Guarantee that is right
# Restrict the variety of retrieved texts to keep away from overwhelming the mannequin
context = " ".be part of(retrieved_texts[:2]) # Use solely the primary 2 retrieved texts
# Create a immediate utilizing the context and the unique question
immediate = f"Based mostly on the next context:n{context}nnAnswer the query: {question}nnAnswer:. If you do not know the reply, return that you just can't know."
# Generate the reply utilizing the LLM
generated_response = llm(immediate)
# Return the generated response
return generated_response.strip()
Step 5: Loading and Processing the Knowledge
In terms of loading and processing information, there are numerous strategies relying on the info kind and format. On this tutorial, we deal with processing HTML recordsdata containing monetary paperwork. We use the load_and_process_html perform that we outlined above to learn the HTML content material and extract the textual content, which is then reworked into embeddings for environment friendly search and retrieval. You will discover the hyperlink to the info we’re utilizing right here.
# Load and course of the HTML file
file_path = "/kaggle/enter/s1-allbirds-document/S-1-allbirds-documents.htm"
texts = load_and_process_html(file_path)
# Create and retailer embeddings within the vector retailer
vector_store, vectors, texts = create_and_store_embeddings(texts)
What our information appears like
Step 6: Testing Our Mannequin
On this part, we're going to check our RAG system through the use of the next instance queries:
First instance QuestionFirst output question
As proven above, the llama 3 mannequin takes within the context retrieved by our retrieval system and utilizing it generates an updated and a extra educated reply to our question.
Second instance QuestionSecond output question
Above is one other question that the mode was able to replying to utilizing further context from our vector database.
Third instance questionThird output question
Lastly, once we requested our mannequin the above given question, the mannequin replied that no particular particulars the place given that may help in it answering the given question. You will discover the hyperlink to the pocket book in your reference right here.
What's OCR?
Monetary paperwork like S-1 filings, Ok-1 types, and financial institution statements include important information about an organization’s monetary well being and operations. Knowledge extraction from such paperwork is complicated as a result of mixture of structured and unstructured content material, comparable to tables and narrative textual content. In instances the place S-1 and Ok-1 paperwork are in picture or non-readable PDF file codecs, OCR is crucial. It allows the conversion of those codecs into textual content that machines can course of, making it potential to combine them into RAG programs. This ensures that every one related data, whether or not structured or unstructured, could be precisely extracted by using these AI and Machine studying algorithms.
How Nanonets Can Be Used to Improve RAG Methods
Nanonets is a strong AI-driven platform that not solely affords superior OCR options but additionally allows the creation of customized information extraction fashions and RAG (Retrieval-Augmented Era) use instances tailor-made to your particular wants. Whether or not coping with complicated monetary paperwork, authorized contracts, or every other intricate datasets, Nanonets excels at processing various layouts with excessive accuracy.
By integrating Nanonets into your RAG system, you may harness its superior information extraction capabilities to transform giant volumes of knowledge into machine-readable codecs like Excel and CSV. This ensures your RAG system has entry to essentially the most correct and up-to-date data, considerably enhancing its skill to generate exact, contextually related responses.
Past simply information extraction, Nanonets may also construct full RAG-based options in your group. With the power to develop tailor-made functions, Nanonets empowers you to enter queries and obtain exact outputs derived from the precise information you’ve fed into the system. This custom-made method streamlines workflows, automates information processing, and permits your RAG system to ship extremely related insights and solutions, all backed by the intensive capabilities of Nanonets’ AI expertise.
OCR for monetary paperwork
The Takeaways
By now, you need to have a stable understanding of learn how to construct a Retrieval-Augmented Era (RAG) system for monetary paperwork utilizing the Llama 3 mannequin. This tutorial demonstrated learn how to rework an S-1 monetary doc into phrase embeddings and use them to generate correct and contextually related responses to complicated queries.
Now that you've discovered the fundamentals of constructing a RAG system for monetary paperwork, it is time to put your information into apply. Begin by constructing your individual RAG programs and think about using OCR software program options just like the Nanonets API in your doc processing wants. By leveraging these highly effective instruments, you may extract information related to your use instances and improve your evaluation capabilities, supporting higher decision-making and detailed monetary evaluation within the monetary sector.






































 App")