iCloud storage leads the pack in Apple’s providers ecosystem
With {hardware} gross sales slowing, Apple shifted to increasing its digital providers choices to generate billions every quarter. One service stands out because the clear chief.
Apple has been aggressively increasing its Companies phase, together with Apple Music, Apple TV+, AppleCare, and the App Retailer, to create a gradual income stream that balances {hardware} gross sales. Whereas all providers should not equally standard, paid iCloud storage is essentially the most extensively adopted regardless of its low price in comparison with different providers.
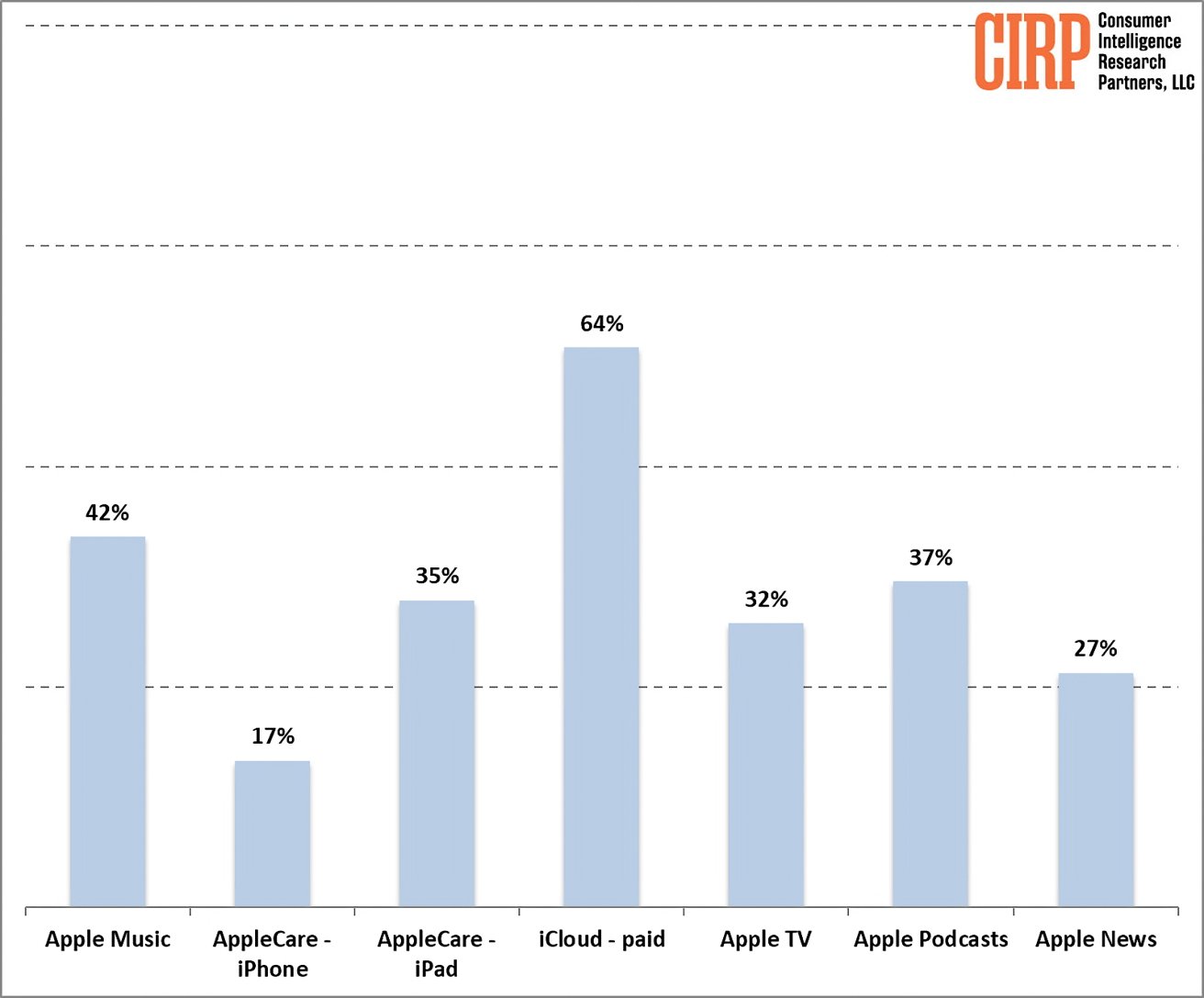
Almost two-thirds of US Apple prospects subscribe to paid iCloud storage, in accordance to new information from Client Intelligence Analysis Companions (CIRP). The seamless integration throughout Apple gadgets and the paltry 5GB free storage restrict encourage customers to improve to paid tiers as soon as they exceed it.
The deep integration of iCloud storage into Apple’s ecosystem and its lack of direct competitors make it the default selection for many Apple customers. As a person’s digital footprint grows, system prompts encourage customers to improve their storage, making certain a easy transition from free to paid tiers.
Though competing cloud storage providers like Microsoft’s OneDrive, Google Drive, and Dropbox exist, they lack the power to seamlessly combine into macOS or iOS. Consequently, customers are required to manually add their information, which can end in particular information sorts, comparable to Apple Notes, eBooks, and well being information, getting left behind.
The competitors: streaming providers & AppleCare
Apple’s streaming providers face more durable competitors. Apple Music competes with Spotify, whereas Apple TV+ faces Netflix. Nonetheless, Apple Music and Apple TV+ have important market shares, with 42% and 32% of Apple prospects subscribing, respectively.
Apple’s streaming providers face more durable competitors
The corporate’s different media providers, like Podcasts and Information, have a considerable person base, however these numbers might embrace free customers. The fierce competitors, with many options, makes it tougher for Apple to dominate these areas, in contrast to with iCloud storage.
AppleCare, the corporate’s prolonged guarantee service, has decrease adoption charges than its digital providers. Because of competitors from carriers and retailers, solely 17% of iPhone consumers go for AppleCare. Not like iCloud storage, AppleCare faces direct competitors in a market with a number of choices on the level of sale.
Apple faces the twin problem of sustaining present service development and innovating new choices to seize buyer curiosity. Paid iCloud storage’s success demonstrates how tightly built-in providers drive person adoption and regular income.
Nonetheless, replicating this success throughout providers requires navigating a extra advanced aggressive panorama. Apple’s ecosystem leverage is essential for sustaining the expansion of the providers phase.
Twenty-four prisoners had been freed in the present day in a global prisoner swap between Russia and Western international locations. Among the many eight Russians repatriated had been a number of convicted cybercriminals. In return, Russia has reportedly launched 16 prisoners, together with Wall Road Journal reporter Evan Gershkovich and ex-U.S. Marine Paul Whelan.
Amongst these within the prisoner swap is Roman Seleznev, 40, who was sentenced in 2017 to 27 years in jail for racketeering convictions tied to a prolonged profession in stealing and promoting cost card knowledge. Seleznev earned this then-record sentence by working a number of the underground’s most bustling marketplaces for stolen card knowledge.
Roman Seleznev, pictured with bundles of money. Picture: US DOJ.
As soon as recognized by the hacker handles “Track2,” “Bulba” and “nCux,” Seleznev is the son of Valery Seleznev, a distinguished member of the Russian parliament who is taken into account an ally of Vladimir Putin. U.S. prosecutors confirmed that for years Seleznev stayed a step forward of the regulation by tapping into contacts on the Russian FSB, the successor company to the Soviet KGB, and by periodically altering hacker handles.
However in 2014 Seleznev was captured by U.S. Secret Service brokers, who had zeroed in on Seleznev’s posh trip spot in The Maldives. On the time, the South Asian island nation was a preferred vacation spot for Jap Europe-based cybercriminals, who considered it as past the attain of U.S. regulation enforcement.
Along with receiving a report jail sentence, Seleznev was ordered to pay greater than $50 million in restitution to his victims. That loss quantity equaled the full losses inflicted by Seleznev’s varied carding shops, and different thefts attributed to members of the hacking discussion board carder[.]su, a bustling cybercrime neighborhood of which Seleznev was a number one organizer.
Additionally launched within the prisoner swap was Vladislav Klyushin, a 42-year-old Muscovite sentenced in September 2023 to 9 years in jail for what U.S. prosecutors referred to as a “$93 million hack-to-trade conspiracy.” Klyushin and his crew hacked into corporations and used info stolen in these intrusions to make unlawful inventory trades.
Klyushin likewise was arrested whereas vacationing overseas: The Related Pressreported that Klyushin was captured in Switzerland after arriving on a personal jet, and simply earlier than he and his get together had been about to board a helicopter to whisk them to a close-by ski resort.
A passport photograph of Klyushin. Picture: USDOJ.
Klyushin is the proprietor of M-13, a Russian expertise firm that contracts with the Russian authorities. Based on prosecutors, M-13 supplied penetration testing and “superior persistent risk (APT) emulation.” As a part of his responsible plea, Klyushin was additionally ordered to forfeit $34 million, and to pay restitution in an quantity that was to be decided.
The U.S. authorities says 4 of Klyushin’s alleged co-conspirators stay at giant, together with Ivan Ermakov, who was amongst 12 Russians charged in 2018 with hacking into key Democratic Occasion e mail accounts.
Among the many Individuals freed by Russia had been Wall Road Journal reporter EvanGershkovich, 32, who has spent the final 16 months in a Russian jail on spying expenses. Additionally launched was Alsu Kurmasheva, 47, a Russian American editor for Radio Free Europe/Radio Liberty who was arrested final yr; and Paul Whelan, 54, a former U.S. Marine arrested in 2018 and accused of spying.
The New York Occasionsstudies a number of others freed by Russia had been German nationals, together with German Moyzhes, a lawyer who was serving to Russians receive residence permits in Germany and different E.U. international locations. The Occasions says Slovenia, Norway and Poland launched 4 folks accused of being Russian spies.
Reuters studies that Germany launched Vadim Krasikov, an FSB colonel serving a life sentence there for murdering an exiled Chechen-Georgian dissident in a Berlin park.
Replace, 8:47 p.m. ET:An earlier model of this story incorrectly reported that one of many Russian hackers launched was the BTC-e co-founder Alexander Vinnik. KrebsOnSecurity was unable to substantiate his launch. The above story has been edited to mirror that change.
After all of the headlines we have now examine how superb Synthetic Intelligence (AI) is and the way companies would actually stagnate in the event that they didn’t have it, it was attention-grabbing to learn this text in Forbes, who counsel that AI inventory is exhibiting “bubble”-like tendencies and will quickly expertise a pointy correction as companies battle to operationalize AI. So, ought to we write off AI? Possibly not.
Maybe the higher plan is to simply accept that AI is on the prime of its hype cycle and, like several new expertise, there will probably be some limitations to ChatGPT-style AI, which in its uncooked state may be topic to points like hallucinations. We knew this anyway, because the CEO of the corporate behind it defined: “ChatGPT is extremely restricted however ok at some elements to create a deceptive impression of greatness. It’s a mistake to be counting on it for something necessary proper now.”
ChatGPT is only one type of AI
However therein lies the issue: ChatGPT isn’t AI. It’s one type of it. It isn’t predictive analytics AI (Machine Studying), which may also help you analyse historic information to supply insights about potential future outcomes. ChatGPT isn’t Laptop Imaginative and prescient, which is now so superior it permits machines to interpret visible information to the extent it’s how your smartphone acknowledges your face and the way autonomous automobiles can see the highway. And it’s definitely not the tip level AI researchers need to get to of Synthetic ‘Common’ Intelligence, AGI, which might be a kind of synthetic intelligence that matches and even surpasses human capabilities throughout a variety of cognitive duties, versus the slender, constrained drawback units we have a tendency to use it to now.
And whereas I take pleasure in taking part in with GenAI as a lot as anybody, and positively see it as an awesome help in some types of enterprise content material creation, at no level did I see it as the idea for a option to predict curiosity and advocate merchandise based mostly on a person’s looking historical past or buy patterns-or what I’d advocate to my shoppers to make use of for processing massive quantities of information or for uncovering insights on of the efficiency of their enterprise, or guiding selections in areas from advertising and marketing methods to stock administration.
AI can ship groundbreaking initiatives
However I’ve (and do, every single day) inform shoppers that they need to be utilizing AI to just do these issues. In reality, rather more: for higher buyer relationship administration, for correct detection of fraud in real-time, for content material moderation at Web scale and quantity, as a perfect means to enhance visibility throughout their provide chains, for gross sales forecasting, improved fault prediction and high quality management in manufacturing and rather more. I’ve labored on a number of massive AI tasks round, for instance, elements just like the human genome and medical monitoring of Olympic athletes, and I’ve sense of what’s IT business hype and what’s truly actual, helpful, and dependable sufficient to look to construct your subsequent wave of innovation on.
I do know AI can ship this. I do know we’re serving to shoppers do genuinely groundbreaking issues with it. However I additionally know that it could be naive to fully ignore a number of the points surrounding AI resembling information bias, lack of governance, confirmed use instances and so forth.
It is much better to take a practical view the place you open your self as much as the probabilities however proceed with each warning and a few assist. That should begin with working by the buzzwords and making an attempt to know what individuals imply, a minimum of at a prime degree, by an LLM or a vector search or possibly even a Naive Bayes algorithm. However then, it is usually necessary to herald a trusted companion that will help you transfer to the subsequent stage to construct a tremendous new digital product, or to endure a digital transformation with an present digital product.
Whether or not you’re in start-up mode, you might be already a scale-up with a brand new concept, otherwise you’re a company innovator seeking to diversify with a brand new product – regardless of the case, you don’t need to waste time studying on the job, and as a substitute need to work with a small, centered crew who can ship distinctive outcomes on the pace of recent digital enterprise.
Get actual about AI by getting actual together with your information first
No matter occurs or doesn’t occur to GenAI, as an enterprise CIO you might be nonetheless going to need to be on the lookout for tech that may be taught and adapt from circumstance and so enable you do the identical. On the finish of the day, hype cycle or not, AI is basically the one instrument within the toolbox that may repeatedly work with you to analyse information within the wild and in non-trivial quantities. This lets you work collectively to seek out good options, adapt them to enhance success charges and higher mannequin the fast-changing world the information is making an attempt to replicate.
There’s much more to profitable AI adoption for innovation, too than signing up for a trial model of the newest GoogleAI helper: it’s actually necessary that you simply clear your information and align your method with the ethics of what you are attempting to do and what it’d imply for information privateness, and so forth.
However the backside line is to suppose much less in regards to the headlines and extra about what superior, non-deterministic programming (in different phrases, AI) may do on your model and the way you’d like to show that imaginative and prescient right into a actuality. For these seeking to be taught extra about AI please obtain our free information for beginning with AI, it’s out there right here.
Sooner or later, you have most likely questioned, can the product proprietor and the Scrum Grasp be the identical particular person? Banish that thought!
You would not be the primary particular person to attempt combining the Scrum Grasp function with the product proprietor function. Individuals ask me daily if they’ll mix the roles of product and ScrumMaster and provides each units of duties to a single particular person.
Normally, attempting to fill these two roles with one particular person is a really unhealthy thought. Completely different people ought to fill these two roles. To see why, let’s look again in historical past on the job of being a pirate ship captain.
The Pirates Knew: Completely different Expertise Require Completely different Individuals
Professor Hayagreeva Rao wrote in Harvard Enterprise Overview in regards to the outcomes of asking his MBA college students to design the job of a seventeenth century pirate ship captain. His MBA college students designed a job that lumped collectively two areas of duty:
Star duties: These are the strategic work of deciding which ships to assault, commanding the crew throughout battle, negotiating with different captains, and so forth
Guardian duties: These are the operational work of distributing their pirate booty, settling battle, punishing crew members, and organizing take care of the wounded
The issue with this job description is that it mixes star and guardian duties. As Professor Rao factors out, there are only a few people who excel at each sorts of job.
Star duties require risk-taking and entrepreneurship, whereas guardian duties require conscientiousness and consistency. A pirate captain good at figuring out ships to assault and at main his crew into battle would probably be bored by the executive trivia of the guardian duties.
To make issues worse, Professor Rao asserts that individuals are likely to spend most of their effort on the duties they’re good at (and presumably get pleasure from). My expertise definitely bears this out. Meaning it’s even more durable to succeed when mixing roles that require totally different abilities.
Pirates solved the issue by having two leaders on every ship: a captain answerable for the star duties and a quartermaster common answerable for the guardian duties.
4 Causes Scrum Masters Ought to Not Additionally Be Product Homeowners
So what does the decidedly non-collaborative, non-agile setting of a pirate ship must do with Scrum? Simply as pirate ships had separate people as captain and quartermaster common, agile tasks ought to have separate Scrum Masters and product homeowners. Let’s take a look at 4 explanation why the product proprietor and Scrum Grasp shouldn’t be the identical particular person.
1. Scrum Masters and Product Homeowners Carry out Completely different Duties
First, the roles of product proprietor and ScrumMaster have very totally different duties (accountabilities), and subsequently require very totally different abilities. Product homeowners carry out the star duties of building a imaginative and prescient for a product, defining one of the best outcomes the product can create for its customers, and defining the options that can get it there. Scrum Masters carry out the guardian duties of defending a crew from distractions and bettering collaboration and focus.
That’s, whereas a product proprietor is figuring out what to construct, the ScrumMaster helps the crew work collectively to allow them to.
In some ways, this may be considered much like the concept a crew’s programmer and tester ought to be separate. Positive, a superb programmer can take a look at and a superb tester can program. However, separating these roles is normally a good suggestion.
2. Every Function Is a Full-Time Job on Its Personal
Second, it’s fairly probably that being both ScrumMaster or product proprietor requires full- or close to full-time consideration. Placing one particular person in each roles on the identical time will nearly definitely shortchange one of many two.
3. Product Homeowners and Scrum Masters Are inclined to Have Completely different Personalities
Third, there’s some overlap within the abilities and character traits that make good product homeowners and ScrumMasters. Nevertheless, the roles are totally different, and this can be very unlikely that somebody will have the ability to excel at each, particularly on the identical time.
4. A Pure Stress Exists Between Product Proprietor and Scrum Grasp roles
Lastly, a pure stress ought to exist between the product proprietor and Scrum Grasp roles. Though every is undeniably dedicated to the success of the product or system being developed, product homeowners naturally need extra, extra, extra.
ScrumMasters, alternatively, are extra attuned to the problems that may come up from a crew below undue strain to ship extra, extra, extra.
When a stability exists between the roles, a product proprietor is free to comply with their pure tendency to ask for extra, secure with the reassurance that the ScrumMaster will forestall pushing too exhausting.
Are There Ever Exceptions?
As with all rule, there are occasions when one particular person can act as a Scrum Grasp and product proprietor on the identical time. I’ve encountered conditions wherein the ScrumMaster and product proprietor had been the identical particular person, and the place I felt that was applicable. A few of these have included small organizations that would not afford the luxurious of devoted or separate people.
Different conditions had been small groups who had began within the pursuit of a technical product proprietor’s imaginative and prescient. On such small groups, anybody character can have an outsized impact on the crew, no matter any formal function performed by the particular person.
Different exceptions have been ScrumMasters concerned in contract improvement. It’s common on such a undertaking for the “true product proprietor” to exist throughout the shopper asking for the software program to be constructed. Sadly, it’s also frequent for such true product homeowners to not wish to be deeply concerned within the undertaking on the degree a Scrum crew wants. It’s in these instances {that a} good ScrumMaster typically steps up and into the function as a proxy for that true product proprietor.
And in a number of particular situations, I’ve seen somebody fill each roles efficiently, towards all odds. Every has been an distinctive particular person, maybe the Blackbeards of Scrum. Nevertheless, in every case, my response was to suppose how a lot better the particular person may have achieved if enabled to work in solely one of many roles.
So, certain there are exceptions—identical to there are to any rule. Nevertheless, none of these exceptions ought to exist for the long run. And anybody in each roles concurrently ought to pay attention to the challenges the twin function presents. And in addition ought to think about what they would possibly lose in attempting to fill each roles.
On this weblog publish, we current a high-level description of the methodology underpinning these feeds, which we’ve documented in additional element in a paper accessible on ArXiv.
Downside
Given historic and up to date prospects’ interactions, what are essentially the most related objects to show on the house web page of each buyer from a given set of things equivalent to promotional objects or newly launched objects? To reply this query at scale, there are 4 challenges that we would have liked to beat:
Buyer illustration problem – Bol has greater than 13 million prospects with numerous pursuits and interplay conduct. How can we develop buyer profiles?
Merchandise illustration problem – Bol has greater than 40 million objects on the market, every having its personal wealthy metadata and interplay knowledge. How can we signify objects?
Matching problem – how can we effectively and successfully match interplay knowledge of 13 million prospects with doubtlessly 40 million objects?
Rating problem – In what order can we present the highest N objects per buyer from a given set of related merchandise candidates?
On this weblog, we give attention to addressing the primary three challenges.
Answer
To deal with the three of the 4 challenges talked about above, we use embeddings. Embeddings are floating level numbers of a sure dimension (e.g. 128). They’re additionally known as representations or (semantic) vectors. Embeddings have semantics. They’re educated in order that comparable objects have comparable embeddings, whereas dissimilar objects are educated to have totally different embeddings. Objects might be any kind of knowledge together with textual content, picture, audio, and video. In our case, the objects are merchandise and prospects. As soon as embeddings can be found, they’re used for a number of functions equivalent to environment friendly similarity matching, clustering, or serving as enter options in machine studying fashions. In our case, we use them for environment friendly similarity matching. See Determine 1 for examples of merchandise embeddings.
Determine 1: Objects in a catalog are represented with embeddings, that are floating numbers of a sure dimension (e.g. 128). Embeddings are educated to be comparable when objects have frequent traits or serve comparable capabilities, whereas people who differ are educated to have dissimilar embeddings. Embeddings are generally used for similarity matching. Any kind of knowledge may be embedded. Textual content (language knowledge), tabular knowledge, picture, and audio can all be embedded both individually or collectively.
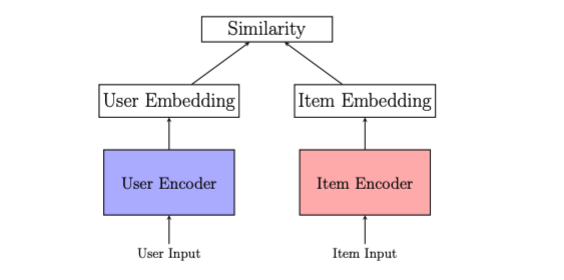
The frequent method to utilizing embeddings for personalization is to depend on a user-item framework (see Determine 2). Within the user-item framework, customers and objects are represented with embeddings in a shared embedding area. Customers have embeddings that replicate their pursuits, derived from their historic searches, clicks and purchases, whereas objects have embeddings that seize the interactions on them and the metadata info accessible within the catalog. Personalization within the user-item framework works by matching consumer embeddings with the index of merchandise embeddings.
Determine 2: Consumer-to-item framework: Single vectors from the consumer encoder restrict illustration and interpretability as a result of customers have numerous and altering pursuits. Maintaining consumer embeddings recent (i.e.capturing most up-to-date pursuits) calls for high-maintenance infrastructure due to the necessity to run the embedding mannequin with most up-to-date interplay knowledge.
We began with the user-item framework and realized that summarizing customers with single vectors has two points:
Single vector illustration bottleneck. Utilizing a single vector to signify prospects introduces challenges as a result of variety and complexity of consumer pursuits, compromising each the capability to precisely signify customers and the interpretability of the illustration by obscuring which pursuits are represented and which aren’t.
Excessive infrastructure and upkeep prices. Producing and sustaining up-to-date consumer embeddings requires substantial funding when it comes to infrastructure and upkeep. Every new consumer motion requires executing the consumer encoder to generate recent embeddings and the next suggestions. Moreover, the consumer encoder have to be massive to successfully mannequin a sequence of interactions, resulting in costly coaching and inference necessities.
To beat the 2 points, we moved from a user-to-item framework to utilizing an item-to-item framework (additionally known as query-to-item or query-to-target framework). See Determine 3. Within the item-to-item framework, we signify customers with a set of question objects. In our case, question objects discuss with objects that prospects have both seen or bought. Generally, they might additionally embrace search queries.
Determine 3: Question-to-item framework: Question embeddings and their similarities are precomputed. Customers are represented by a dynamic set of queries that may be up to date as wanted.
Representing customers with a set of question objects supplies three benefits:
Simplification of real-time deployment: Buyer question units can dynamically be up to date as interactions occur. And this may be executed with out operating any mannequin in real-time. That is doable as a result of all objects within the catalog are identified to be potential view or purchase queries, permitting for the pre-computation of outcomes for all queries.
Enhanced interpretability: Any personalised merchandise advice may be traced again to an merchandise that’s both seen or bought.
Elevated computational effectivity: The queries which are used to signify customers are shared amongst customers. This permits computational effectivity because the question embeddings and their respective similarities may be re-used as soon as computed for any buyer.
Pfeed – A technique for producing personalised feed
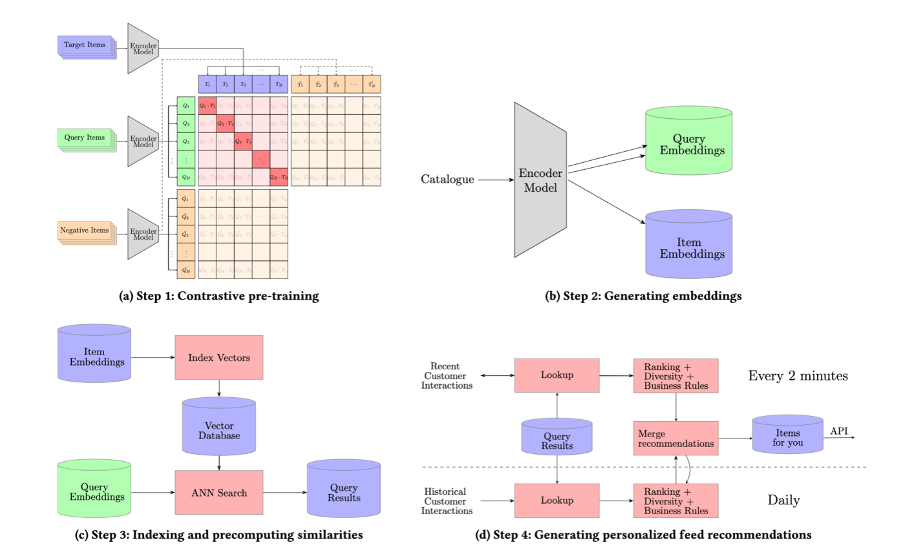
Our technique for creating personalised feed suggestions, which we name Pfeed, includes 4 steps (See Figures 4).
Determine 4: The key steps concerned in producing close to real-time personalised suggestions
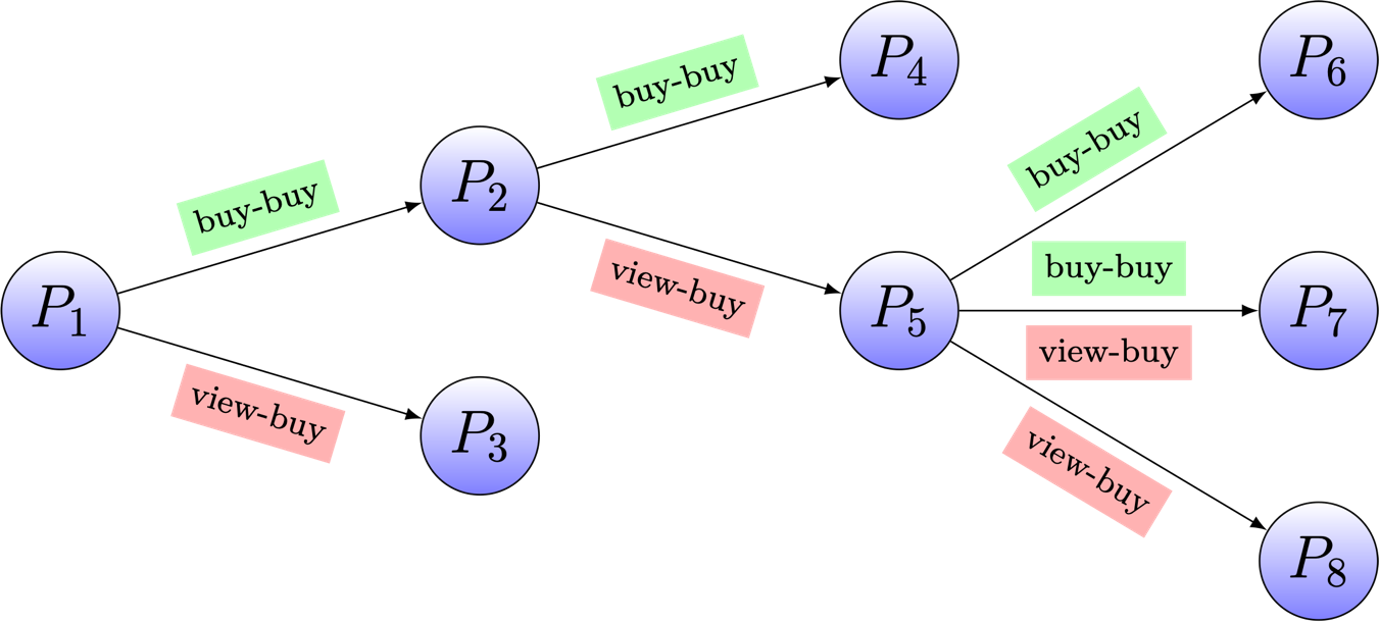
Step 1 is about coaching a transformer encoder mannequin to seize the item-to-item relationships proven in Determine 5. Right here, our innovation is that we use three particular tokens to seize the distinct roles that objects play in several contexts: view question, purchase question and, goal merchandise.
View queries are objects clicked throughout a session resulting in the acquisition of particular objects, thus creating view-buy relationships. Purchase queries, however, are objects steadily bought together with or shortly earlier than different objects, establishing buy-buy relationships.
We discuss with the objects that comply with view or purchase queries as goal objects. A transformer mannequin is educated to seize the three roles of an merchandise utilizing three distinct embeddings. As a result of our mannequin generates the three embeddings of an merchandise in a single shot, we name it a SIMO mannequin (Single Enter Multi Output Mannequin). See paper for extra particulars relating to the structure and the coaching technique.
Determine 5: Product relationships: most prospects that purchase P_2 additionally purchase P_4, ensuing right into a buy-buy relationship. Most prospects that view product P_2 find yourself shopping for P_5, ensuing right into a view-buy relationship. On this instance, P_2 performs three sorts of roles – view question, purchase question ,and goal merchandise. The intention of coaching an encoder mannequin is to seize these present item-to-item relationships after which generalize this understanding to incorporate new potential connections between objects, thereby increasing the graph with believable new item-to-item relationships.
Step 2 is about utilizing the transformer encoder educated in step 1 and producing embeddings for all objects within the catalog.
Step 3 is about indexing the objects that have to be matched (e.g. objects with promotional labels or objects which are new releases). The objects which are listed are then matched in opposition to all potential queries (seen or bought objects). The outcomes of the search are then saved in a lookup desk.
Step 4 is about producing personalised feeds per buyer primarily based on buyer interactions and the lookup desk from step 3. The method for producing a ranked record of things per consumer consists of: 1) choosing queries for every buyer (as much as 100), 2) retrieving as much as 10 potential subsequent items- to-buy for every question, and three) combining these things and making use of rating, variety, and enterprise standards (See Determine 4d). This course of is executed day by day for all prospects and each two minutes for these lively within the final two minutes. Suggestions ensuing from latest queries are prioritized over these from historic ones. All these steps are orchestrated with Airflow.
Purposes of Pfeed
We utilized Pfeed to generate numerous personalised feeds at Bol, viewable on the app or web site with titles like Prime offers for you, Prime picks for you, and New for you. The feeds differ on a minimum of considered one of two components: the precise objects focused for personalization and/or the queries chosen to signify buyer pursuits. There’s additionally one other feed known as Choose Offers for you. On this feed, objects with Choose Offers are personalised completely for Choose members, prospects who pay annual charges for sure advantages. You will discover Choose Offers for you on empty baskets.
Generally, Pfeed is designed to generate”X for you” feed by limiting the search index or the search output to encompass solely objects belonging to class 𝑋 for all potential queries.
Analysis
We carry out two sorts of analysis – offline and on-line. The offline analysis is used for fast validation of the effectivity and high quality of embeddings. The net analysis is used to evaluate the affect of the embeddings in personalizing prospects’ homepage experiences.
Offline analysis
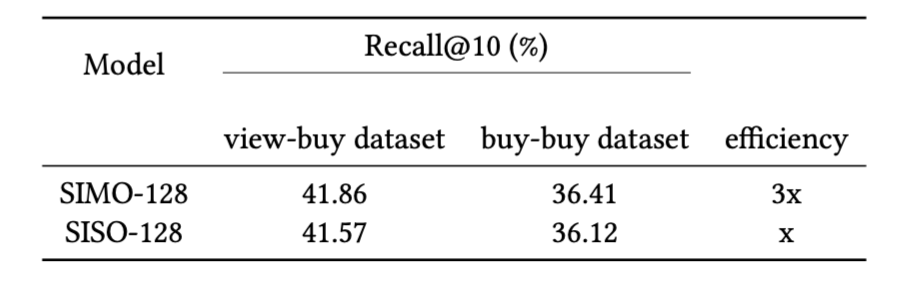
We use about two million matching query-target pairs and about a million random objects for coaching, validation and testing within the proportion of 80%, 10%, %10. We randomly choose one million merchandise from the catalog, forming a distractor set, which is then blended with the true targets within the check dataset. The target of analysis is to find out, for identified matching query-target pairs, the proportion of occasions the true targets are among the many high 10 retrieved objects for his or her respective queries inthe embedding area utilizing dot product (Recall@10). The upper the rating, the higher. Desk 1 exhibits that two embedding fashions, known as SIMO-128 and SISO-128, obtain comparable Recall@10 scores. The SIMO-128 mannequin generates three 128 dimensional embeddings in a single shot, whereas the SISO-128 generates the identical three 128-dimensional embeddings however in three separate runs. The effectivity benefit of SIMO-128 implies that we will generate embeddings for your entire catalog a lot quicker with out sacrificing embedding high quality.
Desk 1: Recall@Ok on view-buy and buy-buy datasets. The SIMO-128 mannequin performs comparably to the SISO-128 mannequin whereas being 3 occasions extra environment friendly throughout inference.
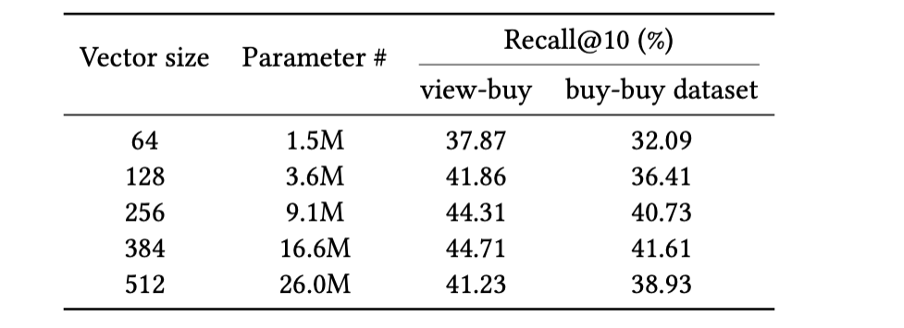
The efficiency scores in Desk 1 are computed from an encoder mannequin that generates 128-dimensional embeddings. What occurs if we use bigger dimensions? Desk 2 supplies the reply to that query. Once we improve the dimensionality of embeddings with out altering another facet, bigger dimensional vectors have a tendency to supply greater high quality embeddings, as much as a sure restrict.
Desk 2: Influence of hidden dimension vector dimension on Recall@Ok. Maintaining different parts of the mannequin the identical and rising solely the hidden dimension results in elevated efficiency till a sure restrict.
One difficult facet in Pfeed is dealing with query-item pairs with advanced relations (1-to-many, many-to-one, and many-to-many). An instance is a diaper buy.
There are fairly just a few objects which are equally prone to be bought together with or shortly earlier than/after the acquisition of diaper objects equivalent to child garments and toys.
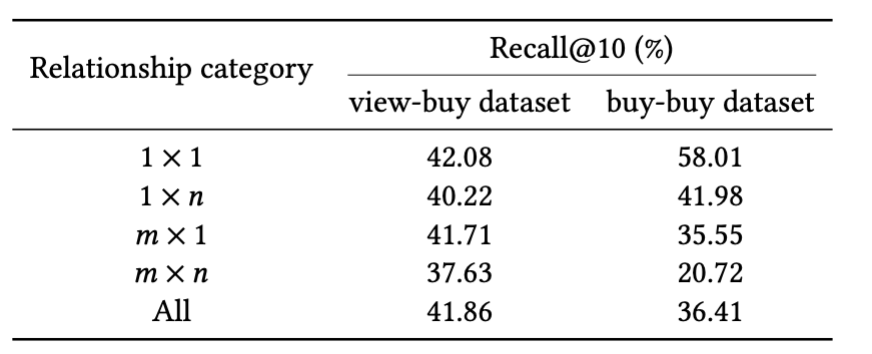
Such advanced query-item relations are more durable to seize with embeddings. Desk 3 exhibits Recall@10 scores for various ranges of relationship complexity. Efficiency on query-to-item with advanced relations is decrease than these with easy relations (1-to-1 relation).
Desk 3: Retrieval efficiency is greater on check knowledge with easy 1 x 1 relations than with advanced relations (1 x n, m x 1 and m x n relations).
On-line experiment
We ran a web based experiment to guage the enterprise affect of Pfeed. We in contrast a therapy group receiving personalised Prime offers for you merchandise lists (generated by Pfeed) in opposition to a management group that acquired a non-personalized Prime offers record, curated by promotion specialists.
This experiment was performed over a two-week interval with an excellent 50- 50 cut up between the 2 teams. Personalised high offers suggestions result in a 27% improve in engagement (want record additions) and a 4.9% uplift in conversion in comparison with expert-curated non-personalized high offers suggestions (See Desk 4).
Desk 4: Personalised high offers suggestions result in a 27% improve in engagement (want record additions) and a 4.9% uplift in conversion in comparison with expert-curated non-personalized high offers suggestions.
Conclusions and future work
We launched Pfeed, a way deployed at Bol for producing personalised product feeds: Prime offers for you, Prime picks for you, New for you, and Choose offers for you. Pfeed makes use of a query-to-item framework, which differs from the dominant user-item framework in personalised recommender techniques. We highlighted three advantages: 1) Simplified real-time deployment. 2) Improved interpretability. 3) Enhanced computational effectivity.
Future work on Pfeed will give attention to increasing the mannequin embedding capabilities to deal with advanced query-to-item relations equivalent to that of diaper objects being co-purchased with numerous different child objects. Second line of future work can give attention to dealing with specific modelling of generalization and memorization of relations, adaptively selecting both method primarily based on frequency. Continuously occurring query-to-item pairs might be memorized and people who contain tail objects (low frequency or newly launched objects) might be modelled primarily based on content material options equivalent to title and descriptions. At present, Pfeed solely makes use of content material for modelling each head and tail objects.
If such a work conjures up you or you might be on the lookout for new challenges, contemplate checking for accessible alternatives on bol’s careers web site.
Acknowledgements
We thank Nick Tinnemeier and Eryk Lewinson for suggestions on this publish.