In the present day’s knowledge lakes are increasing throughout traces of enterprise working in various landscapes and utilizing varied engines to course of and analyze knowledge. Historically, SQL views have been used to outline and share filtered knowledge units that meet the necessities of those traces of enterprise for simpler consumption. Nevertheless, with prospects utilizing totally different processing engines of their knowledge lakes, every with its personal model of views, they’re creating separate views per engine, including to upkeep overhead. Moreover, accessing these engine-defined views requires prospects to have elevated entry ranges, granting them entry to each the SQL view itself and the underlying databases and tables referenced within the view’s SQL definition. This strategy impedes granting constant entry to a subset of information utilizing SQL views, hampering productiveness and rising administration overhead.
Glue Knowledge Catalog views is a brand new characteristic of the AWS Glue Knowledge Catalog that prospects can use to create a standard view schema and single metadata container that may maintain view-definitions in several dialects that can be utilized throughout engines similar to Amazon Redshift and Amazon Athena. By defining a single view object that may be queried from a number of engines, Knowledge Catalog views allow prospects to handle permissions on a single view schema persistently utilizing AWS Lake Formation. A view will be shared throughout totally different AWS accounts as properly. For querying these views, customers want entry to the view object solely and don’t want entry to the referenced databases and tables within the view definition. Additional, all requests towards the Knowledge Catalog views, similar to requests for entry credentials on underlying assets, might be logged as AWS CloudTrail administration occasions for auditing functions.
On this weblog submit, we’ll present how one can outline and question a Knowledge Catalog view on high of open supply desk codecs similar to Iceberg throughout Athena and Amazon Redshift. We may also present you the configurations wanted to limit entry to the underlying database and tables. To comply with alongside, we’ve got supplied an AWS CloudFormation template.
Use case
An Instance Corp has two enterprise models: Gross sales and Advertising. The Gross sales enterprise unit owns buyer datasets, together with buyer particulars and buyer addresses. The Advertising enterprise unit needs to conduct a focused advertising marketing campaign based mostly on a most well-liked buyer record and has requested knowledge from the Gross sales enterprise unit. The Gross sales enterprise unit’s knowledge steward (AWS Id and Entry Administration (IAM) position: product_owner_role), who owns the shopper and buyer deal with datasets, plans to create and share non-sensitive particulars of most well-liked prospects with the Advertising unit’s knowledge analyst (business_analyst_role) for his or her marketing campaign use case. The Advertising workforce analyst plans to make use of Athena for interactive evaluation for the advertising marketing campaign and later, use Amazon Redshift to generate the marketing campaign report.
On this answer, we display how you should use Knowledge Catalog views to share a subset of buyer particulars saved in Iceberg format filtered by the most well-liked flag. This view will be seamlessly queried utilizing Athena and Amazon Redshift Spectrum, with knowledge entry centrally managed via AWS Lake Formation.
Conditions
For the answer on this weblog submit, you want the next:
- An AWS account. For those who don’t have an account, you’ll be able to create one.
- You may have created an information lake administrator Be aware of this position’s Amazon Useful resource Title (ARN) to make use of later. For simplicity’s sake, this submit will use IAM Admin position because the Datalake Admin and Redshift Admin however make it possible for in your setting you comply with the precept of least privilege.
- Beneath Knowledge Catalog settings, have the default settings in place. Each of the next choices needs to be chosen:
- Use solely IAM entry management for brand new databases
- Use solely IAM entry management for brand new tables in new databases
Get began
To comply with the steps on this submit, register to the AWS Administration Console because the IAM Admin and deploy the next CloudFormation stack to create the required assets:
- Select to deploy the CloudFormation template.

- Present an IAM position that you’ve already configured as a Lake Formation administrator.
- Full the steps to deploy the template. Go away all settings as default.
- Choose I acknowledge that AWS CloudFormation would possibly create IAM assets, then select Submit.
The CloudFormation stack creates the next assets. Make an observation of those values—you’ll use them later.
- Amazon Easy Storage Service (Amazon S3) buckets that retailer the desk knowledge and Athena question consequence
- IAM roles:
product_owner_roleandbusiness_analyst_role - Digital personal cloud (VPC) with the required community configuration, which might be used for compute
- AWS Glue database:
customerdb, which comprises thebuyerandcustomer_addresstables in Iceberg format - Glue database:
customerviewdb, which is able to comprise the Knowledge Catalog views - Redshift Serverless cluster

The CloudFormation stack additionally registers the information lake bucket with Lake Formation in Lake Formation entry mode. You may confirm this by navigating to the Lake Formation console and choosing Knowledge lake areas beneath Administration.
Resolution overview
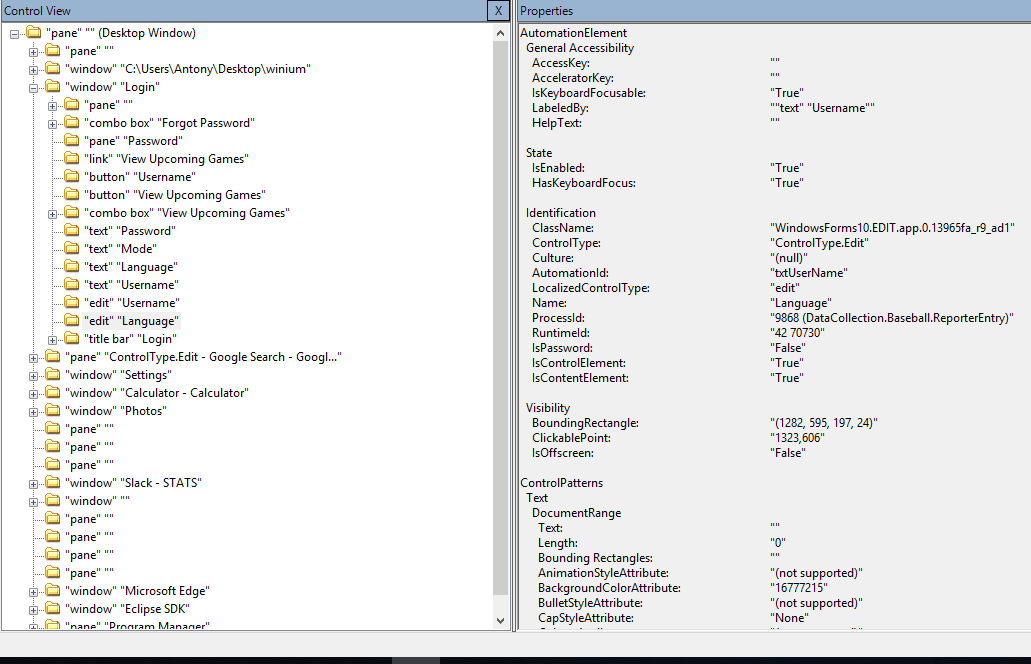
The next determine exhibits the structure of the answer.

As a requirement to create a Knowledge Catalog view, the information lake S3 areas for the tables (buyer and customer_address) should be registered with Lake Formation and granted full permission to product_owner_role.
The Gross sales product proprietor: product_owner_role can also be granted permission to create views beneath customerviewdb utilizing Lake Formation.
After the Glue Knowledge Catalog View (customer_view) is created on the shopper dataset with the required subset of buyer data, the view is shared with the Advertising analyst (business_analyst_role), who can then question the popular buyer’s non delicate data as outlined by the view with out gaining access to underlying buyer tables.
- Allow Lake Formation permission mode on the
customerdbdatabaseand its tables. - Grant the database (
customerdb) and tables (buyerandcustomer_address) full permission toproduct_owner_roleutilizing Lake Formation. - Allow Lake Formation permission mode on the database (
customerviewdb) the place the a number of dialect Knowledge Catalog view might be created. - Grant full database permission to
product_owner_roleutilizing Lake Formation. - Create Knowledge Catalog views as
product_owner_roleutilizing Athena and Amazon Redshift so as to add engine dialects. - Share the database and Knowledge Catalog views learn permission to
business_analyst_roleutilizing Lake Formation. - Question the Knowledge Catalog view utilizing
business_analyst_rolefrom Athena and Amazon Redshift engine.
With the stipulations in place and an understanding of the general answer, you’re able to arrange the answer.
Arrange Lake Formation permissions for product_owner_role
Register to the LakeFormation console as an information lake administrator. For the examples on this submit, we use the IAM Admin position, Admin as the information lake admin.
Allow Lake Formation permission mode on customerdb and its tables
- Within the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- Select customerdb and select Edit.
- Beneath Default permissions for newly created tables, clear Use solely IAM entry management for brand new tables on this database.
- Select Save.

- Beneath Knowledge Catalog within the navigation pane, select Databases.
- Choose customerdb and beneath Motion, choose View
- Choose the IAMAllowedPrincipal from the record and select Revoke.

- Repeat the identical for all tables beneath the database customerdb.
Grant the product_owner_role entry to customerdb and its tables
Grant product_owner_role all permissions to the customerdb database.
- On the Lake Formation console, beneath Permissions within the navigation pane, select Knowledge lake permissions.
- Select Grant.
- Beneath Principals, choose IAM customers and roles.
- Choose product_owner_role.
- Beneath LF-Tags or catalog assets, choose Named Knowledge Catalog assetsand choose customerdb for Databases.
- Choose SUPER for Database permissions.
- Select Grant to use the permissions.


Grant product_owner_role all permissions to the buyer and customer_address tables.
- On the Lake Formation console, beneath Permissions within the navigation pane, select Knowledge lake permission
- Select Grant.
- Beneath Principals, choose IAM customers and roles.
- Select the product_owner_role.
- Beneath LF-Tags or catalog assets, select Named Knowledge Catalog assetsand choose customerdb for databases and buyer and customer_address for tables.
- Select SUPER for Desk permissions.
- Select Grant to use the permissions.
Allow Lake Formation permission mode
Allow Lake Formation permission mode on the database the place the Knowledge Catalog view might be created.
- Within the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- Choose customerviewdb and select Edit.
- Beneath Default permissions for newly created tables, clear Use solely IAM entry management for brand new tables on this database.
- Select Save.
- Select Databases from Knowledge Catalog within the navigation pane.
- Choose customerviewdb and beneath Motion choose View.
- Choose the IAMAllowedPrincipal from the record and select Revoke.
Grant the product_owner_role entry to customerviewdb utilizing Lake Formation mode
Grant product_owner_role all permissions to the customerviewdb database.
- On the Lake Formation console, beneath Permissions within the navigation pane, select Knowledge lake permissions.
- Select Grant
- Beneath Principals, choose IAM customers and roles.
- Select product_owner_role
- Beneath LF-Tags or catalog assets, select Named Knowledge Catalog assetsand choose customerviewdb for Databases.
- Choose SUPER for Database permissions.
- Select Grant to use the permissions.
Create Glue Knowledge Catalog views as product_owner_role
Now that you’ve Lake Formation permissions set on the databases and tables, you’ll use the product_owner_role to create Knowledge Catalog views utilizing Athena and Amazon Redshift. This may also add the engine dialects for Athena and Amazon Redshift.
Add the Athena dialect
- Within the AWS console, both register utilizing
product_owner_roleor, in case you’re already signed in as an Admin, change toproduct_owner_role. - Launch question editor and choose the workgroup athena_glueview from the higher proper facet of the console. You’ll create a view that mixes knowledge from the
buyerandcustomer_addresstables, particularly for purchasers who’re marked as most well-liked. The tables embrace private details about the shopper, similar to their title, date of beginning, nation of beginning, and e-mail deal with. - Run the next within the question editor to create the
customer_viewview beneath thecustomerviewdbdatabase. - Run the next question to preview the view you simply created.
- Run following question to search out the highest three beginning years with the best buyer counts from the
customer_viewview and show the beginning yr and corresponding buyer depend for every.
Output:
- To validate that the view is created, go to the navigation pane and select Views beneath Knowledge catalog on the Lake Formation console
- Choose customer_view and go to the SQL definition part to validate the Athena engine dialect.

Once you created the view in Athena, it added the dialect for Athena engine. Subsequent, to help the use case described earlier, the advertising marketing campaign report must be generated utilizing Amazon Redshift. For this, you want to add the Redshift dialect to the view so you’ll be able to question it utilizing Amazon Redshift as an engine.
Add the Amazon Redshift dialect
- Register to the AWS console as an Admin, navigate to Amazon Redshift console and register to Redshift Qurey editor v2.
- Connect with the Serverless cluster as Admin (federated person) and run the next statements to grant permission on the Glue automount database (
awsdatacatalog) entry toproduct_owner_roleandbusiness_analyst_role. - Register to the Amazon Redshift console as
product_owner_roleand register to the QEv2 editor utilizingproduct_owner_role(as a federated person). You’ll use the next ALTER VIEW question so as to add the Amazon Redshift engine dialect to the view created beforehand utilizing Athena. - Run the next within the question editor:
- Run following question to preview the view.
- Run the identical question that you just ran in Athena to search out the highest three beginning years with the best buyer counts from the
customer_viewview and show the beginning yr and corresponding buyer depend for every.
By querying the identical view and working the identical question in Redshift, you obtained the identical consequence set as you noticed in Athena.
Validate the dialects added
Now that you’ve added all of the dialects, navigate to the Lake Formation console to see how the dialects are saved.
- On the Lake Formation console, beneath Knowledge catalog within the navigation pane, select Views.
- Choose customer_view and go to SQL definitions part to validate that the Athena and Amazon Redshift dialects have been added.

Alternatively, you too can create the view utilizing Redshift so as to add Redshift dialect and replace in Athena so as to add the Athena dialect.
Subsequent, you will note how the business_analyst_role can question the view with out gaining access to question the underlying tables and the Amazon S3 location the place the information exists.
Arrange Lake Formation permissions for business_analyst_role
Register to the Lake Formation console because the DataLake administrator (For this weblog, we use the IAM Admin position, Admin, because the Datalake admin).
Grant business_analyst_role entry to the database and view utilizing Lake Formation
- On the Lake Formation console, beneath Permissions within the navigation pane, select Knowledge lake permissions.
- Select Grant
- Beneath Principals, choose IAM customers and roles.
- Choose business_analyst_role.
- Beneath LF-Tags or catalog assets, choose Named Knowledge Catalog assets and choose customerviewdb for Databases.
- Choose DESCRIBE for Database permissions.
- Select Grant to use the permissions.

Grant the business_analyst_role SELECT and DESCRIBE permissions to customer_view
- On the Lake Formation console, beneath Permissions within the navigation pane, select Knowledge lake permission.
- Select Grant.
- Beneath Principals, choose IAM customers and roles.
- Choose business_analyst_role.
- Beneath LF-Tags or catalog assets, select Named Knowledge Catalog assets and choose customerviewdb for Databases and customer_view for Views.
- Select SELECT and DESCRIBE for View permissions.
- Select Grant to use the permissions.
Question the Knowledge Catalog views utilizing business_analyst_role
Now that you’ve arrange the answer, take a look at it by querying the information utilizing Athena and Amazon Redshift.
Utilizing Athena
- Register to the Athena console as business_analyst_role.
- Launch question editor and choose the workgroup athena_glueview. Choose database customerviewdb from the dropdown on the left and you must be capable of see the view created beforehand utilizing
product_owner_role. Additionally, discover that no tables are proven as a result ofbusiness_analyst_roledoesn’t have entry granted for the bottom tables. - Run the next within the question editor to question the view question.

As you’ll be able to see within the previous determine, business_analyst_role can question the view with out gaining access to the underlying tables.
- Subsequent, question the desk
buyeron which the view is created. It ought to give an error.
Utilizing Amazon Redshift
- Navigate to the Amazon Redshift console and register to Amazon Redshift question editor v2. Connect with the Serverless cluster as business_analyst_role (federated person) and run the next within the question editor to question the view.
- Choose the customerviewdb on the left facet of the console. It’s best to see the view
customer_view. Additionally, observe that you just can’t see the tables from which the view is created. Run the next within the question editor to question the view.
The enterprise analyst person can run the evaluation on the Knowledge Catalog view without having entry to the underlying databases and tables on from which the view is created.
Glue Knowledge Catalog views supply options for varied knowledge entry and governance situations. Organizations can use this characteristic to outline granular entry controls on delicate knowledge—similar to personally identifiable data (PII) or monetary information—to assist them adjust to knowledge privateness laws. Moreover, you should use Knowledge Catalog views to implement row-level, column-level, and even cell-level filtering based mostly on the particular privileges assigned to totally different person roles or personas, permitting for fine-grained knowledge entry management. Moreover, Knowledge Catalog views can be utilized in knowledge mesh patterns, enabling safe, domain-specific knowledge sharing throughout the group for self-service analytics, whereas permitting customers to make use of most well-liked analytics engines like Athena or Amazon Redshift on the identical views for governance and constant knowledge entry.
Clear up
To keep away from incurring future expenses, delete the CloudFormation stack. For directions, see Deleting a stack on the AWS CloudFormation console. Make sure that the next assets created for this weblog submit are eliminated:
- S3 buckets
- IAM roles
- VPC with community parts
- Knowledge Catalog database, tables and views
- Amazon Redshift Serverless cluster
- Athena workgroup
Conclusion
On this submit, we demonstrated how you can use AWS Glue Knowledge Catalog views throughout a number of engines similar to Athena and Redshift. You may share Knowledge Catalog views in order that totally different personas can question them. For extra details about this new characteristic, see Utilizing AWS Glue Knowledge Catalog views.
In regards to the Authors
 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the large knowledge analytics house since then, serving to prospects construct scalable and sturdy options utilizing AWS analytics companies.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the large knowledge analytics house since then, serving to prospects construct scalable and sturdy options utilizing AWS analytics companies.
 Srividya Parthasarathy is a Senior Large Knowledge Architect on the AWS Lake Formation workforce. She enjoys constructing knowledge mesh options and sharing them with the group.
Srividya Parthasarathy is a Senior Large Knowledge Architect on the AWS Lake Formation workforce. She enjoys constructing knowledge mesh options and sharing them with the group.
 Paul Villena is a Senior Analytics Options Architect in AWS with experience in constructing trendy knowledge and analytics options to drive enterprise worth. He works with prospects to assist them harness the ability of the cloud. His areas of pursuits are infrastructure as code, serverless applied sciences, and coding in Python.
Paul Villena is a Senior Analytics Options Architect in AWS with experience in constructing trendy knowledge and analytics options to drive enterprise worth. He works with prospects to assist them harness the ability of the cloud. His areas of pursuits are infrastructure as code, serverless applied sciences, and coding in Python.
 Derek Liu is a Senior Options Architect based mostly out of Vancouver, BC. He enjoys serving to prospects clear up large knowledge challenges via AWS analytic companies.
Derek Liu is a Senior Options Architect based mostly out of Vancouver, BC. He enjoys serving to prospects clear up large knowledge challenges via AWS analytic companies.