
How typically have you ever caught your self pondering, “Wouldn’t it’s simpler at hand the mission over to AI as an alternative of paying a staff of builders?” It’s a tempting thought, particularly within the age of AI — however the actuality is much extra advanced.
On this article, we’ll discover what AI can really do in software program improvement, the place it nonetheless falls brief in comparison with people, and what conclusions firms ought to draw earlier than entrusting a mission to synthetic intelligence.
When AI Tried to Play Software program Engineer
Not too long ago, a shopper approached SCAND with a novel experiment in thoughts. They needed to check whether or not synthetic intelligence may independently develop a small internet utility and determined to make use of Cursor for the duty. The applying’s function was easy — fetch statistics from an exterior API and show them in a desk.
The preliminary end result appeared promising: AI created a functioning mission that included each client- and server-side elements, applied the fundamental logic for retrieving information, and even designed the interface. The desk appropriately displayed the statistics, and the general code construction appeared respectable at first look.
Nonetheless, upon nearer inspection, it turned clear that the answer was overengineered. As an alternative of instantly connecting to the API and displaying the information within the browser, AI constructed a full backend server that proxied requests, saved intermediate information, and required separate deployment.
For such a easy job, this was pointless — it difficult the infrastructure, added additional setup steps, and lengthened the combination course of.
Furthermore, AI didn’t account for error dealing with, request optimization, or integration with the shopper’s current programs. This meant builders needed to step in and redo components of the answer.
The Limits of Generative AI in Coding and Software program Improvement
Generative AI has already confirmed that it could possibly rapidly produce working code, however in apply, its capabilities in real-world software program improvement typically change into restricted. Listed below are the important thing points we recurrently encounter when reviewing AI‑generated initiatives:
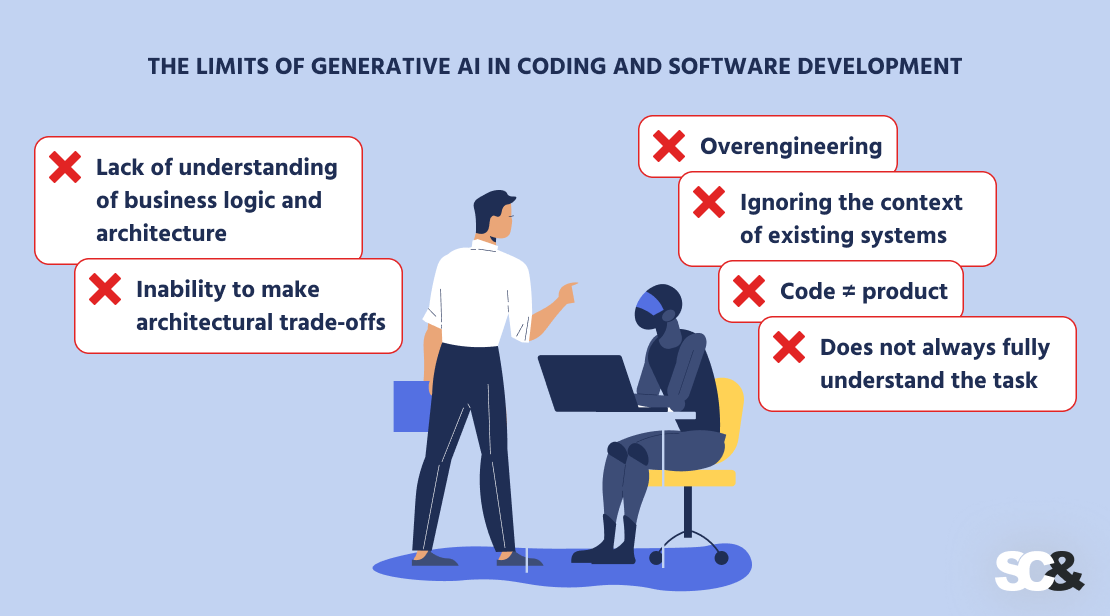
- Lack of awareness of enterprise logic and structure. AI can’t see the complete image of a mission, its objectives, and its constraints. Consequently, the options it produces could also be technically appropriate however fully misaligned with the precise enterprise wants.
- Incapacity to make architectural commerce‑offs. An skilled software program engineer evaluates the steadiness between improvement velocity, implementation value, and ease of upkeep. AI, however, can’t weigh these elements and tends to decide on a normal and even unnecessarily advanced strategy.
- Overengineering. Producing pointless layers, modules, and providers is a typical mistake. For instance, a easy utility could find yourself with an additional backend that requires separate deployment and upkeep.
- Ignoring the context of current programs. AI doesn’t take into consideration how new code will combine with the present infrastructure, which may result in incompatibilities or further prices for rework.
- Code ≠ product. Synthetic intelligence can write fragments of code, however it doesn’t ship full options that take into consideration UX, safety, scalability, and long-term assist.
- Doesn’t at all times absolutely perceive the duty. To get the specified end result, prompts typically should be clarified or rewritten in additional element — generally stretching to a full web page. This slows down the method and forces the developer to spend time refining the request as an alternative of transferring on to efficient implementation.
In the end, regardless of the rising position of AI in software program improvement, with out the involvement of skilled builders, such initiatives danger changing into a supply of technical debt and pointless prices.
Why Human Software program Builders Nonetheless Beat AI Brokers
Sure, generative AI and agentic AI can write code as we speak — generally even pretty good code. However there are nonetheless some issues that synthetic intelligence can’t exchange in knowledgeable software program developer’s workflow..
First, it’s understanding the enterprise context. A human doesn’t simply write a program — they know why and for whom it’s being created. AI sees a set of directions; a developer sees the actual job and understands the way it suits into the corporate’s objectives.
Second comes the power to make knowledgeable choices — whether or not to reuse current code or construct one thing from scratch. A human weighs deadlines, prices, and dangers. AI, in flip, typically follows a template with out taking hidden prices into consideration.
Third, it’s architectural flexibility. An skilled programmer can really feel when a mission is beginning to “develop” pointless layers and is aware of when it’s the suitable time to cease. AI, however, typically creates extreme buildings just because that’s what it has seen in its coaching examples.
Fourth comes desirous about the product’s future. Scalability, maintainability, and dealing with edge circumstances are constructed right into a developer’s mindset. AI will not be but able to anticipating such nuances.
And eventually, communication. A real software program engineer works with the shopper, clarifies necessities, and adjusts the strategy because the mission evolves. AI will not be able to actual dialogue or a delicate understanding of human priorities.
Due to this fact, in as we speak’s software program improvement panorama, synthetic intelligence continues to be a software — not a strategist. And within the foreseeable future, the human position in creating excessive‑high quality software program will stay important.
The desk under compares how people and AI deal with key points of improvement, and why the human position within the course of continues to be necessary.
| Criterion | Software program Developer | Generative AI |
| Understanding enterprise context | Analyzes mission objectives, target market, and long-term targets | Sees solely the given immediate, with out understanding the larger image |
| Making architectural choices | Balances velocity, value, simplicity, and maintainability | Follows a template with out contemplating hidden prices |
| Structure optimization | Avoids pointless modules and simplifies when doable | Liable to overengineering, creating additional layers |
| Working with current programs | Considers integration with present infrastructure | Might generate incompatible options |
| Foresight | Plans for scalability, error dealing with, and edge circumstances | Typically ignores non‑normal eventualities |
| Collaboration | Engages with the shopper, clarifies necessities, affords alternate options | Understands the request in a restricted method, requires exact and detailed prompts |
| Flexibility in course of | Adapts to altering necessities on the fly | Requires code regeneration or a brand new immediate |
| Velocity of code technology | Focuses on correctness and stability over uncooked velocity | Generates code immediately, however it’s not at all times helpful or appropriate |
| Last deliverable | Prepared‑to‑use product | A set of code requiring evaluate and refinement |
Human Builders vs AI in Software program Improvement
The place AI Coding Instruments and Agentic AI Can Assist Software program Engineers
Regardless of its limitations, AI instruments have some strengths that make them precious assistants for software program engineers. In keeping with Statista (2024), 81% of builders worldwide reported elevated productiveness when utilizing AI, and greater than half famous improved work effectivity.
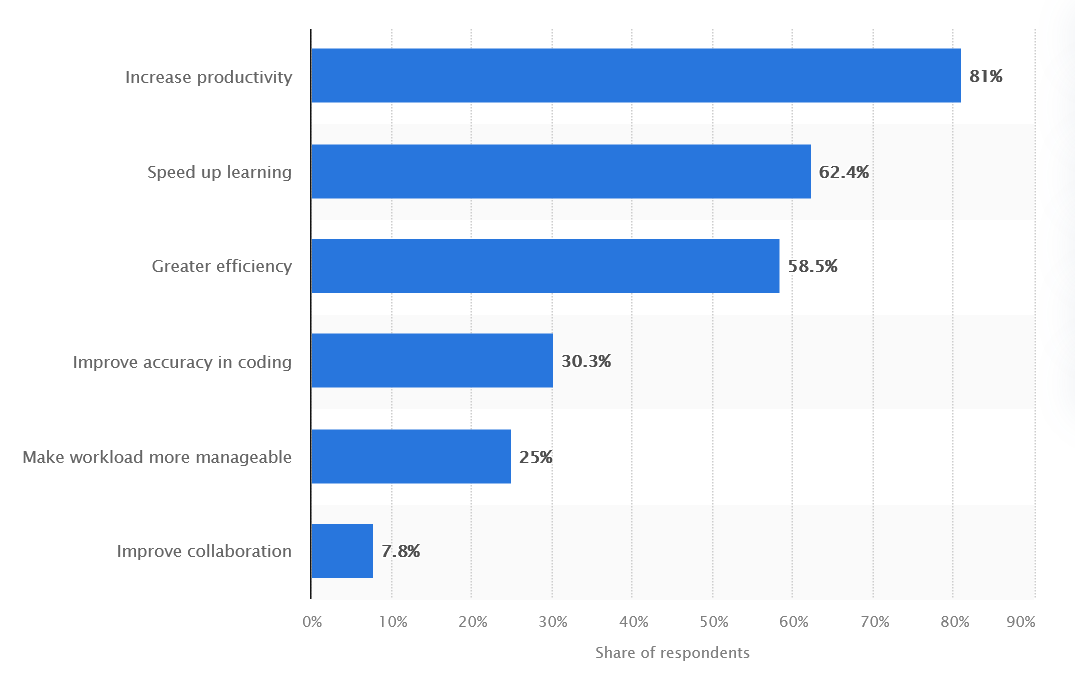
Advantages of utilizing AI within the improvement workflow, Statista
In day‑to‑day improvement, AI can considerably velocity up routine duties and simplify supporting processes, akin to:
- Producing boilerplate code. Generative AI can produce repetitive code buildings in seconds, saving time and permitting builders to give attention to enterprise logic.
- Creating easy elements. AI can rapidly construct buttons, types, tables, and different UI components that may later be tailored to the mission’s wants.
- Changing codecs. Synthetic intelligence can simply remodel information and code — from JSON to YAML or from TypeScript to JavaScript, and again.
- Refactoring. AI can counsel code enhancements, simplify buildings, and take away duplicates.
- Speedy prototyping. AI can construct a primary model of performance to check concepts or exhibit ideas to a shopper.
Nonetheless, even in these use circumstances, AI stays only a software. The ultimate model of the code ought to at all times undergo human evaluate and integration to make sure it meets architectural necessities, high quality requirements, and the mission’s enterprise context.

SCAND’s Method — AI + Human Experience within the Age of AI
At SCAND, we see synthetic intelligence not as a competitor to builders, however as a software that strengthens the staff. Our initiatives are constructed on a easy precept: AI accelerates — people information.
We use Copilot, ChatGPT, Cursor, and different AI instruments the place they really add worth — for rapidly creating templates, producing easy elements, and testing concepts. This enables us to save hours and days on routine duties.
However code technology is barely the start. Each AI‑produced answer goes by means of the arms of our skilled builders who:
- Verify the correctness and safety of the code, together with potential license and copyright violations, since some items of the urged code could replicate fragments from open repositories.
- Optimize the structure for the duty and mission specifics.
- Adapt technical options to the enterprise logic and mission necessities.
We additionally pay particular consideration to information safety and confidentiality:
- We don’t switch confidential information to public cloud-based AI with out safety, until the shopper particularly requests in any other case. In initiatives involving delicate or regulated data (for instance, medical or monetary information), we use native AI assistants — Ollama, LM Studio, llama.cpp, and others — deployed on the shopper’s safe servers.
- We signal clear contracts that specify: who owns the ultimate code, whether or not AI instruments are allowed, and who’s chargeable for reviewing and fixing the code if it violates licenses or incorporates errors.
- We embody obligations for documentation (AI utilization logs indicating when precisely and which instruments have been used) to trace the supply of potential points and guarantee transparency for audits.
- We offer staff coaching on AI greatest practices, together with understanding the constraints of AI-generated content material, licensing dangers, and the significance of handbook validation.
Will AI Exchange Software program Engineers? The Sensible Actuality Verify
In the present day, synthetic intelligence in software program improvement is on the identical degree that calculators have been in accounting a number of many years in the past: a software that hurries up calculations, however doesn’t perceive why and what numbers should be calculated.
Generative AI can already do rather a lot — from producing elements to performing computerized refactoring. However constructing a software program product isn’t just about writing code. It’s about understanding the viewers, designing structure, assessing dangers, integrating with current programs, and planning lengthy‑time period assist for years forward. And that is the place the human issue stays irreplaceable.
As an alternative of the “AI replaces builders” situation, we’re transferring towards a blended‑staff mannequin, the place AI brokers turn into a part of the workflow and builders use them as accelerators and assistants. This synergy is already reshaping the software program improvement panorama and can proceed to outline it within the coming years.
The primary takeaway: the age of AI doesn’t eradicate the occupation of software program engineer — it transforms it, including new instruments and shifting priorities from routine coding towards structure, integration, and strategic design.
Regularly Requested Questions (FAQs)
Can AI write a whole app?
Sure, however typically with out optimization, with over‑engineered structure, and with out contemplating lengthy‑time period maintainability.
Will AI exchange frontend/backend builders?
Not but, since most improvement choices require enterprise context, commerce‑offs, and expertise that AI doesn’t possess.
What’s the largest influence of AI-generated code?
An elevated danger of technical debt, maintainability points, and architectural misalignment — all of which may finally drive up the price of rework.






, redo() capabilities?")
