The M4 Mac mini might have a brand new, smaller design than the present M2 Mac mini (above).
The M4 Mac mini might have a brand new, smaller design than the present M2 Mac mini (above).
Foundry
The M4 Mac mini might have a brand new, smaller design than the present M2 Mac mini (above).
Foundry
Foundry
Launch date: Experiences point out that Apple will launch the M4 Mac mini this fall. It’ll change the M2 Mac mini, which was launched in January 2023. And the M1 Mac mini was launched in November 2020. Apple might be taking this chance to determine a fall launch cycle for the Mac mini, however primarily based on the historical past of the product, the corporate doesn’t appear to imagine {that a} common launch cycle is important for this product.
Design: The Mac mini will bear a drastic change, in response to Gurman. It’ll get even smaller, with a footprint concerning the measurement of the Apple TV. This is able to make the Mac mini extra of a competitor to the Raspberry Pi, a small PC that’s typically utilized in particular setups.
Chip: Apple at the moment provides the Mac mini with a base or Professional M-series chip, and this may proceed with the brand new design. In response to Bloomberg’s Mark Gurman, the Mac mini with a base M4 chip will ship “instantly,” whereas the M4 Professional mannequin gained’t be accessible till late October.
Options: The smaller design might imply that the Mac mini doesn’t supply a number of the ports the present Mac mini provides. Gurman reported that Apple has examined three fashions which have at the least three USB-C ports, an influence connector, and an HDMI port. And whereas Gurman didn’t say so, the USB-C ports are in all probability additionally Thunderbolt ports.
The present M2 Mac mini has a gigabit ethernet port, USB-A ports, and a 3.5mm audio jack. The newest rumors don’t say whether or not the alignment will change. Whereas the ethernet and audio jack are more likely to keep, It’s potential that Apple will drop the USB-A ports. Wi-Fi 7 assist can also be potential because the Wi-Fi Alliance made the normal official in the beginning of January.
Apple’s Macs are much less focused by malware than Home windows PCs, however that does not imply they’re immune. More and more, insidious sorts of Mac malware are being developed which have researchers involved sufficient to challenge public warnings, and that is the case once more as we speak.
As reported by Hacker Information, Cado Safety has recognized a malware-as-a-service (MaaS) focusing on macOS customers named “Cthulhu Stealer.” First noticed in late 2023, the malicious software program is designed to steal delicate info from contaminated Macs, equivalent to saved passwords from iCloud Keychain, info from internet browsers, and even particulars from Telegram accounts.
What’s notably regarding is that it is being offered as a service on the darkish internet for $500 per thirty days, doubtlessly permitting a number of dangerous actors to make use of it towards unsuspecting Mac homeowners.
Cato Safety researcher Tara Gould studies that Cthulhu Stealer disguises itself as widespread software program to trick customers into putting in it. It’d seem as CleanMyMac, Grand Theft Auto IV, and even Adobe GenP (a software some customers make use of to bypass Adobe’s subscription mannequin). The malware comes packaged as a disk picture (DMG) file.
If a person tries to open the pretend app, macOS’s built-in safety characteristic, Gatekeeper, warns that the software program is unsigned. But when a person chooses to bypass this warning, the malware instantly asks for the person’s system password, mimicking a professional system immediate. This method is not new – different Mac malware like Atomic Stealer and MacStealer use related tips.
As soon as it has the mandatory permissions, Cthulhu Stealer can entry and steal a variety of delicate information. For crypto customers, it particularly targets MetaMask digital pockets info. All of this stolen information is then despatched to the attackers’ servers.
Notably, studies recommend that whoever designed Cthulu Stealer is now not lively, apparently following disputes over funds and accusations of scamming their very own clients, i.e. different cybercriminals who had been utilizing the malware.
Whereas Cthulhu Stealer is not probably the most subtle malware on the market, it is nonetheless a big menace to Mac customers who is perhaps tricked into putting in it. Basic safety pointers embody solely downloading software program from trusted sources just like the App Retailer or official developer web sites, being cautious of any app asking in your system password throughout set up, and maintaining your Mac up to date with the newest safety patches from Apple.
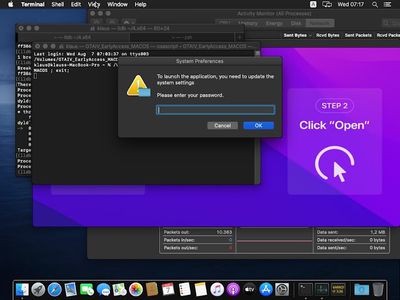
In macOS Sequoia, anticipated to be launched in mid-September, Apple plans to take away the flexibility to simply override Gatekeeper warnings by Management-clicking. As an alternative, customers might want to undergo System Settings to permit unsigned software program to run, including an additional step that may make customers suppose twice earlier than operating doubtlessly harmful apps.
There’s extra to some photographs than meets the attention – their seemingly harmless façade can masks a sinister menace.
02 Apr 2024 • , 4 min. learn
Cybersecurity software program has grown fairly able to detecting suspicious recordsdata, and with companies changing into more and more conscious of the necessity to up their safety posture with extra layers of safety, subterfuge to evade detection has turn into needed.
In essence, any cybersecurity software program is powerful sufficient to detect most malicious recordsdata. Therefore, menace actors frequently search alternative ways to evade detection, and amongst these strategies is utilizing malware hidden in photographs or pictures.
Malware hiding in photographs
It would sound far-fetched, however it’s fairly actual. Malware positioned inside photographs of varied codecs is a results of steganography, the strategy of hiding knowledge inside a file to keep away from detection. ESET Analysis noticed this method being utilized by the Worok cyberespionage group, who hid malicious code in picture recordsdata, solely taking particular pixel info from them to extract a payload to execute. Do thoughts that this was carried out on already compromised techniques although, since as talked about beforehand, hiding malware inside photographs is extra about evading detection than preliminary entry.
Most frequently, malicious photographs are made out there on web sites or positioned inside paperwork. Some may bear in mind adware: code hidden in advert banners. Alone, the code within the picture can’t be run, executed, or extracted by itself whereas embedded. One other piece of malware should be delivered that takes care of extracting the malicious code and working it. Right here the extent of person interplay required is numerous and the way probably somebody is to note malicious exercise appears extra depending on the code that’s concerned with the extracting than on the picture itself.
The least (most) important bit(s)
One of many extra devious methods to embed malicious code in a picture is to exchange the least important bit of every red-green-blue-alpha (RGBA) worth of each pixel with one small piece of the message. One other method is to embed one thing into a picture’s alpha channel (denoting the opacity of a shade), utilizing solely a fairly insignificant portion. This fashion, the picture seems kind of the identical as a daily one, making any distinction exhausting to detect with the bare eye.
An instance of this was when reliable promoting networks served up advertisements that doubtlessly led to a malicious banner being despatched from a compromised server. JavaScript code was extracted from the banner, exploiting the CVE-2016-0162 vulnerability in some variations of Web Explorer, to get extra details about the goal.
It would appear to be each photos are the identical, however one in every of them consists of malicious code within the alpha channel of its pixels. Discover how the image on the fitting is unusually pixelated. (Supply: ESET Analysis)
Malicious payloads extracted from photos could possibly be used for numerous functions. Within the Explorer vulnerability case, the extracted script checked whether or not it was working on a monitored machine — like that of a malware analyst. If not, then it redirected to an exploit equipment touchdown web page. After exploitation, a closing payload was used to ship malware comparable to backdoors, banking trojans, spy ware, file stealers, and related.
From left to proper: Clear picture, picture with malicious content material, and the identical malicious picture enhanced to focus on the malicious code (Supply: ESET Analysis)
As you possibly can see, the distinction between a clear and a malicious picture is relatively small. For a daily particular person, the malicious picture may look simply barely totally different, and on this case, the bizarre look could possibly be chalked as much as poor image high quality and backbone, however the actuality is that each one these darkish pixels highlighted within the image on the proper are an indication of malignant code.
No cause to panic
You could be questioning, then, whether or not the pictures you see on social media might harbor harmful code. Think about that photographs uploaded to social media web sites are normally closely compressed and modified, so it will be very problematic for a menace actor to cover totally preserved and dealing code in them. That is maybe apparent while you evaluate how a photograph seems earlier than and after you’ve uploaded it to Instagram — sometimes, there are clear high quality variations.
Most significantly, the RGB pixel-hiding and different steganographic strategies can solely pose a hazard when the hidden knowledge is learn by a program that may extract the malicious code and execute it on the system. Photos are sometimes used to hide malware downloaded from command and management (C&C) servers to keep away from detection by cybersecurity software program. In a single case, a trojan referred to as ZeroT, by infested Phrase docs hooked up to emails, was downloaded onto victims’ machines. Nonetheless, that’s not probably the most fascinating half. What’s fascinating is that it additionally downloaded a variant of the PlugX RAT (aka Korplug) — utilizing steganography to extract malware from an picture of Britney Spears.
In different phrases, If you’re protected against trojans like ZeroT, then you do not want to care as a lot about its use of steganography.
Lastly, any exploit code that’s extracted from photographs relies on vulnerabilities being current for profitable exploitation. In case your techniques are already patched, there isn’t a probability for the exploit to work; therefore, it’s a good suggestion to all the time maintain your cyber-protection, apps, and working techniques updated. Exploitation by exploit kits might be averted by working totally patched software program and utilizing a dependable, up to date safety resolution.
The identical cybersecurity guidelines apply as all the time — and consciousness is step one towards a extra cyber safe life.
Over the previous six months the engineering workforce at Rockset has totally built-in similarity indexes into its search and analytics database.
Indexing has at all times been on the forefront of Rockset’s expertise. Rockset constructed a Converged Index which incorporates parts of a search index, columnar retailer, row retailer and now a similarity index that may scale to billions of vectors and terabytes of knowledge. We’ve architected these indexes to help real-time updates in order that streaming information will be made accessible for search in lower than 200 milliseconds.
Earlier this yr, Rockset launched a brand new cloud structure with compute-storage and compute-compute separation. Consequently, indexing of newly ingested vectors and metadata doesn’t negatively impression search efficiency. Customers can constantly stream and index vectors totally remoted from search. This structure is advantageous for streaming information and likewise similarity indexing as these are resource-intensive operations.
What we’ve additionally seen is that vector search is just not on an island of its personal. Many functions apply filters to vector search utilizing textual content, geo, time collection information and extra. Rockset makes hybrid search as straightforward as a SQL WHERE clause. Rockset has exploited the ability of the search index with an built-in SQL engine so your queries are at all times executed effectively.
On this weblog, we’ll dig into how Rockset has totally built-in vector search into its search and analytics database. We’ll describe how Rockset has architected its resolution for native SQL, real-time updates and compute-compute separation.
Watch the tech speak on How We Constructed Vector Search within the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they constructed a distributed similarity index utilizing FAISS-IVF that’s memory-efficient and helps instant insertion and recall.
FAISS-IVF at Rockset
Whereas Rockset is algorithm agnostic in its implementation of similarity indexing, for the preliminary implementation we leveraged FAISS-IVF because it’s broadly used, effectively documented and helps updates.
There are a number of strategies to indexing vectors together with constructing a graph, tree information construction and inverted file construction. Tree and graph constructions take an extended time to construct, making them computationally costly and time consuming to help use instances with ceaselessly updating vectors. The inverted file strategy is effectively appreciated due to its quick indexing time and search efficiency.
Whereas the FAISS library is open sourced and will be leveraged as a standalone index, customers want a database to handle and scale vector search. That’s the place Rockset is available in as a result of it has solved database challenges together with question optimization, multi-tenancy, sharding, consistency and extra that customers want when scaling vector search functions.
Implementation of FAISS-IVF at Rockset
As Rockset is designed for scale, it builds a distributed FAISS similarity index that’s memory-efficient and helps instant insertion and recall.
Utilizing a DDL command, a person creates a similarity index on any vector area in a Rockset assortment. Underneath the hood, the inverted file indexing algorithm partitions the vector house into Voronoi cells and assigns every partition a centroid, or the purpose which falls within the heart of the partition. Vectors are then assigned to a partition, or cell, primarily based on which centroid they’re closest to.
CREATE SIMILARITY INDEX vg_ann_index
ON FIELD confluent_webinar.video_game_embeddings:embedding
DIMENSION 1536 as 'faiss::IVF256,Flat';
An instance of the DDL command used to create a similarity index in Rockset.
FAISS assigns vectors to Voronoi cells. Every cell is outlined by a centroid.
On the time of similarity index creation, Rockset builds a posting listing of the centroids and their identifiers that’s saved in reminiscence. Every report within the assortment can also be listed and extra fields are added to every report to retailer the closest centroid and the residual, the offset or distance from the closest centroid. The gathering is saved on SSDs for efficiency and cloud object storage for sturdiness, providing higher value efficiency than in-memory vector database options. As new data are added, their nearest centroids and residuals are computed and saved.
FAISS assigns vectors to Voronoi cells. Every cell is outlined by a centroid.
With Rockset’s Converged Index, vector search can leverage each the similarity and search index in parallel. When operating a search, Rockset’s question optimizer will get the closest centroids to the goal embedding from FAISS. Rockset’s question optimizer then searches throughout the centroids utilizing the search index to return the outcome.
Rockset additionally provides flexibility to the person to commerce off between recall and velocity for his or her AI utility. At similarity index creation time, the person can decide the variety of centroids, with extra centroids resulting in sooner search but additionally elevated indexing time. At question time, the person can even choose the variety of probes, or the variety of cells to go looking, buying and selling off between velocity and accuracy of search.
Rockset’s implementation minimizes the quantity of knowledge saved in reminiscence, limiting it to a posting listing, and leverages the similarity index and search index for efficiency.
Construct apps with real-time updates
One of many identified onerous challenges with vector search is dealing with inserts, updates and deletions. That’s as a result of vector indexes are rigorously organized for quick lookups and any try and replace them with new vectors will quickly deteriorate the quick lookup properties.
Rockset helps streaming updates to metadata and vectors in an environment friendly approach. Rockset is constructed on RocksDB, an open-source embedded storage engine which is designed for mutability and was constructed by the workforce behind Rockset at Meta.
Utilizing RocksDB beneath the hood permits Rockset to help field-level mutations, so an replace to the vector on a person report will set off a question to FAISS to generate the brand new centroid and residual. Rockset will then replace solely the values of the centroid and the residual for an up to date vector area. This ensures that new or up to date vectors are queryable inside ~200 milliseconds.
Separation of indexing and search
Rockset’s compute-compute separation ensures that the continual streaming and indexing of vectors won’t have an effect on search efficiency. In Rockset’s structure, a digital occasion, cluster of compute nodes, can be utilized to ingest and index information whereas different digital cases can be utilized for querying. A number of digital cases can concurrently entry the identical dataset, eliminating the necessity for a number of replicas of knowledge.
Compute-compute separation makes it doable for Rockset to help concurrent indexing and search. In many different vector databases, you can’t carry out reads and writes in parallel so you might be compelled to batch load information throughout off-hours to make sure the constant search efficiency of your utility.
Compute-compute separation additionally ensures that when similarity indexes should be periodically retrained to maintain the recall excessive that there is no such thing as a interference with search efficiency. It’s well-known that periodically retraining the index will be computationally costly. In lots of methods, together with in Elasticsearch, the reindexing and search operations occur on the identical cluster. This introduces the potential for indexing to negatively intervene with the search efficiency of the applying.
With compute-compute separation, Rockset avoids the problem of indexing impacting seek for predictable efficiency at any scale.
Hybrid search as straightforward as a SQL WHERE clause
Many vector databases provide restricted help for hybrid search or metadata filtering and prohibit the forms of fields, updates to metadata and the scale of metadata. Being constructed for search and analytics, Rockset treats metadata as a first-class citizen and helps paperwork as much as 40MB in dimension.
The rationale that many new vector databases restrict metadata is that filtering information extremely rapidly is a really onerous drawback. If you got the question, “Give me 5 nearest neighbors the place ?” you would want to have the ability to weigh the completely different filters, their selectivity after which reorder, plan and optimize the search. This can be a very onerous drawback however one which search and analytics databases, like Rockset, have spent a number of time, years even, fixing with a cost-based optimizer.
As a person, you may sign to Rockset that you’re open to an approximate nearest neighbor search and buying and selling off some precision for velocity within the search question utilizing approx_dot_product or approx_euclidean_dist.
WITH dune_embedding AS (
SELECT embedding
FROM commons.book_catalogue_embeddings catalogue
WHERE title="Dune"
LIMIT 1
)
SELECT title, writer, score, num_ratings, value,
APPROX_DOT_PRODUCT(dune_embedding.embedding, book_catalogue_embeddings.embedding) similarity,
description, language, book_format, page_count, liked_percent
FROM commons.book_catalogue_embeddings CROSS JOIN dune_embedding
WHERE score IS NOT NULL
AND book_catalogue_embeddings.embedding IS NOT NULL
AND writer != 'Frank Herbert'
AND score > 4.0
ORDER BY similarity DESC
LIMIT 30
A question with approx_dot_product which is an approximate measure of how carefully two vectors align.
Rockset makes use of the search index for filtering by metadata and proscribing the search to the closest centroids. This system is known as single-stage filtering and contrasts with two-step filtering together with pre-filtering and post-filtering that may induce latency.
Scale vector search within the cloud
At Rockset, we’ve spent years constructing a search and analytics database for scale. It’s been designed from the bottom up for the cloud with useful resource isolation that’s essential when constructing real-time functions or functions that run 24×7. On buyer workloads, Rockset has scaled to 20,000 QPS whereas sustaining a P50 information latency of 10 milliseconds.
Consequently, we see firms already utilizing vector seek for at-scale, manufacturing functions. JetBlue, the info chief within the airways business, makes use of Rockset as its vector search database for making operational selections round flights, crew and passengers utilizing LLM-based chatbots. Whatnot, the quickest rising market within the US, makes use of Rockset for powering AI-recommendations on its stay public sale platform.
If you’re constructing an AI utility, we invite you to begin a free trial of Rockset or study extra about our expertise in your use case in a product demo.
Watch the tech speak on How We Constructed Vector Search within the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they constructed a distributed similarity index utilizing FAISS-IVF that’s memory-efficient and helps instant insertion and recall.
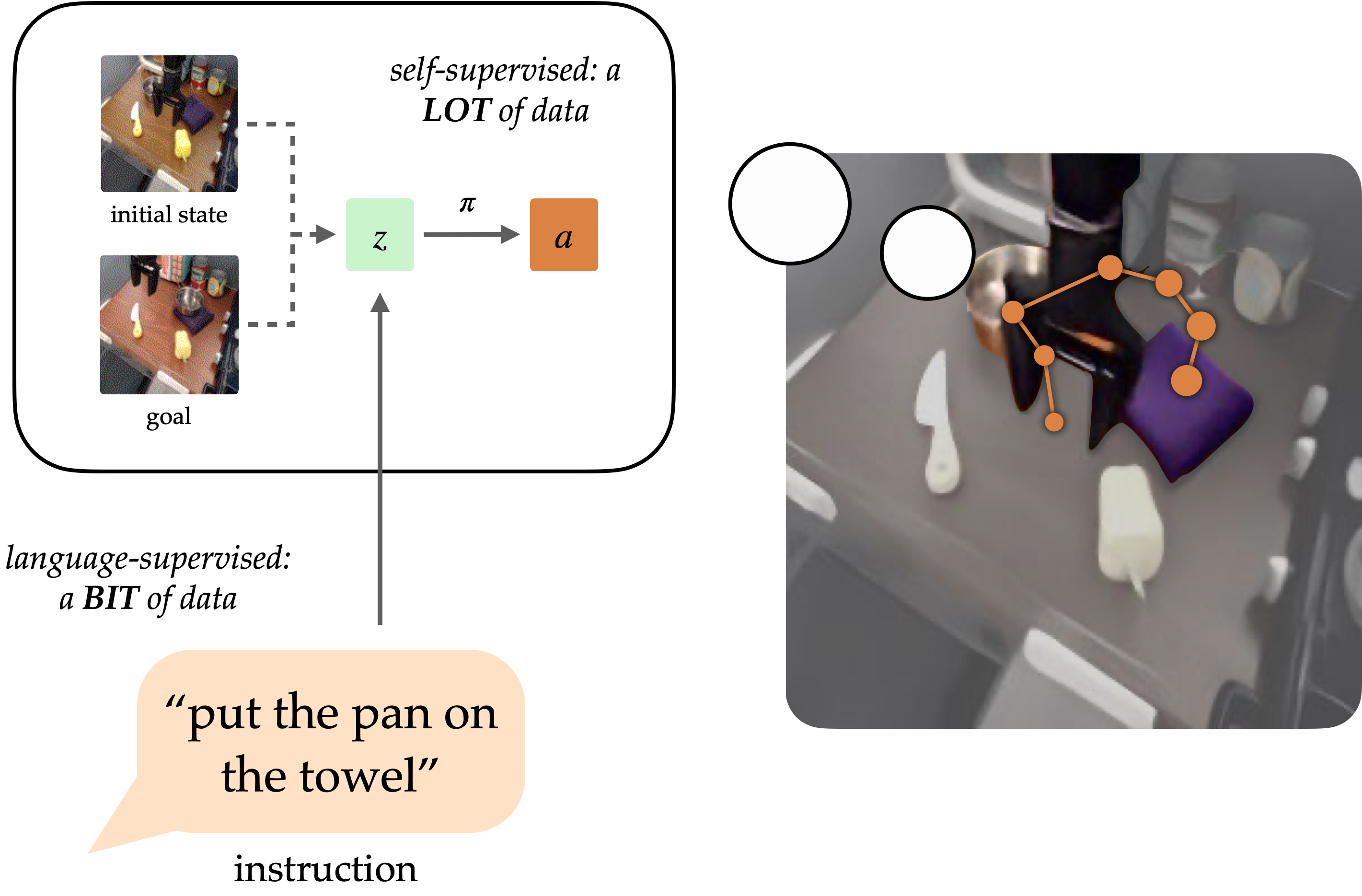
A longstanding objective of the sphere of robotic studying has been to create generalist brokers that may carry out duties for people. Pure language has the potential to be an easy-to-use interface for people to specify arbitrary duties, however it’s tough to coach robots to comply with language directions. Approaches like language-conditioned behavioral cloning (LCBC) prepare insurance policies to instantly imitate knowledgeable actions conditioned on language, however require people to annotate all coaching trajectories and generalize poorly throughout scenes and behaviors. In the meantime, current goal-conditioned approaches carry out significantly better at normal manipulation duties, however don’t allow simple activity specification for human operators. How can we reconcile the benefit of specifying duties by way of LCBC-like approaches with the efficiency enhancements of goal-conditioned studying?
Conceptually, an instruction-following robotic requires two capabilities. It must floor the language instruction within the bodily setting, after which have the ability to perform a sequence of actions to finish the supposed activity. These capabilities don’t must be realized end-to-end from human-annotated trajectories alone, however can as an alternative be realized individually from the suitable information sources. Imaginative and prescient-language information from non-robot sources might help be taught language grounding with generalization to numerous directions and visible scenes. In the meantime, unlabeled robotic trajectories can be utilized to coach a robotic to succeed in particular objective states, even when they don’t seem to be related to language directions.
Conditioning on visible targets (i.e. objective photos) supplies complementary advantages for coverage studying. As a type of activity specification, targets are fascinating for scaling as a result of they are often freely generated hindsight relabeling (any state reached alongside a trajectory could be a objective). This enables insurance policies to be educated through goal-conditioned behavioral cloning (GCBC) on giant quantities of unannotated and unstructured trajectory information, together with information collected autonomously by the robotic itself. Objectives are additionally simpler to floor since, as photos, they are often instantly in contrast pixel-by-pixel with different states.
Nonetheless, targets are much less intuitive for human customers than pure language. Normally, it’s simpler for a consumer to explain the duty they need carried out than it’s to offer a objective picture, which might doubtless require performing the duty anyhow to generate the picture. By exposing a language interface for goal-conditioned insurance policies, we are able to mix the strengths of each goal- and language- activity specification to allow generalist robots that may be simply commanded. Our methodology, mentioned beneath, exposes such an interface to generalize to numerous directions and scenes utilizing vision-language information, and enhance its bodily expertise by digesting giant unstructured robotic datasets.
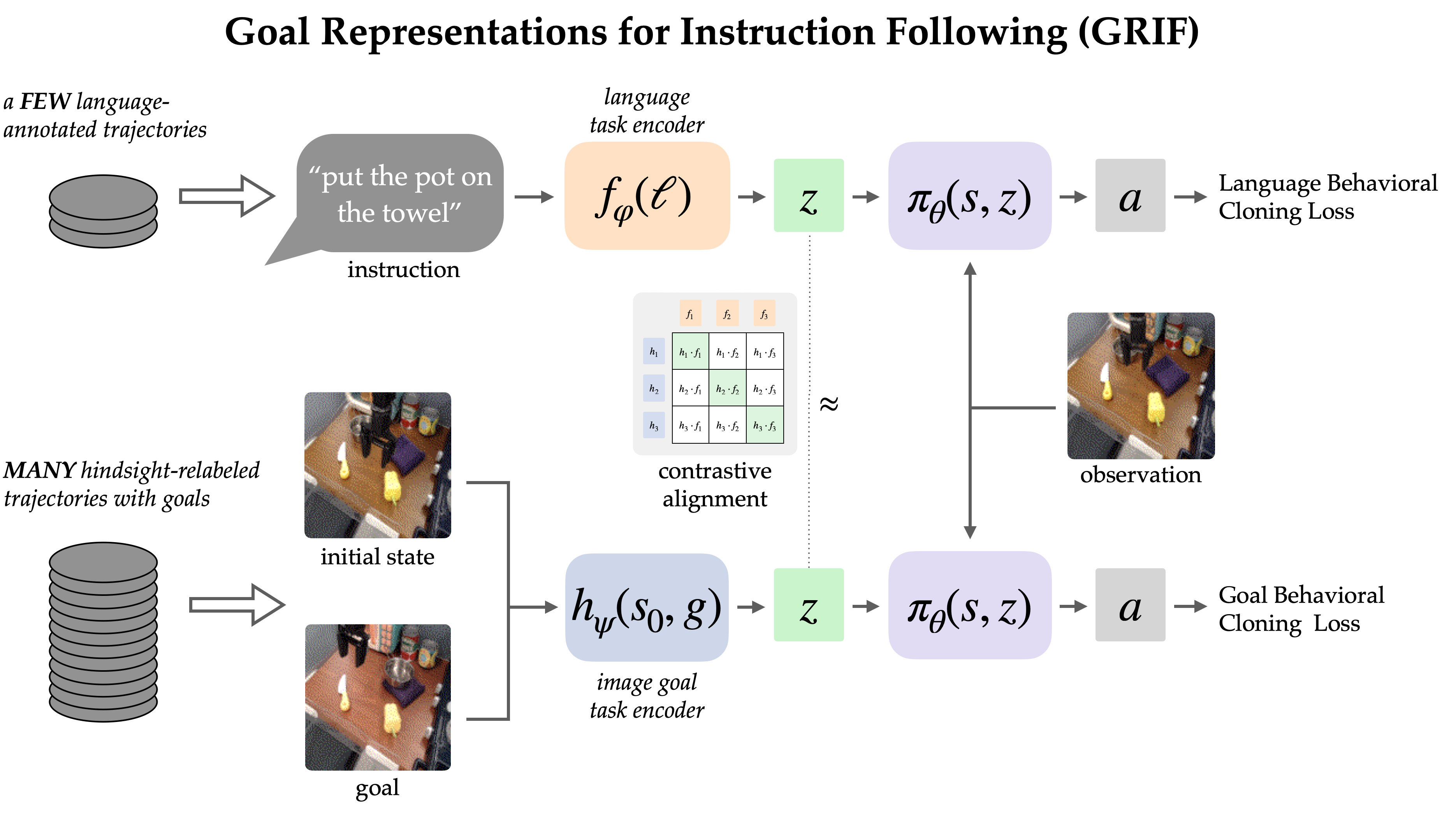
Purpose representations for instruction following
The GRIF mannequin consists of a language encoder, a objective encoder, and a coverage community. The encoders respectively map language directions and objective photos right into a shared activity illustration area, which situations the coverage community when predicting actions. The mannequin can successfully be conditioned on both language directions or objective photos to foretell actions, however we’re primarily utilizing goal-conditioned coaching as a approach to enhance the language-conditioned use case.
Our method, Purpose Representations for Instruction Following (GRIF), collectively trains a language- and a goal- conditioned coverage with aligned activity representations. Our key perception is that these representations, aligned throughout language and objective modalities, allow us to successfully mix the advantages of goal-conditioned studying with a language-conditioned coverage. The realized insurance policies are then capable of generalize throughout language and scenes after coaching on largely unlabeled demonstration information.
We educated GRIF on a model of the Bridge-v2 dataset containing 7k labeled demonstration trajectories and 47k unlabeled ones inside a kitchen manipulation setting. Since all of the trajectories on this dataset needed to be manually annotated by people, with the ability to instantly use the 47k trajectories with out annotation considerably improves effectivity.
To be taught from each forms of information, GRIF is educated collectively with language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC). The labeled dataset incorporates each language and objective activity specs, so we use it to oversee each the language- and goal-conditioned predictions (i.e. LCBC and GCBC). The unlabeled dataset incorporates solely targets and is used for GCBC. The distinction between LCBC and GCBC is only a matter of choosing the duty illustration from the corresponding encoder, which is handed right into a shared coverage community to foretell actions.
By sharing the coverage community, we are able to anticipate some enchancment from utilizing the unlabeled dataset for goal-conditioned coaching. Nonetheless,GRIF permits a lot stronger switch between the 2 modalities by recognizing that some language directions and objective photos specify the identical conduct. Particularly, we exploit this construction by requiring that language- and goal- representations be related for a similar semantic activity. Assuming this construction holds, unlabeled information can even profit the language-conditioned coverage for the reason that objective illustration approximates that of the lacking instruction.
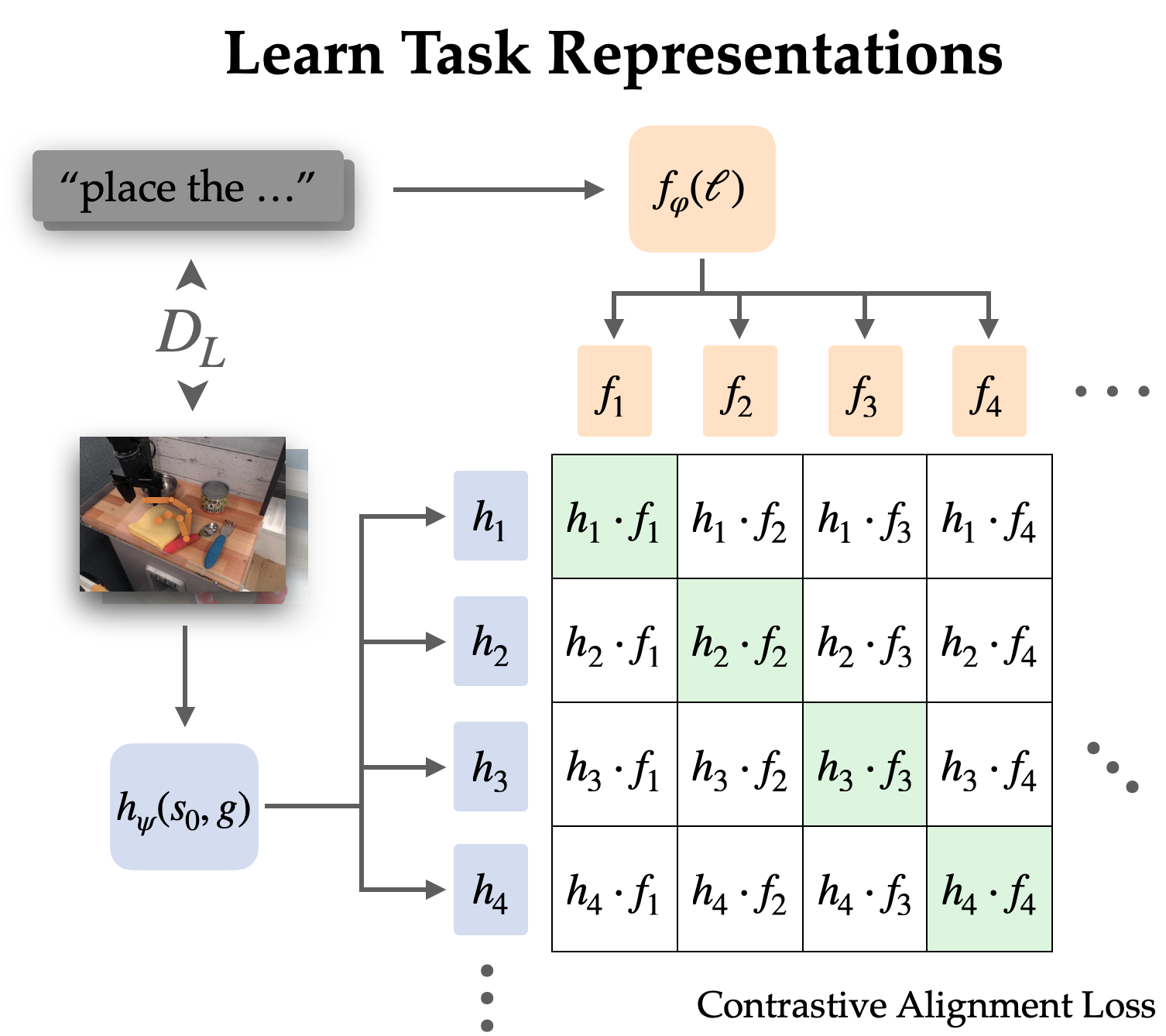
Alignment by way of contrastive studying
We explicitly align representations between goal-conditioned and language-conditioned duties on the labeled dataset by way of contrastive studying.
Since language typically describes relative change, we select to align representations of state-goal pairs with the language instruction (versus simply objective with language). Empirically, this additionally makes the representations simpler to be taught since they’ll omit most data within the photos and give attention to the change from state to objective.
We be taught this alignment construction by way of an infoNCE goal on directions and pictures from the labeled dataset. We prepare twin picture and textual content encoders by doing contrastive studying on matching pairs of language and objective representations. The target encourages excessive similarity between representations of the identical activity and low similarity for others, the place the unfavourable examples are sampled from different trajectories.
When utilizing naive unfavourable sampling (uniform from the remainder of the dataset), the realized representations typically ignored the precise activity and easily aligned directions and targets that referred to the identical scenes. To make use of the coverage in the true world, it isn’t very helpful to affiliate language with a scene; quite we want it to disambiguate between completely different duties in the identical scene. Thus, we use a tough unfavourable sampling technique, the place as much as half the negatives are sampled from completely different trajectories in the identical scene.
Naturally, this contrastive studying setup teases at pre-trained vision-language fashions like CLIP. They exhibit efficient zero-shot and few-shot generalization functionality for vision-language duties, and provide a technique to incorporate data from internet-scale pre-training. Nonetheless, most vision-language fashions are designed for aligning a single static picture with its caption with out the power to grasp adjustments within the setting, and so they carry out poorly when having to concentrate to a single object in cluttered scenes.
To deal with these points, we devise a mechanism to accommodate and fine-tune CLIP for aligning activity representations. We modify the CLIP structure in order that it may function on a pair of photos mixed with early fusion (stacked channel-wise). This seems to be a succesful initialization for encoding pairs of state and objective photos, and one which is especially good at preserving the pre-training advantages from CLIP.
Robotic coverage outcomes
For our fundamental outcome, we consider the GRIF coverage in the true world on 15 duties throughout 3 scenes. The directions are chosen to be a mixture of ones which might be well-represented within the coaching information and novel ones that require a point of compositional generalization. One of many scenes additionally options an unseen mixture of objects.
We examine GRIF in opposition to plain LCBC and stronger baselines impressed by prior work like LangLfP and BC-Z. LLfP corresponds to collectively coaching with LCBC and GCBC. BC-Z is an adaptation of the namesake methodology to our setting, the place we prepare on LCBC, GCBC, and a easy alignment time period. It optimizes the cosine distance loss between the duty representations and doesn’t use image-language pre-training.
The insurance policies had been inclined to 2 fundamental failure modes. They’ll fail to grasp the language instruction, which leads to them trying one other activity or performing no helpful actions in any respect. When language grounding just isn’t sturdy, insurance policies may even begin an unintended activity after having completed the suitable activity, for the reason that unique instruction is out of context.
Examples of grounding failures
“put the mushroom within the metallic pot”
“put the spoon on the towel”
“put the yellow bell pepper on the fabric”
“put the yellow bell pepper on the fabric”
The opposite failure mode is failing to govern objects. This may be as a result of lacking a grasp, transferring imprecisely, or releasing objects on the incorrect time. We word that these will not be inherent shortcomings of the robotic setup, as a GCBC coverage educated on your entire dataset can constantly reach manipulation. Somewhat, this failure mode typically signifies an ineffectiveness in leveraging goal-conditioned information.
Examples of manipulation failures
“transfer the bell pepper to the left of the desk”
“put the bell pepper within the pan”
“transfer the towel subsequent to the microwave”
Evaluating the baselines, they every suffered from these two failure modes to completely different extents. LCBC depends solely on the small labeled trajectory dataset, and its poor manipulation functionality prevents it from finishing any duties. LLfP collectively trains the coverage on labeled and unlabeled information and reveals considerably improved manipulation functionality from LCBC. It achieves cheap success charges for frequent directions, however fails to floor extra advanced directions. BC-Z’s alignment technique additionally improves manipulation functionality, doubtless as a result of alignment improves the switch between modalities. Nonetheless, with out exterior vision-language information sources, it nonetheless struggles to generalize to new directions.
GRIF reveals one of the best generalization whereas additionally having robust manipulation capabilities. It is ready to floor the language directions and perform the duty even when many distinct duties are potential within the scene. We present some rollouts and the corresponding directions beneath.
Coverage Rollouts from GRIF
“transfer the pan to the entrance”
“put the bell pepper within the pan”
“put the knife on the purple fabric”
“put the spoon on the towel”
Conclusion
GRIF permits a robotic to make the most of giant quantities of unlabeled trajectory information to be taught goal-conditioned insurance policies, whereas offering a “language interface” to those insurance policies through aligned language-goal activity representations. In distinction to prior language-image alignment strategies, our representations align adjustments in state to language, which we present results in vital enhancements over customary CLIP-style image-language alignment goals. Our experiments exhibit that our method can successfully leverage unlabeled robotic trajectories, with giant enhancements in efficiency over baselines and strategies that solely use the language-annotated information
Our methodology has plenty of limitations that might be addressed in future work. GRIF just isn’t well-suited for duties the place directions say extra about find out how to do the duty than what to do (e.g., “pour the water slowly”)—such qualitative directions may require different forms of alignment losses that take into account the intermediate steps of activity execution. GRIF additionally assumes that each one language grounding comes from the portion of our dataset that’s absolutely annotated or a pre-trained VLM. An thrilling course for future work could be to increase our alignment loss to make the most of human video information to be taught wealthy semantics from Web-scale information. Such an method might then use this information to enhance grounding on language outdoors the robotic dataset and allow broadly generalizable robotic insurance policies that may comply with consumer directions.
This submit relies on the next paper:
BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.
BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.