{kind=link}

Massive language fashions (LLMs) constructed utilizing transformer architectures closely rely on pre-training with large-scale information to foretell sequential tokens. This complicated and resource-intensive course of requires huge computational infrastructure and well-constructed information pipelines. The rising demand for environment friendly and accessible LLMs has led researchers to discover strategies that steadiness useful resource use and efficiency, emphasizing attaining aggressive outcomes with out counting on industry-scale assets.
Creating LLMs is full of challenges, particularly relating to computation and information effectivity. Pre-training fashions with billions of parameters demand superior strategies and substantial infrastructure. Excessive-quality information and sturdy coaching strategies are essential, as fashions face gradient instability and efficiency degradation throughout coaching. Open-source LLMs usually battle to match proprietary counterparts due to restricted entry to computational energy and high-caliber datasets. Subsequently, the problem lies in creating environment friendly and high-performing fashions, enabling smaller analysis teams to take part actively in advancing AI expertise. Fixing this drawback necessitates innovation in information dealing with, coaching stabilization, and architectural design.
Current analysis in LLM coaching emphasizes structured information pipelines, utilizing strategies like information cleansing, dynamic scheduling, and curriculum studying to enhance studying outcomes. Nonetheless, stability stays a persistent concern. Massive-scale coaching is vulnerable to gradient explosions, loss spikes, and different technical difficulties, requiring cautious optimization. Coaching long-context fashions introduce further complexity as consideration mechanisms’ computational calls for develop quadratically with sequence size. Current approaches like superior optimizers, initialization methods, and artificial information technology assist alleviate these points however usually fall quick when scaled to full-sized fashions. The necessity for scalable, steady, and environment friendly strategies in LLM coaching is extra pressing than ever.
Researchers on the Gaoling College of Synthetic Intelligence, Renmin College of China, developed YuLan-Mini. With 2.42 billion parameters, this language mannequin improves computational effectivity and efficiency with data-efficient strategies. By leveraging publicly out there information and specializing in data-efficient coaching strategies, YuLan-Mini achieves exceptional efficiency corresponding to bigger {industry} fashions.
YuLan-Mini’s structure incorporates a number of progressive components to reinforce coaching effectivity. Its decoder-only transformer design employs embedding tying to scale back parameter dimension and enhance coaching stability. The mannequin makes use of Rotary Positional Embedding (ROPE) to deal with lengthy contexts successfully, extending its context size to twenty-eight,672 tokens, an development over typical fashions. Different key options embrace SwiGLU activation features for higher information illustration and a fastidiously designed annealing technique that stabilizes coaching whereas maximizing studying effectivity. Artificial information was vital, supplementing the 1.08 trillion tokens of coaching information sourced from open internet pages, code repositories, and mathematical datasets. These options allow YuLan-Mini to ship sturdy efficiency with a restricted computing finances.
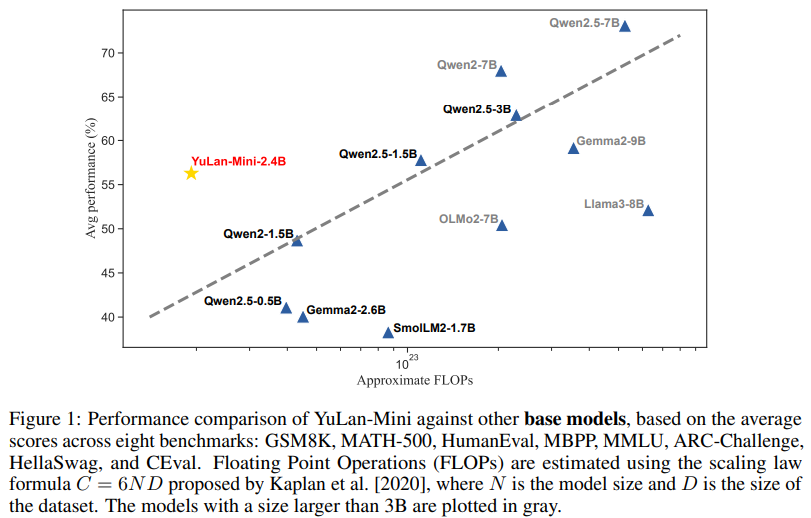
YuLan-Mini’s efficiency achieved scores of 64.00 on HumanEval in zero-shot eventualities, 37.80 on MATH-500 in four-shot settings, and 49.10 on MMLU in five-shot duties. These outcomes underscore its aggressive edge, because the mannequin’s efficiency is corresponding to a lot bigger and resource-intensive counterparts. The progressive context size extension to 28K tokens allowed YuLan-Mini to excel in long-text eventualities whereas nonetheless sustaining excessive accuracy in short-text duties. This twin functionality units it other than many current fashions, which regularly sacrifice one for the opposite.

Key takeaways from the analysis embrace:
- Utilizing a meticulously designed information pipeline, YuLan-Mini reduces reliance on large datasets whereas making certain high-quality studying.
- Strategies like systematic optimization and annealing stop frequent points like loss spikes and gradient explosions.
- Extending the context size to twenty-eight,672 tokens enhances the mannequin’s applicability to complicated, long-text duties.
- Regardless of its modest computational necessities, YuLan-Mini achieves outcomes corresponding to these of a lot bigger fashions, demonstrating the effectiveness of its design.
- The mixing of artificial information improves coaching outcomes and reduces the necessity for proprietary datasets.

In conclusion, YuLan-Mini is a superb new addition to evolving environment friendly LLMs. Its capability to ship excessive efficiency with restricted assets addresses vital boundaries to AI accessibility. The analysis group’s deal with progressive strategies, from information effectivity to coaching stability, highlights the potential for smaller-scale analysis to contribute to the sector considerably. With simply 1.08T tokens, YuLan-Mini units a benchmark for resource-efficient LLMs.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.