{kind=link}


(Who Is Danny/Shutterstock)
The launch of ChatGPT in November 2022 was a watershed second in pure language processing (NLP), because it showcased the startling effectiveness of the transformer structure for understanding and producing textual information. Now we’re seeing one thing comparable occurring within the discipline of pc imaginative and prescient with the rise of pre-trained giant imaginative and prescient fashions. However when will these fashions acquire widespread acceptance for visible information?
Since round 2010, the state-of-the-art when it got here to pc imaginative and prescient was the convolutional neural community (CNN), which is a sort of deep studying structure modeled after how neurons work together in organic brains. CNN frameworks, reminiscent of ResNet, powered pc imaginative and prescient duties reminiscent of picture recognition and classification, and located some use in business.
Over the previous decade or so, one other class of fashions, often called diffusion fashions, have gained traction in pc imaginative and prescient circles. Diffusion fashions are a sort of generative neural community that use a diffusion course of to mannequin the distribution of knowledge, which might then be used to generate information in an identical method. Widespread diffusion fashions embody Secure Diffusion, an open picture era mannequin pre-trained on 2.3 billion English-captioned pictures from the web, which is ready to generate pictures based mostly on textual content enter.
Wanted Consideration
A serious architectural shift occurred in 2017, when Google first proposed the transformer structure with its paper “Consideration Is All You Want.” The transformer structure relies on a basically completely different strategy. It dispenses the convolutions and recurrence CNNs and in recurrent neural networks RNNs (used primarily for NLP) and depends solely on one thing known as the eye mechanism, whereby the relative significance of every element in a sequence is calculated relative to the opposite parts in a sequence.

A neural web (Pdusit/Shutterstock)
This strategy proved helpful in NLP use circumstances, the place it was first utilized by the Google researchers, and it led on to the creation of enormous language fashions (LLMs), reminiscent of OpenAI’s Generative Pre-trained Tranformer (GPT), which ignited the sphere of generative AI. However it seems that the core component of the transformer structure–the eye mechanism–isn’t restricted to NLP. Simply as phrases might be encoded into tokens and measured for relative significance via the eye mechanism, pixels in a picture may also be encoded into tokens and their relative worth calculated.
Tinkering with transformers for pc imaginative and prescient began in 2019, when researchers first proposed utilizing the transformer structure for pc imaginative and prescient duties. Since then, pc imaginative and prescient researchers have been bettering the sphere of LVMs. Google itself has open sourced ViT, a imaginative and prescient transformer mannequin, whereas Meta has DINOv2. OpenAI has additionally developed transformer-based LVMs, reminiscent of CLIP, and has additionally included image-generation with its GPT-4v. LandingAI, which was based by Google Mind co-founder Andrew Ng, additionally makes use of LVMs for industrial use circumstances. Multi-modal fashions that may deal with each textual content and picture enter–and generate each textual content and imaginative and prescient output–can be found from a number of suppliers.
Transformer-based LVMs have benefits and drawbacks in comparison with different pc imaginative and prescient fashions, together with diffusion fashions and conventional CNNs. On the draw back, LVMs are extra information hungry than CNNs. In the event you don’t have a major variety of pictures to coach on (LandingAI recommends a minimal of 100,000 unlabeled pictures), then it will not be for you.
Alternatively, the eye mechanism offers LVMs a elementary benefit over CNNs: they’ve a worldwide context baked in from the very starting, resulting in greater accuracy charges. As a substitute of attempting to establish a picture beginning with a single pixel and zooming out, as a CNN works, an LVM “slowly brings the entire fuzzy picture into focus,” writes Stephen Ornes in a Quanta Journal article.
In brief, the provision of pre-trained LVMs that present superb efficiency out-of-the-box with no guide coaching has the potential to be simply as disruptive for pc imaginative and prescient as pre-trained LLMs have for NLP workloads.
LVMs on the Cusp
The rise of LVMs is thrilling of us like Srinivas Kuppa, the chief technique and product officer for SymphonyAI, a longtime supplier of AI options for quite a lot of industries.
In response to Kuppa, we’re on the cusp of massive adjustments within the pc imaginative and prescient market, due to LVMs. “We’re beginning to see that the massive imaginative and prescient fashions are actually coming in the way in which the massive language fashions have are available in,” Kuppa mentioned.
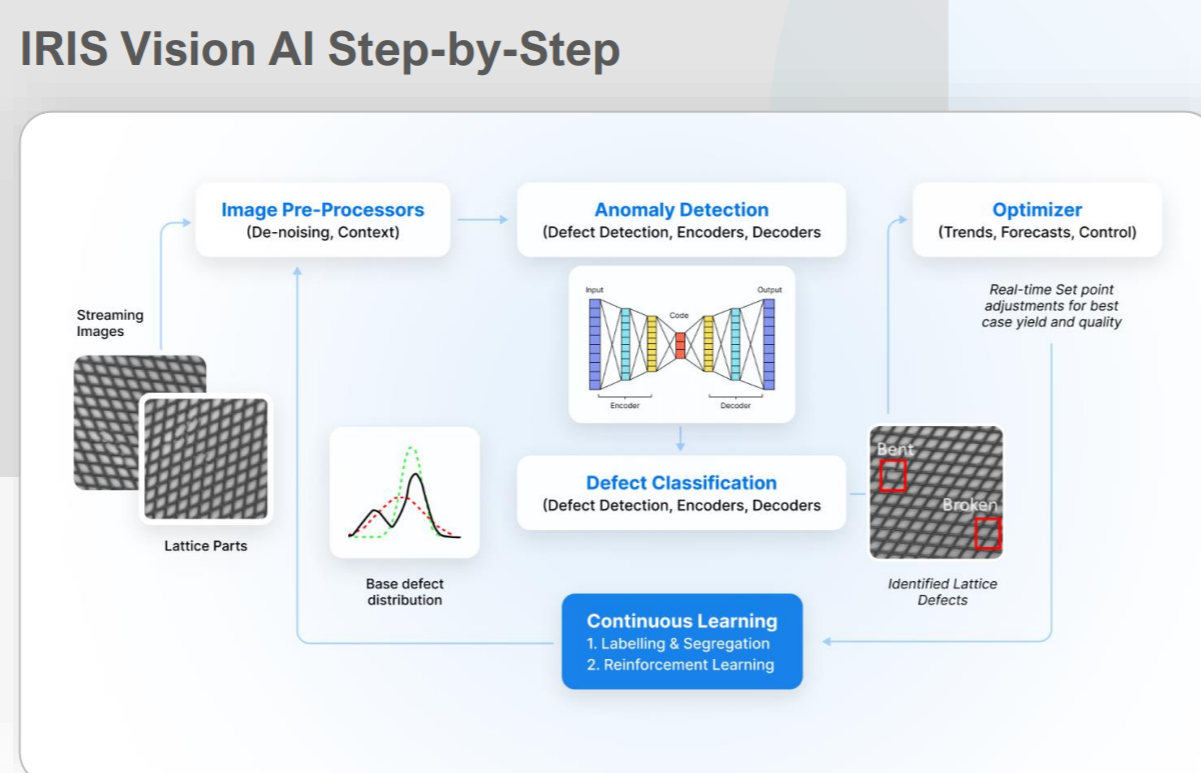
SymphonyAI’s Iris software program helps implement LVMs for purchasers (Picture courtesy SymphonyAI)
The massive benefit with the LVMs is that they’re already (principally) educated, eliminating the necessity for purchasers to start out from scratch with mannequin coaching, he mentioned.
“The fantastic thing about these giant imaginative and prescient fashions, just like giant language fashions, is it’s pre-trained to a bigger extent,” Kuppa advised BigDATAwire. “The most important problem for AI normally and positively for imaginative and prescient fashions is when you get to the client, you’ve bought to get a complete lot of knowledge from the client to coach the mannequin.”
SymphonyAI makes use of quite a lot of open supply LVMs in buyer engagements throughout manufacturing, safety, and retail settings, most of that are open supply and obtainable on Huggingface. It makes use of Pixel, a 12-billion parameter mannequin from Mistral, in addition to LLaVA, an open supply multi-modal mannequin.
Whereas pre-trained LVMs work effectively out of the field throughout quite a lot of use circumstances, SymphonyAI usually fine-tune the fashions utilizing its personal proprietary picture information, which improves the efficiency for purchasers’ particular use case.
“We take that basis mannequin and we high quality tune it additional earlier than we hand it over to a buyer,” Kuppa mentioned. “So as soon as we optimize that model of it, when it goes to our prospects, that’s a number of occasions higher. And it improves the time to worth for the client [so they don’t] must work with their very own pictures, label them, and fear about them earlier than they begin utilizing it.”
For instance, SymphonyAI’s lengthy report of serving the discrete manufacturing area has enabled it to acquire many pictures of widespread items of apparatus, reminiscent of boilers. The corporate is ready to fine-tune LVMs utilizing these pictures. The mannequin is then deployed as a part of its Iris providing to acknowledge when the gear is broken or when upkeep has not been accomplished.
“We’re put collectively by a complete lot of acquisitions which have gone again so far as 50 or 60 years,” Kuppa mentioned of SymphonyAI, which itself was formally based in 2017 and is backed with a $1 billion funding by Romesh Wadhwani, an Indian-American businessman. “So over time, we have now collected numerous information the proper means. What we did since generative AI exploded is to have a look at what sort of information we have now after which anonymize the info to the extent potential, after which use that as a foundation to coach this mannequin.”
LVMs In Motion
SymphonyAI has developed LVMs for one of many largest meals producers on the earth. It’s additionally working with distributors and retailers to implement LVMs to allow autonomous autos in warehouse and optimize product placement on the cabinets, he mentioned.
“My hope is that the massive imaginative and prescient fashions will begin catching consideration and see accelerated development,” Kuppa mentioned. “I see sufficient fashions being obtainable on Huggingface. I’ve seen some fashions which can be obtainable on the market as open supply that we are able to leverage. However I feel there is a chance to develop [the use] fairly considerably.”

(Fotogrin/Shutterstock)
One of many limiting components of LVMs (in addition to needing to fine-tune them for particular use circumstances) is the {hardware} necessities. LVMs have billions of parameters, whereas CNNs like ResNet usually have solely tens of millions of parameters. That places strain on the native {hardware} wanted to run LVMs for inference.
For real-time decision-making, an LVM would require a substantial quantity of processing assets. In lots of circumstances, it should require connections to the cloud. The supply of various processor sorts, together with FPGAs, might assist, Kuppa mentioned, nevertheless it’s a present want nonetheless.
Whereas the usage of LVMs isn’t nice in the meanwhile, its footprint is rising. The variety of pilots and proofs of ideas (POCs) has grown significantly over the previous two years, and the chance is substantial.
“The time to worth has been shrunk due to the pre-trained mannequin, to allow them to actually begin seeing the worth of it and its end result a lot quicker with out a lot funding upfront,” Kuppa mentioned. “There are much more POCs and pilots occurring. However whether or not that interprets right into a extra enterprise stage adoption at scale, we have to nonetheless see how that goes.”
Associated Objects:
The Key to Pc Imaginative and prescient-Pushed AI Is a Strong Knowledge Infrastructure
Patterns of Progress: Andrew Ng Eyes a Revolution in Pc Imaginative and prescient
AI Can See. Can We Educate It To Really feel?