{kind=link}

A major problem in text-to-speech (TTS) techniques is the computational inefficiency of the Monotonic Alignment Search (MAS) algorithm, which is chargeable for estimating alignments between textual content and speech sequences. MAS faces excessive time complexity, notably when coping with massive inputs. The complexity is O(T×S), the place T is the textual content size and S is the speech illustration size. Because the enter measurement will increase, the computational burden turns into unmanageable, particularly when the algorithm is executed sequentially with out leveraging parallel processing. This inefficiency hinders its applicability in real-time and large-scale functions in TTS fashions. Subsequently, addressing this challenge is essential for enhancing the scalability and efficiency of TTS techniques, enabling quicker coaching and inference throughout numerous AI duties requiring sequence alignment.
Present strategies of implementing MAS are CPU-based and make the most of Cython to parallelize the batch dimension. Nevertheless, these strategies make use of nested loops for alignment calculations, which considerably enhance the computational burden for bigger datasets. Furthermore, the necessity for inter-device reminiscence transfers between the CPU and GPU introduces further delays, making these strategies inefficient for large-scale or real-time functions. Moreover, the max_neg_val used within the conventional strategies is about to -1e9, which is inadequate for stopping alignment mismatches, notably within the higher diagonal areas of the alignment matrix. The lack to totally exploit GPU parallelization is one other main limitation, as present strategies stay sure by the processing constraints of CPUs, leading to slower execution occasions because the enter measurement grows.
A group of researchers from Johns Hopkins College and Supertone Inc. suggest Tremendous-MAS, a novel answer that leverages Triton kernels and PyTorch JIT scripts to optimize MAS for GPU execution, eliminating nested loops and inter-device reminiscence transfers. By parallelizing the text-length dimension, this strategy considerably reduces the computational complexity. The introduction of a bigger max_neg_val (-1e32) mitigates alignment mismatches, enhancing total accuracy. Moreover, the in-place computation of log-likelihood values minimizes reminiscence allocation, additional streamlining the method. These enhancements make the algorithm way more environment friendly and scalable, notably for real-time TTS functions or different AI duties requiring large-scale sequence alignment.
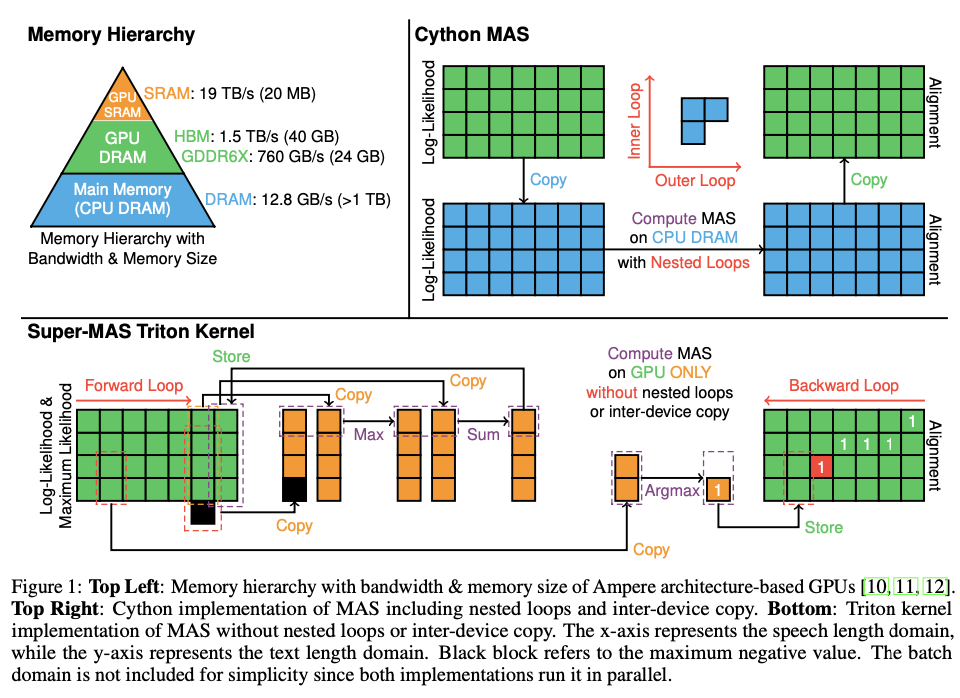
Tremendous-MAS is applied by vectorizing the text-length dimension utilizing Triton kernels, not like conventional strategies that parallelize the batch dimensions with Cython. This restructuring eliminates the nested loops that beforehand slowed down computation. The log-likelihood matrix is initialized, and alignments are calculated utilizing dynamic programming, with ahead and backward loops iterating over the matrix to compute and reconstruct the alignment paths. All the course of is executed on the GPU, avoiding the inefficiencies attributable to inter-device transfers between the CPU and GPU. A collection of checks have been performed utilizing log-likelihood tensors with a batch measurement of B=32, textual content size T, and speech size S=4T.
Tremendous-MAS achieves exceptional enhancements in execution pace, with the Triton kernel performing 19 to 72 occasions quicker than the Cython implementation, relying on the enter measurement. For example, with a textual content size of 1024, Tremendous-MAS completes its activity in 19.77 milliseconds, in comparison with 1299.56 milliseconds for Cython. These speedups are particularly pronounced as enter measurement will increase, confirming that Tremendous-MAS is extremely scalable and considerably extra environment friendly for dealing with massive datasets. It additionally outperforms PyTorch JIT variations, notably for bigger inputs, making it a really perfect selection for real-time functions in TTS techniques or different duties requiring environment friendly sequence alignment.
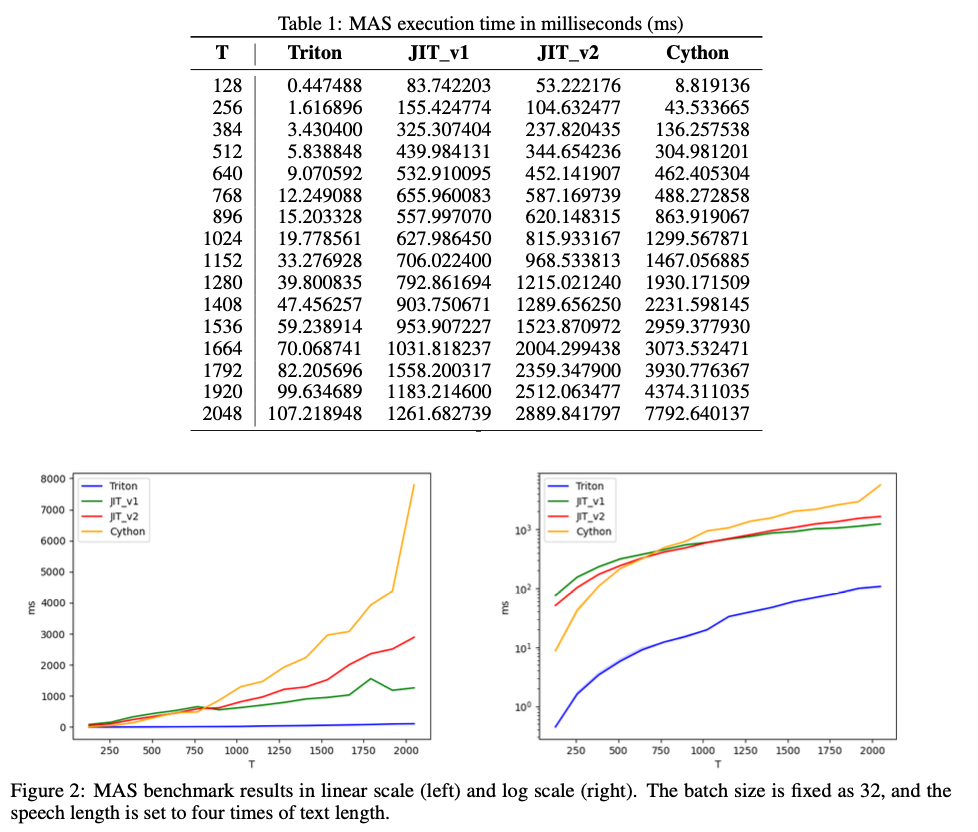
In conclusion, Tremendous-MAS presents a sophisticated answer to the computational challenges of Monotonic Alignment Search in TTS techniques, reaching substantial reductions in time complexity via GPU parallelization and reminiscence optimization. By eliminating the necessity for nested loops and inter-device transfers, it delivers a extremely environment friendly and scalable technique for sequence alignment duties, providing speedups of as much as 72 occasions in comparison with present approaches. This breakthrough allows quicker and extra correct processing, making it invaluable for real-time AI functions like TTS and past.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.