
Databases are important for storing and retrieving structured knowledge supporting enterprise intelligence, analysis, and enterprise functions. Querying databases usually requires SQL, which varies throughout methods and will be complicated. Whereas LLMs supply the potential for automating queries, most approaches depend on translating pure language to SQL, usually resulting in errors on account of syntax variations. A function-based API method is rising as a extra dependable various, enabling LLMs to work together with structured knowledge successfully throughout totally different database methods.
On this analysis, the issue addressed is bettering the accuracy and effectivity of LLM-driven database queries. Current text-to-SQL options usually wrestle with:
- Completely different database administration methods (DBMS) implement their very own SQL dialects, making it troublesome for LLMs to generalize throughout a number of platforms.
- Many real-world queries contain filtering, aggregations, and end result transformations, which present fashions don’t simply deal with.
- It’s essential to make sure that queries goal the proper database collections, particularly in situations involving multi-collection knowledge buildings.
- LLM efficiency in database querying varies primarily based on question complexity. Measuring effectiveness requires standardized analysis benchmarks.
LLM-based database querying largely is dependent upon text-to-SQL translation, the place fashions convert pure language into SQL queries. Benchmarks like WikiSQL, Spider, and BIRD measure accuracy primarily based on SQL technology however don’t consider broader interactions with structured databases. These strategies usually wrestle with search queries, property filters, and multi-collection routing. As database architectures turn into extra various, a extra versatile method is required—one which strikes past SQL dependency for question execution.
Researchers from Weaviate, Contextual AI, and Morningstar launched a structured function-calling method for LLMs to question databases with out counting on SQL. This methodology defines API capabilities for search, filtering, aggregation, and grouping, bettering accuracy and lowering text-to-SQL errors. They developed the DBGorilla benchmark to judge efficiency and examined eight LLMs, together with GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Professional. By eradicating SQL dependency, this method enhances flexibility, making database interactions extra dependable and scalable.
DBGorilla is an artificial dataset with 315 queries throughout 5 database schemas, every containing three associated collections. The dataset contains numeric, textual content, and boolean filters and aggregation capabilities like SUM, AVG, and COUNT. Efficiency is evaluated utilizing Precise Match accuracy, Summary Syntax Tree (AST) alignment, and assortment routing accuracy. DBGorilla assessments LLMs in a managed atmosphere, in contrast to conventional SQL-based benchmarks, making certain structured API queries exchange uncooked SQL instructions.
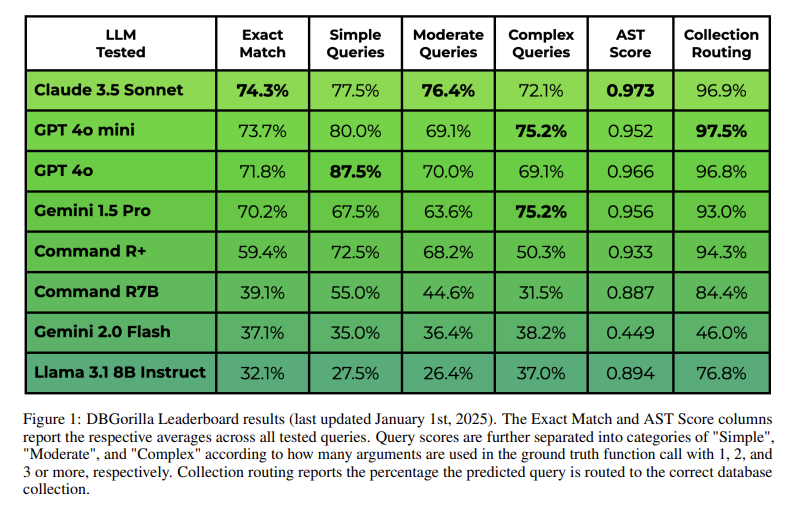
The research evaluated the efficiency of eight LLMs throughout three key metrics:
- Precise Match Rating
- AST Alignment
- Assortment Routing Accuracy
Claude 3.5 Sonnet achieved the best precise match rating of 74.3%, adopted by GPT-4o Mini at 73.7%, GPT-4o at 71.8%, and Gemini 1.5 Professional at 70.2%. Boolean property filters had been dealt with with the best accuracy, reaching 87.5%, whereas textual content property filters confirmed decrease accuracy, with fashions usually complicated them with search queries. Assortment routing accuracy was persistently excessive, with top-performing fashions attaining between 96% and 98% accuracy. When analyzing question complexity, GPT-4o achieved 87.5% accuracy for easy queries requiring just one argument, however efficiency declined to 72.1% for complicated queries involving a number of parameters.
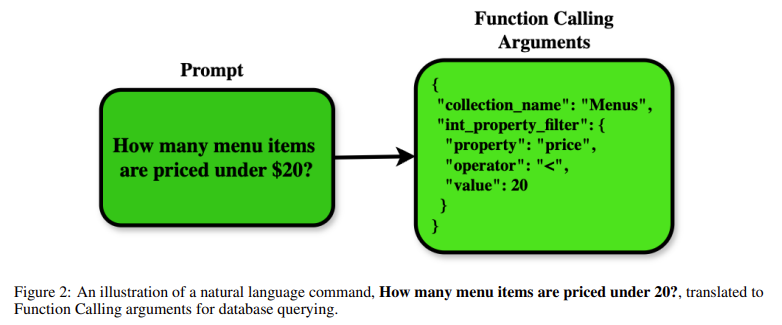
Researchers performed further experiments to judge the impression of various perform name configurations. Permitting LLMs to make parallel perform calls barely decreased accuracy, with an Precise Match rating of 71.2%. Splitting perform calls into particular person database collections had minimal impression, attaining a rating of 72.3%. Changing Operate Calling with structured response technology yielded related outcomes, with a 72.8% accuracy charge. Operate name variations impression efficiency barely, however structured querying stays persistently efficient throughout totally different configurations.
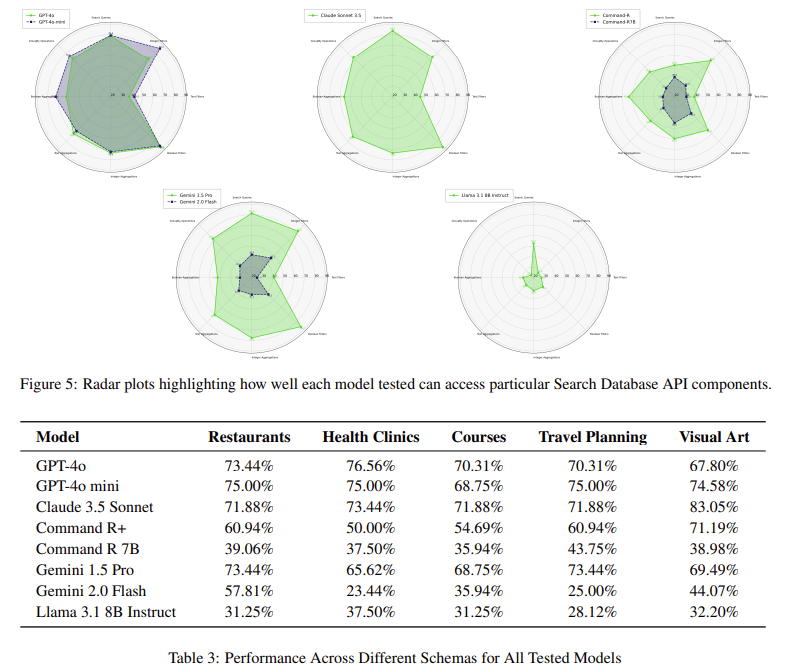
In conclusion, the research demonstrated that Operate Calling gives a viable various to text-to-SQL strategies for database querying. The important thing findings embrace:
- Larger accuracy in structured question technology: Prime fashions achieved over 74% Precise Match accuracy, surpassing many text-to-SQL benchmarks.
- Improved database routing efficiency: Routing accuracy exceeded 96%, making certain queries focused the proper collections.
- Challenges with textual content property filters: LLMs struggled to distinguish between structured filters and search queries, indicating an space for enchancment.
- Operate name variations had a minimal impression on efficiency, and totally different perform configurations, together with rationale-based and parallel calls, had solely minor results.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 75k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.