{kind=link}

Giant-scale mannequin coaching focuses on enhancing the effectivity and scalability of neural networks, particularly in pre-training language fashions with billions of parameters. Environment friendly optimization includes balancing computational sources, knowledge parallelism, and accuracy. Reaching this requires a transparent understanding of key metrics just like the crucial batch dimension (CBS), which performs a central position in coaching optimization. Researchers goal to uncover how one can scale coaching processes successfully whereas sustaining computational effectivity and mannequin efficiency.
One of many major challenges in coaching large-scale fashions is figuring out the purpose the place growing batch dimension now not proportionally reduces optimization steps. This threshold, generally known as CBS, requires cautious tuning to keep away from diminishing returns in effectivity. Efficient administration of this trade-off is crucial for enabling quicker coaching inside constrained sources. Practitioners with out a clear understanding of CBS face difficulties scaling up coaching for fashions with increased parameter counts or bigger datasets.
Present research have explored the results of batch dimension on mannequin efficiency however typically concentrate on reaching minimal loss somewhat than analyzing CBS explicitly. Additionally, most approaches have to separate the contributions of information dimension and mannequin dimension to CBS, complicating the understanding of how these components work together. Researchers have recognized gaps in earlier methodologies, notably the necessity for a scientific framework to review CBS scaling for large-scale pre-training. This hole has hindered the event of optimized coaching protocols for bigger fashions.
The analysis from Harvard College, the College of California Berkeley, the College of Hong Kong, and Amazon addressed these gaps by introducing a scientific strategy to measure CBS in large-scale autoregressive language fashions, with parameter sizes starting from 85 million to 1.2 billion. The research utilized the C4 dataset comprising 3.07 billion tokens. The researchers carried out intensive experiments to disentangle the results of mannequin dimension and knowledge dimension on CBS. Scaling legal guidelines had been developed to quantify these relationships, offering priceless insights into large-scale coaching dynamics.
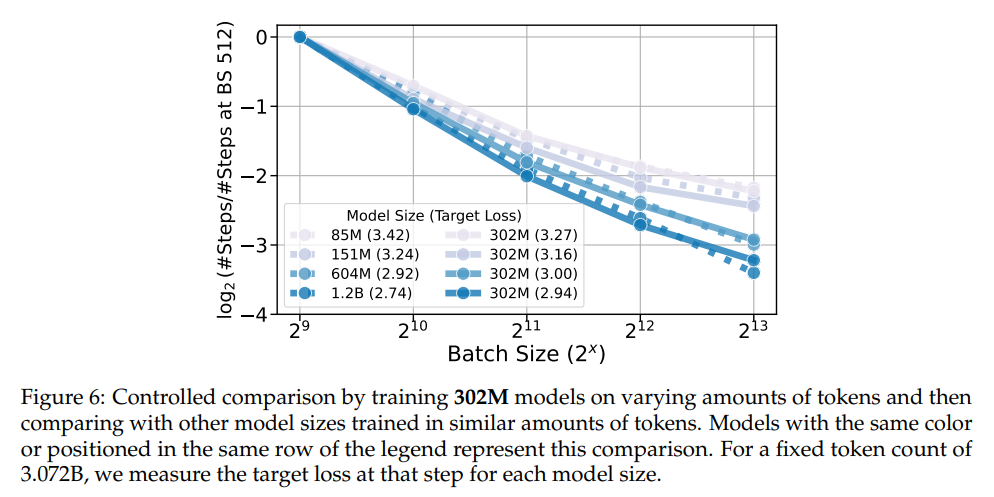
The experiments included coaching fashions beneath managed eventualities, with both knowledge or mannequin dimension held fixed to isolate their results. This revealed that CBS is predominantly influenced by knowledge dimension somewhat than mannequin dimension. To refine their measurements, the researchers integrated hyperparameter sweeps for studying charges and momentum. One key innovation was utilizing exponential weight averaging (EWA), which improved optimization effectivity and ensured constant efficiency throughout varied coaching configurations.
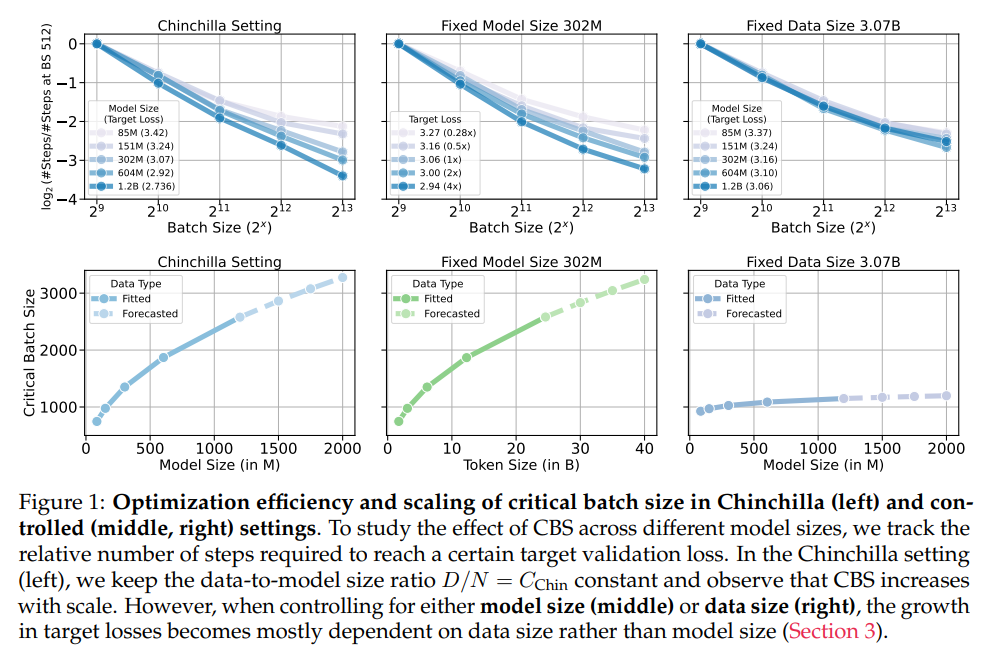
Notable findings included that CBS scales strongly with knowledge dimension, permitting for larger knowledge parallelism with out sacrificing computational effectivity. For instance, fashions skilled with a hard and fast token depend of three.07 billion confirmed constant CBS scaling no matter parameter dimension. The research additionally demonstrated that growing knowledge dimension considerably reduces serial coaching time, highlighting the potential for optimizing parallelism in resource-constrained eventualities. The outcomes align with theoretical analyses, together with insights from infinite-width neural community regimes.
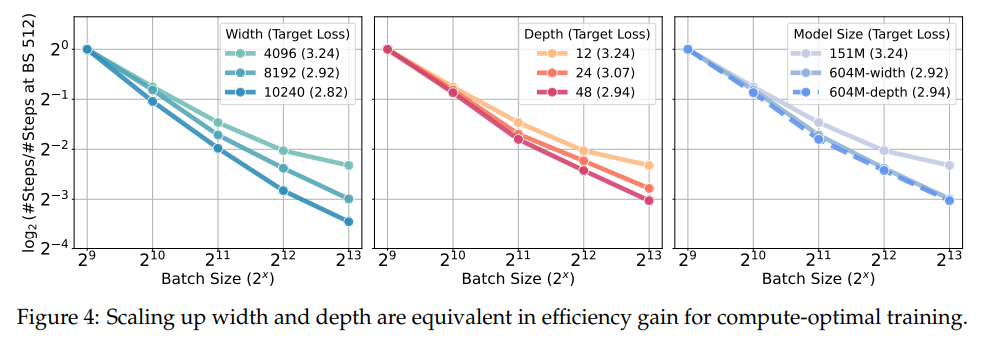
The analysis established key takeaways that supply sensible tips for large-scale coaching optimization. These are summarized as follows:
- Information dimension dominance: CBS scales primarily with knowledge dimension, enabling environment friendly parallelism for bigger datasets with out degrading computational effectivity.
- Mannequin dimension invariance: Rising mannequin dimension has minimal affect on CBS, notably past a sure parameter threshold.
- Exponential weight averaging: EWA enhances coaching consistency and effectivity, outperforming conventional cosine scheduling in large-batch eventualities.
- Scaling methods: Width and depth scaling yield equal effectivity features, offering flexibility in mannequin design.
- Hyperparameter tuning: Correct changes in studying charges and momentum are crucial for reaching optimum CBS, particularly in over- and under-training eventualities.

In conclusion, this research sheds gentle on the crucial components influencing large-scale mannequin coaching, with CBS rising as a pivotal metric for optimization. The analysis gives actionable insights into enhancing coaching effectivity by demonstrating that CBS scales with knowledge dimension somewhat than mannequin dimension. Introducing scaling legal guidelines and progressive methods like EWA ensures sensible applicability in real-world eventualities, enabling researchers to design higher coaching protocols for expansive datasets and sophisticated fashions. These findings pave the best way for extra environment friendly use of sources within the quickly evolving subject of machine studying.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.