{kind=link}

Disaggregated programs are a brand new sort of structure designed to fulfill the excessive useful resource calls for of recent functions like social networking, search, and in-memory databases. The programs intend to beat the bodily restrictions of the normal servers by pooling and managing sources like reminiscence and CPUs amongst a number of machines. Flexibility, higher utilization of sources, and cost-effectiveness make this strategy appropriate for scalable cloud infrastructure, however this distributed design introduces vital challenges. Non-uniform reminiscence entry (NUMA) and distant useful resource entry create latency and efficiency points, that are laborious to optimize. Competition for shared sources, reminiscence locality issues, and scalability limits additional complicate the usage of disaggregated programs, resulting in unpredictable software efficiency and useful resource administration difficulties.
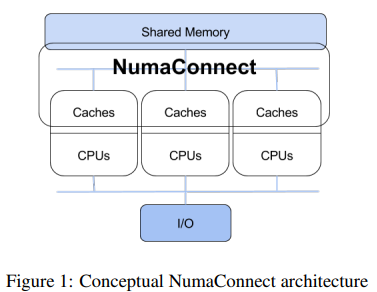
At present, the useful resource rivalry in reminiscence hierarchies and locality optimizations by way of UMA and NUMA-aware strategies in fashionable programs face main drawbacks. UMA doesn’t take into account the impression of distant reminiscence and, thus, can’t be efficient on large-scale architectures. Nonetheless, NUMA-based strategies are geared toward small settings or simulations as an alternative of the true world. As single-core efficiency stagnated, multicore programs turned commonplace, introducing programming and scaling challenges. Applied sciences resembling NumaConnect unify sources with shared reminiscence and cache coherency however rely extremely on workload traits. Utility classification schemes, resembling animal lessons, simplify the categorization of workloads however lack adaptability, failing to handle variability in useful resource sensitivity.
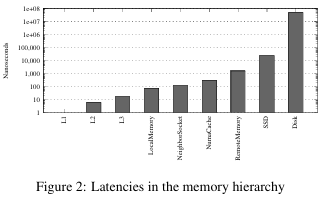
To handle challenges posed by advanced NUMA topologies on software efficiency, researchers from Umea College, Sweden, proposed a NUMA-aware useful resource mapping algorithm for virtualized environments on disaggregated programs. Researchers carried out detailed analysis to discover useful resource rivalry in shared environments. Researchers analyzed cache rivalry, reminiscence hierarchy latency variations, and NUMA distances, all influencing efficiency.
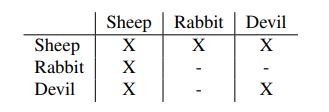
The NUMA-aware algorithm optimized useful resource allocation by pinning digital cores and migrating reminiscence, thereby lowering reminiscence slicing throughout nodes and minimizing software interference. Functions have been categorized (e.g., “Sheep,” “Rabbit,” “Satan”) and punctiliously positioned primarily based on compatibility matrices to reduce rivalry. The response time, clock fee, and energy utilization have been tracked in real-time together with IPC and MPI to allow the required modifications in useful resource allocation. Evaluations carried out on a disaggregated sixnode system demonstrated that vital enhancements in software efficiency could possibly be realized with memory-intensive workloads in comparison with default schedulers.
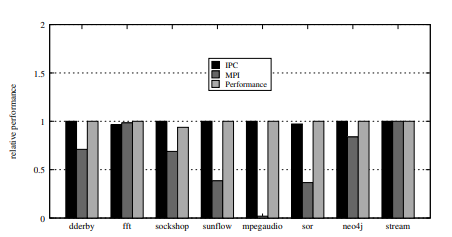
Researchers carried out experiments with numerous VM sorts, small, medium, massive, and large operating workloads like Neo4j, Sockshop, SPECjvm2008, and Stream, to simulate real-world functions. The shared reminiscence algorithm optimized virtual-to-physical useful resource mapping, lowered the NUMA distance and useful resource rivalry, and ensured affinity between cores and reminiscence. It differed from the default Linux scheduler, the place the core mappings are random, and efficiency is variable. The algorithm supplied secure mappings and minimized interference.

Outcomes confirmed vital efficiency enhancements with the shared reminiscence algorithm variants (SM-IPC and SM-MPI), reaching as much as 241x enhancement in instances like Derby and Neo4j. Whereas the vanilla scheduler exhibited unpredictable efficiency with commonplace deviation ratios above 0.4, the shared reminiscence algorithms maintained constant efficiency with ratios under 0.04. As well as, VM measurement affected the efficiency of the vanilla scheduler however had little impact on the shared reminiscence algorithms, which mirrored their effectivity in useful resource allocation throughout numerous environments.
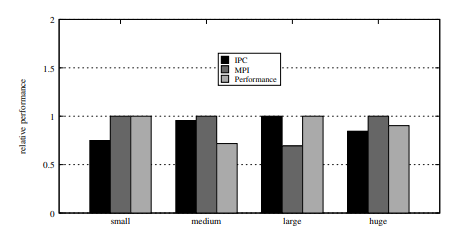
In conclusion, the algorithm proposed by researchers permits useful resource composition from disaggregated servers, leading to as much as a 50x enchancment in software efficiency in comparison with the default Linux scheduler. Outcomes proved that the algorithm will increase useful resource effectivity, software co-location, and person capability. This methodology can act as a baseline for future developments in useful resource mapping and efficiency optimization in NUMA disaggregated programs.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Information and Analysis Intelligence–Be part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding knowledge privateness.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.