{kind=link}

Embodied synthetic intelligence (AI) entails creating brokers that perform inside bodily or simulated environments, executing duties autonomously primarily based on pre-defined aims. Typically utilized in robotics and sophisticated simulations, these brokers leverage intensive datasets and complicated fashions to optimize habits and decision-making. In distinction to extra easy purposes, embodied AI requires fashions able to managing huge quantities of sensorimotor information and sophisticated interactive dynamics. As such, the sector has more and more prioritized “scaling,” a course of that adjusts mannequin measurement, dataset quantity, and computational energy to realize environment friendly and efficient agent efficiency throughout various duties.
The problem with scaling embodied AI fashions lies in placing a stability between mannequin measurement and dataset quantity, a course of crucial to make sure that these brokers can function optimally inside constraints on computational assets. Completely different from language fashions, the place scaling is well-established, the exact interaction of things like dataset measurement, mannequin parameters, and computation prices in embodied AI nonetheless must be explored. This lack of readability limits researchers’ skill to assemble large-scale fashions successfully, because it stays unclear the way to distribute assets for duties requiring behavioral and environmental adaptation optimally. For example, whereas growing mannequin measurement improves efficiency, doing so and not using a proportional enhance in information can result in inefficiencies and even diminished returns, particularly in duties like habits cloning and world modeling.
Language fashions have developed strong scaling legal guidelines that define relationships between mannequin measurement, information, and compute necessities. These legal guidelines allow researchers to make educated predictions concerning the crucial configurations for efficient mannequin coaching. Nonetheless, embodied AI has not totally adopted these rules, partly due to the numerous nature of its duties. In response, researchers have been engaged on transferring scaling insights from language fashions to embodied AI, significantly by pre-training brokers on giant offline datasets that seize various environmental and behavioral information. The purpose is to determine legal guidelines that assist embody brokers obtain excessive efficiency in decision-making and interplay with their environment.
Researchers at Microsoft Analysis have lately developed scaling legal guidelines particularly for embodied AI, introducing a strategy that evaluates how modifications in mannequin parameters, dataset measurement, and computational limits influence the educational effectivity of AI brokers. The staff’s work centered on two main duties inside embodied AI: habits cloning, the place brokers be taught to copy noticed actions, and world modeling, the place brokers predict environmental modifications primarily based on prior actions and observations. They used transformer-based architectures, testing their fashions beneath varied configurations to know how tokenization methods and mannequin compression charges have an effect on total effectivity and accuracy. By systematically adjusting the variety of parameters and tokens, the researchers noticed distinct scaling patterns that might enhance mannequin efficiency and compute effectivity.
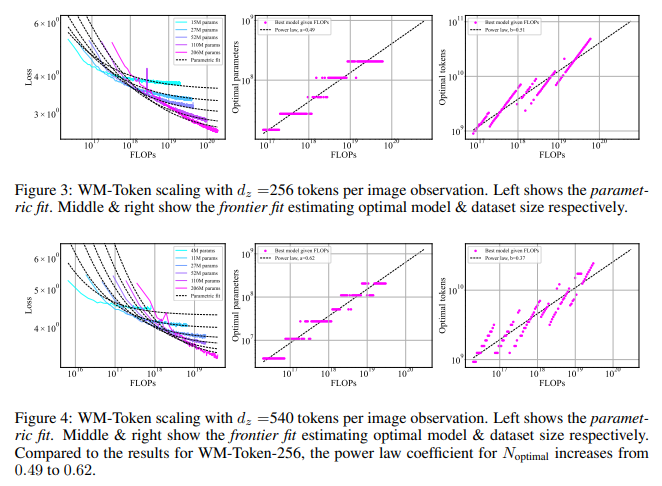
The methodology concerned coaching transformers with totally different tokenization approaches to stability mannequin and dataset sizes. For example, the staff carried out tokenized and CNN-based architectures in habits cloning, permitting the mannequin to function beneath a steady embedding framework fairly than discrete tokens, lowering computational calls for considerably. The examine discovered that for world modeling, scaling legal guidelines demonstrated that a rise in token rely per commentary affected mannequin sizing, with the optimum mannequin measurement coefficient growing from 0.49 to 0.62 because the tokens rose from 256 to 540 per picture. Nonetheless, for habits cloning with tokenized observations, optimum mannequin measurement coefficients have been skewed in direction of bigger datasets with smaller fashions, displaying a necessity for better information quantity fairly than expanded parameters, an reverse development to that seen in world modeling.
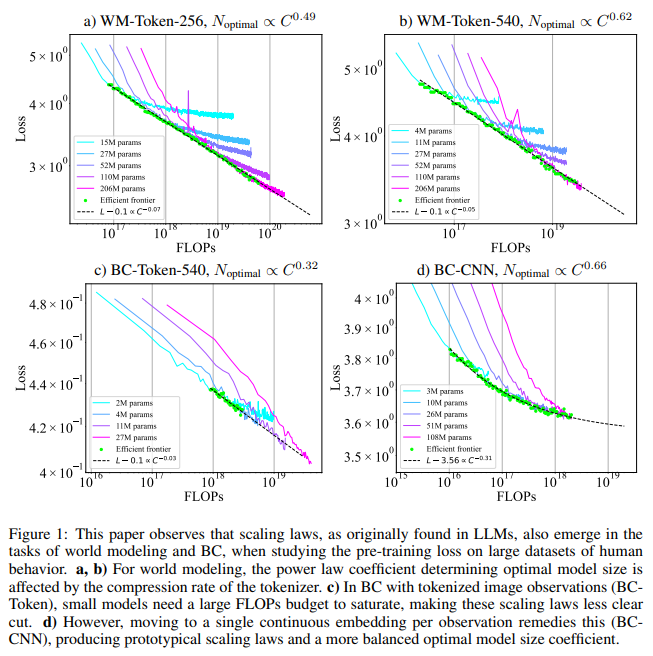
The examine introduced outstanding findings on how scaling rules from language fashions could possibly be utilized successfully to embodied AI. The optimum trade-off occurred for world modeling when each mannequin and dataset measurement elevated proportionally, matching findings in LLM scaling literature. Particularly, with a 256-token configuration, an optimum stability was achieved by scaling each mannequin and dataset in comparable proportions. In distinction, within the 540-token configuration, the emphasis shifted towards bigger fashions, making measurement changes extremely depending on the compression charge of the tokenized observations.
Key outcomes highlighted that mannequin structure influences the scaling stability, significantly for habits cloning. In duties the place brokers used tokenized observations, mannequin coefficients indicated a desire for intensive information over bigger mannequin sizes, with an optimum measurement coefficient of 0.32 in opposition to a dataset coefficient of 0.68. Compared, habits cloning duties primarily based on CNN architectures favored elevated mannequin measurement, with an optimum measurement coefficient of 0.66. This demonstrated that embodied AI may obtain environment friendly scaling beneath particular situations by tailoring mannequin and dataset proportions primarily based on activity necessities.
In testing the accuracy of the derived scaling legal guidelines, the analysis staff educated a world-modeling agent with a mannequin measurement of 894 million parameters, considerably bigger than these utilized in prior scaling analyses. The examine discovered a powerful alignment between predictions and precise outcomes, with the loss worth carefully matching computed optimum loss ranges even beneath considerably elevated compute budgets. This validation step underscored the scaling legal guidelines’ reliability, suggesting that with applicable hyperparameter tuning, scaling legal guidelines can predict mannequin efficiency successfully in advanced simulations and real-world situations.
Key Takeaways from the Analysis:
- Balanced Scaling for World Modeling: For optimum efficiency in world modeling, each mannequin and dataset sizes should enhance proportionally.
- Habits Cloning Optimization: Optimum configurations for habits cloning favor smaller fashions paired with intensive datasets when tokenized observations are used. A rise in mannequin measurement is most well-liked for CNN-based cloning duties.
- Compression Fee Influence: Greater token compression charges skew scaling legal guidelines towards bigger fashions in world modeling, indicating that tokenized information considerably impacts optimum mannequin sizes.
- Extrapolation Validation: Testing with bigger fashions confirmed the scaling legal guidelines’ predictability, supporting these legal guidelines as a foundation for environment friendly mannequin sizing in embodied AI.
- Distinct Job Necessities: Scaling necessities differ considerably between habits cloning and world modeling, highlighting the significance of personalized scaling approaches for various AI duties.

In conclusion, this examine advances embodied AI by tailoring language mannequin scaling insights to AI agent duties. This permits researchers to foretell and management useful resource wants extra precisely. Establishing these tailor-made scaling legal guidelines helps the event of extra environment friendly, succesful brokers in environments demanding excessive computational and information effectivity.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Companies and Actual Property Transactions
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.