{kind=link}

Pure Language Technology (NLG) is a website of synthetic intelligence that seeks to allow machines to supply human-like textual content. By leveraging developments in deep studying, researchers intention to develop techniques able to producing contextually related and coherent responses. Functions of this know-how span various areas, together with automated buyer assist, inventive writing, and real-time language translation, emphasizing seamless communication between people and machines.
A key problem on this area lies in assessing the knowledge of machine-generated textual content. As a consequence of their probabilistic nature, language fashions might produce varied outputs for a similar enter immediate. This variability raises issues in regards to the generated content material’s reliability and the mannequin’s confidence in its predictions. Addressing this situation is vital for functions the place consistency and accuracy are paramount, similar to medical or authorized documentation.
To estimate uncertainty in generated textual content, conventional approaches depend on sampling a number of output sequences and analyzing them collectively. These strategies, whereas insightful, demand vital computational assets since producing a number of sequences is computationally costly. Consequently, the practicality of such strategies diminishes for larger-scale deployments or duties involving advanced language fashions.
Researchers from the ELLIS Unit Linz and LIT AI Lab at Johannes Kepler College Linz, Austria, launched a novel strategy, G-NLL, to streamline the uncertainty estimation course of. This methodology relies on computing essentially the most possible output sequence’s adverse log-likelihood (NLL). In contrast to earlier approaches that depend on sampling, G-NLL makes use of grasping decoding to determine essentially the most possible sequence and consider its probability. By specializing in this singular sequence, the tactic bypasses the necessity for in depth computational overhead, making it a extra environment friendly various.
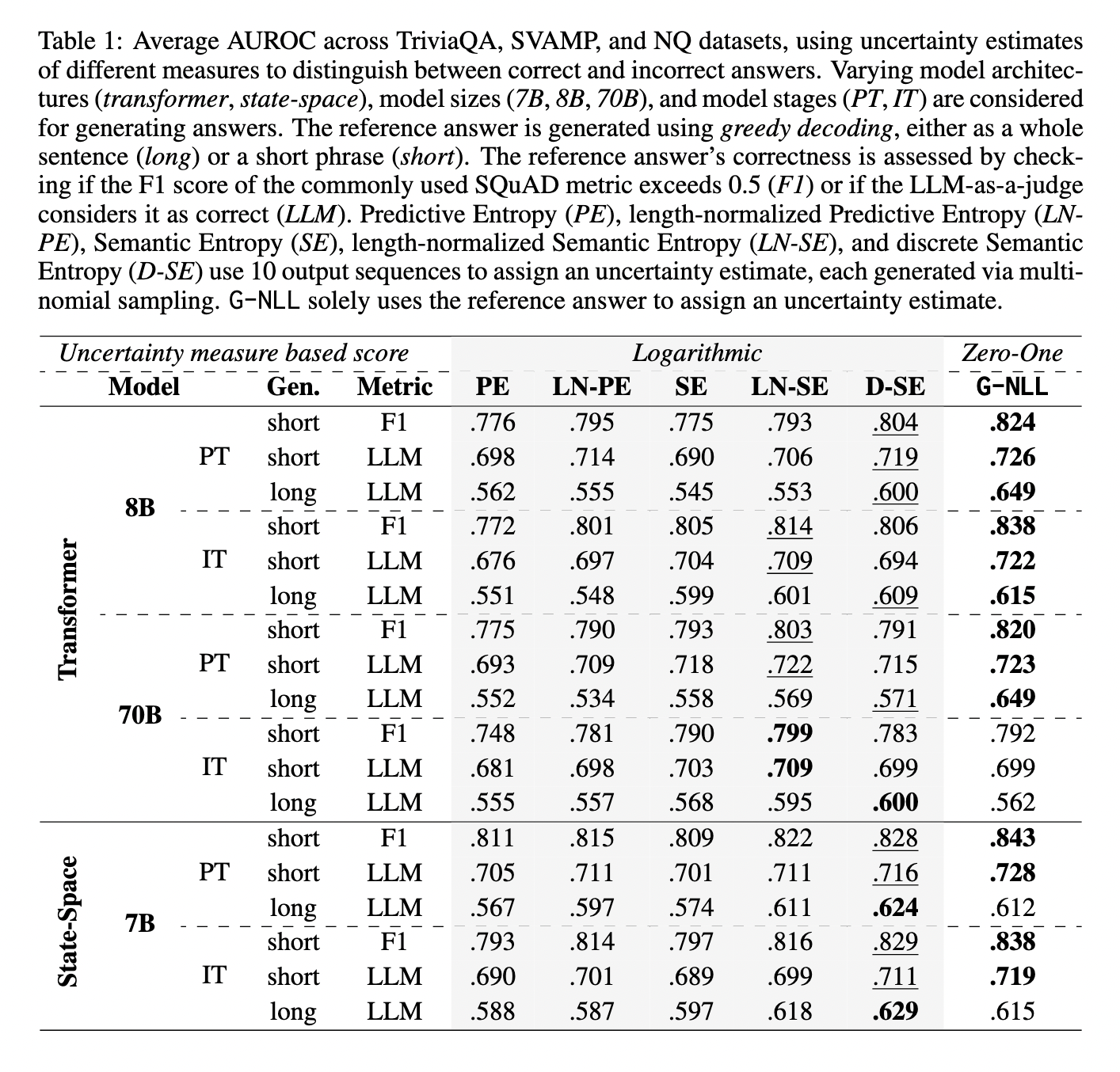
The G-NLL methodology includes calculating the chance of the almost definitely output sequence generated by a mannequin. The adverse log-likelihood of this sequence serves as a direct measure of uncertainty, with decrease values indicating better confidence within the generated textual content. This strategy eliminates the redundancy of producing a number of sequences whereas sustaining the robustness required for efficient uncertainty estimation. Additional, the tactic integrates seamlessly with current language fashions, requiring minimal modification to the decoding course of.
Empirical evaluations of G-NLL demonstrated its superior efficiency throughout varied duties and fashions. Researchers examined the tactic on datasets generally used for benchmarking language technology duties, together with machine translation and summarization. G-NLL persistently matched or surpassed the efficiency of conventional sampling-based strategies. For example, in a particular analysis, the method decreased computational value whereas sustaining accuracy ranges on par with typical methods. Detailed outcomes from experiments confirmed a big effectivity enchancment, with decreased computational calls for by as much as 50% in some duties.
By addressing a vital limitation in NLG techniques, the researchers supplied a sensible and scalable resolution for estimating uncertainty. G-NLL represents a step ahead in making language fashions extra accessible for functions that require excessive reliability and computational effectivity. The innovation affords potential advantages for industries counting on automated textual content technology, together with healthcare, training, and customer support, the place confidence in outputs is essential.
In conclusion, this analysis tackles the elemental downside of uncertainty estimation in machine-generated textual content by introducing G-NLL. The strategy simplifies the method, reduces computational prices, and achieves robust efficiency throughout a number of benchmarks, solidifying its contribution to NLG. This development units a brand new normal for effectivity and reliability in uncertainty estimation strategies, paving the way in which for the broader adoption of language technology techniques.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.