{kind=link}

Video massive language fashions (VLLMs) have emerged as transformative instruments for analyzing video content material. These fashions excel in multimodal reasoning, integrating visible and textual knowledge to interpret and reply to advanced video eventualities. Their purposes vary from question-answering about movies to summarization and video description. With their capability to course of large-scale inputs and supply detailed outputs, they’re essential in duties requiring superior comprehension of visible dynamics.
One key problem in VLLMs is managing the computational prices of processing huge visible knowledge from video inputs. Movies inherently carry excessive redundancy as frames typically seize overlapping info. These frames generate 1000’s of tokens when processed, resulting in vital reminiscence consumption and slower inference speeds. Addressing this concern is crucial for making VLLMs environment friendly with out compromising their capacity to carry out advanced reasoning duties.
Present strategies have tried to mitigate computational constraints by introducing token pruning methods and designing light-weight fashions. For instance, pruning strategies like FastV leverage consideration scores to cut back much less related tokens. Nonetheless, these approaches typically depend on static one-shot pruning methods, which might inadvertently take away crucial tokens obligatory for sustaining excessive accuracy. Furthermore, parameter discount methods ceaselessly compromise the reasoning capabilities of the fashions, limiting their utility to demanding duties.
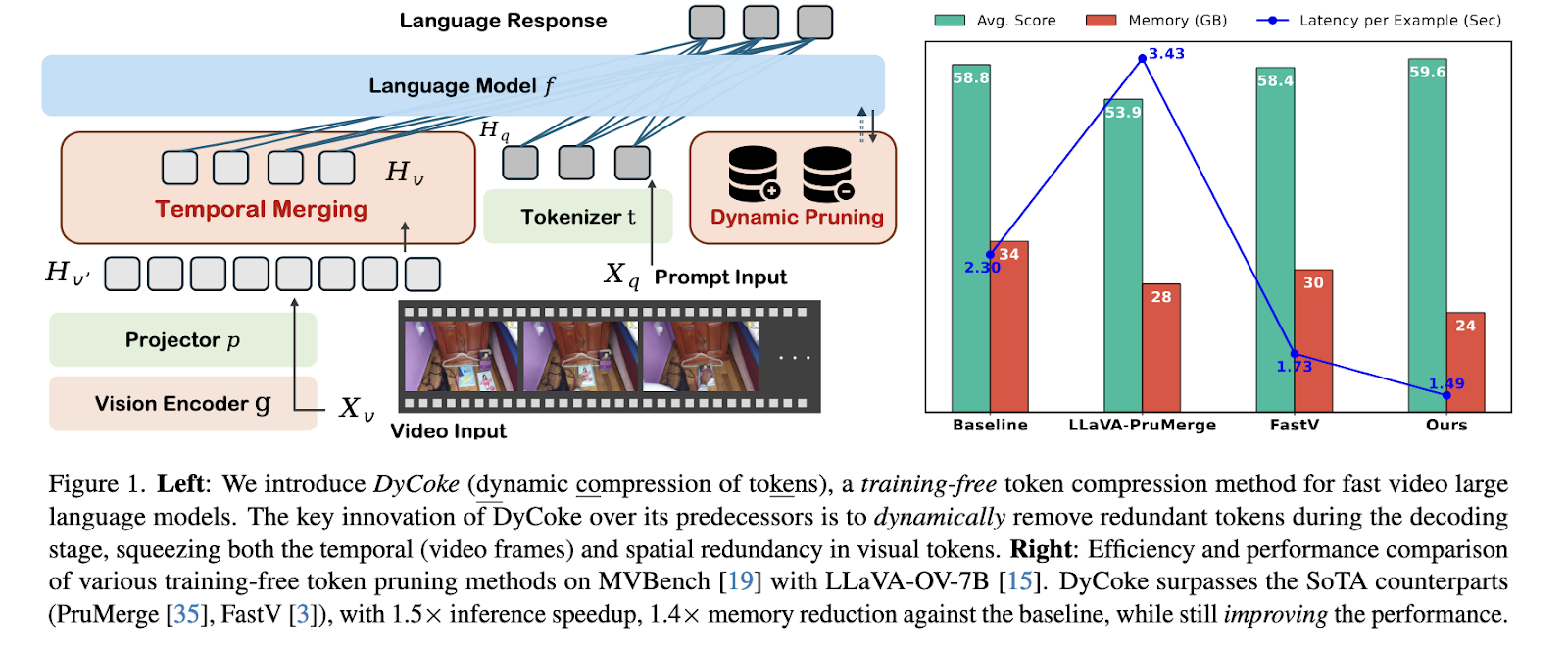
Researchers from Westlake College, Salesforce AI Analysis, Apple AI/ML, and Rice College launched DyCoke, a novel methodology designed to dynamically compress tokens in massive video language fashions. DyCoke adopts a training-free method, distinguishing itself by addressing temporal and spatial redundancies in video inputs. By implementing dynamic and adaptive pruning mechanisms, the strategy optimizes computational effectivity whereas preserving excessive efficiency. This innovation goals to make VLLMs scalable for real-world purposes with out requiring fine-tuning or extra coaching.
DyCoke employs a two-stage course of for token compression. Temporal token merging consolidates redundant tokens throughout adjoining video frames within the first stage. This module teams frames into sampling home windows and identifies overlapping info, merging tokens to retain solely distinct and consultant ones. For example, visible redundancy in static backgrounds or repeated actions is successfully diminished. Throughout the decoding part, the second stage employs a dynamic pruning approach within the key-value (KV) cache. Tokens are dynamically evaluated and retained primarily based on their consideration scores. This step ensures that solely essentially the most crucial tokens stay, whereas irrelevant tokens are saved in a dynamic pruning cache for potential reuse. By iteratively refining the KV cache at every decoding step, DyCoke aligns computational load with the precise significance of tokens.
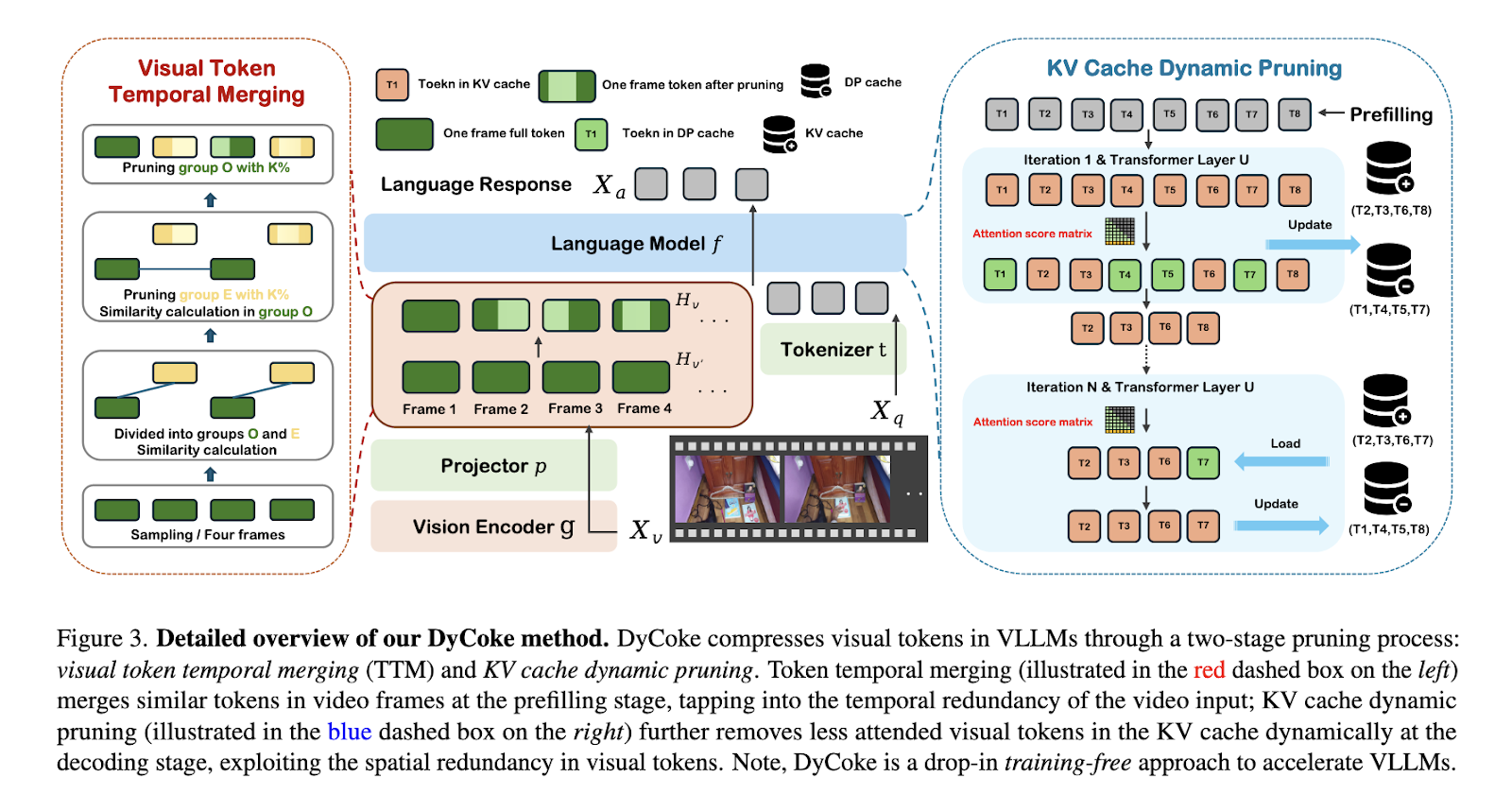
The outcomes of DyCoke spotlight its effectivity and robustness. On benchmarks similar to MVBench, which incorporates 20 advanced duties like motion recognition and object interplay, DyCoke achieved as much as 1.5× inference speedup and a 1.4× discount in reminiscence utilization in comparison with baseline fashions. Particularly, the strategy diminished the variety of retained tokens to as little as 14.25% in some configurations, with minimal efficiency degradation. On the VideoMME dataset, DyCoke excelled in processing lengthy video sequences, demonstrating superior effectivity whereas sustaining or surpassing uncompressed fashions’ accuracy. For instance, with a pruning charge 0.5, it achieved a latency discount of as much as 47%. It outperformed state-of-the-art strategies like FastV in sustaining accuracy throughout duties similar to episodic reasoning and selfish navigation.
DyCoke’s contribution extends past pace and reminiscence effectivity. It simplifies video reasoning duties by decreasing temporal and spatial redundancy in visible inputs, successfully balancing efficiency and useful resource utilization. In contrast to earlier strategies that required intensive coaching, DyCoke operates as a plug-and-play resolution, making it accessible for a variety of video language fashions. Its capacity to dynamically regulate token retention ensures that crucial info is preserved, even in demanding inference eventualities.

Total, DyCoke represents a major step ahead within the evolution of VLLMs. Addressing the computational challenges inherent in video processing allows these fashions to function extra effectively with out compromising their reasoning capabilities. This innovation advances state-of-the-art video understanding and opens new potentialities for deploying VLLMs in real-world eventualities the place computational assets are sometimes restricted.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.