{kind=link}
")
By intertwining the event of synthetic intelligence mixed with massive language fashions with reinforcement studying in high-performance computation, the newly developed Reasoning Language Fashions could leap past conventional methods of limitation utilized to processing by language methods towards specific and even structured mechanisms, enabling complicated reasoning options throughout numerous realms. Such mannequin growth achievement is the subsequent important landmark for higher contextual insights and choices.
The design and deployment of contemporary RLMs pose numerous challenges. They’re costly to develop, have proprietary restrictions, and have complicated architectures that restrict their entry. Furthermore, the technical obscurity of their operations creates a barrier for organizations and researchers to faucet into these applied sciences. The shortage of inexpensive and scalable options exacerbates the hole between entities with entry to cutting-edge fashions, limiting alternatives for broader innovation and utility.
Present RLM implementations depend on complicated methodologies to attain their reasoning capabilities. Methods like Monte Carlo Tree Search (MCTS), Beam Search, and reinforcement studying ideas like process-based and outcome-based supervision have been employed. Nevertheless, these strategies demand superior experience and assets, proscribing their utility for smaller establishments. Whereas LLMs like OpenAI’s o1 and o3 present foundational capabilities, their integration with specific reasoning frameworks stays restricted, leaving the potential for broader implementation untapped.
Researchers from ETH Zurich, BASF SE, Cledar, and Cyfronet AGH launched a complete blueprint to streamline the design and growth of RLMs. This modular framework unifies numerous reasoning constructions, together with chains, timber, and graphs, permitting for versatile and environment friendly experimentation. The blueprint’s core innovation lies in integrating reinforcement studying rules with hierarchical reasoning methods, enabling scalable and cost-effective mannequin building. As a part of this work, the crew developed the x1 framework, a sensible implementation software for researchers and organizations to prototype RLMs quickly.
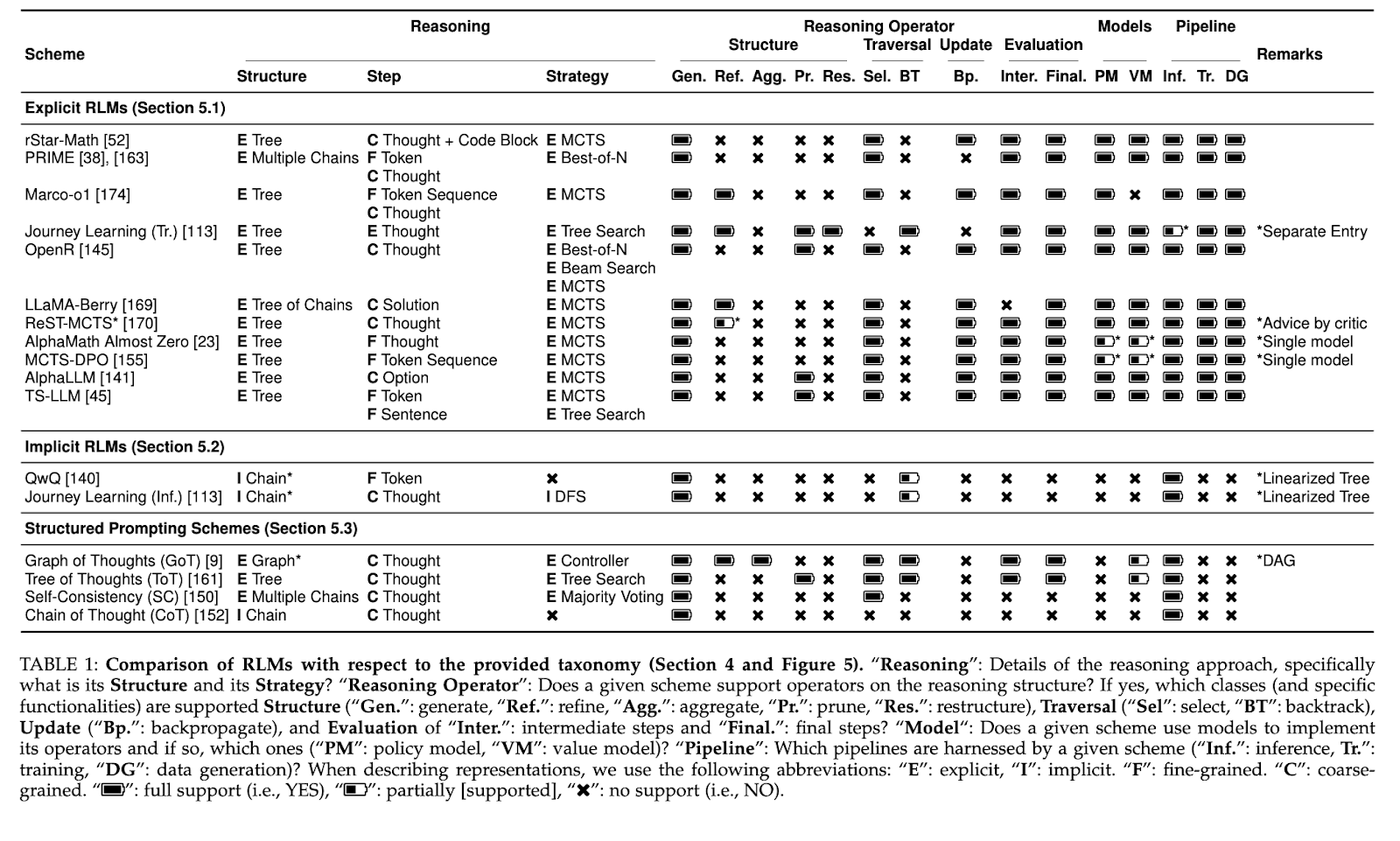
The blueprint organizes the development of RLM into a transparent set of parts: reasoning schemes, operators, and pipelines. Reasoning schemes outline the constructions and techniques for navigating complicated issues starting from sequential chains to multi-level hierarchical graphs. Operators management how these patterns change in order that operations can easily embody fine-tuning, pruning, and restructurings of reasoning paths. Pipelines enable straightforward movement between coaching, inference, and information technology and are adaptable throughout functions. This block-component construction helps particular person entry whereas fashions will be fine-tuned to a fine-grained job akin to token-level reasoning or broader structured challenges.
The crew showcased the effectiveness of the blueprint and x1 framework utilizing empirical examine and real-world implementations. This modular design supplied multi-phase coaching methods that would optimize coverage and worth fashions, additional enhancing reasoning accuracy and scalability. It leveraged acquainted coaching distributions to take care of excessive precision throughout functions. Noteworthy outcomes included massive effectivity enhancements in reasoning duties attributed to the streamlined integration of reasoning constructions. As an illustration, it demonstrated the potential for efficient retrieval-augmented technology strategies by means of experiments, reducing the computational price of complicated decision-making eventualities. Such breakthroughs reveal that the blueprint permits superior reasoning applied sciences to be democratized to even low-resource organizations.
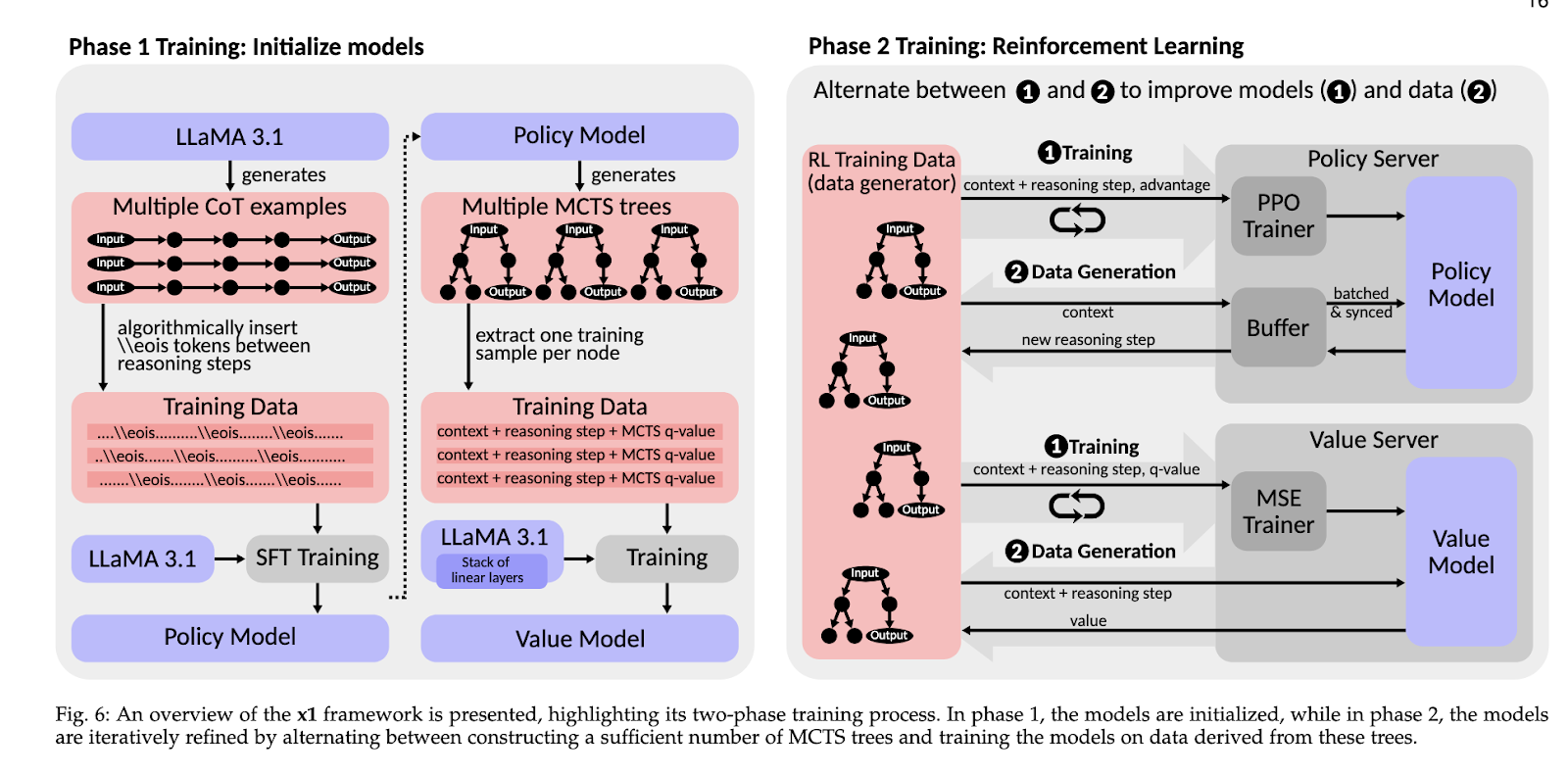
This work marks a turning level within the design of RLMs. This analysis addresses necessary points in entry and scalability to permit researchers and organizations to develop novel reasoning paradigms. The modular design encourages experimentation and adaptation, serving to bridge the divide between proprietary methods and open innovation. The introduction of the x1 framework additional underscores this effort by offering a sensible software for growing and deploying scalable RLMs. This work presents a roadmap for advancing clever methods, making certain that the advantages of superior reasoning fashions will be broadly shared throughout industries and disciplines.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 70k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.