{kind=link}

Textual content-to-audio technology has remodeled how audio content material is created, automating processes that historically required important experience and time. This expertise permits the conversion of textual prompts into numerous and expressive audio, streamlining workflows in audio manufacturing and artistic industries. Bridging textual enter with reasonable audio outputs has opened prospects in purposes like multimedia storytelling, music, and sound design.
One of many important challenges in text-to-audio programs is guaranteeing that generated audio aligns faithfully with textual prompts. Present fashions typically fail to seize intricate particulars, resulting in inconsistencies totally. Some outputs omit important components or introduce unintended audio artifacts. The dearth of standardized strategies for optimizing these programs additional exacerbates the issue. In contrast to language fashions, text-to-audio programs don’t profit from strong alignment methods, corresponding to reinforcement studying with human suggestions, leaving a lot room for enchancment.
Earlier approaches to text-to-audio technology relied closely on diffusion-based fashions, corresponding to AudioLDM and Steady Audio Open. Whereas these fashions ship respectable high quality, they arrive with limitations. Their reliance on in depth denoising steps makes them computationally costly and time-intensive. Moreover, many fashions are educated on proprietary datasets, which limits their accessibility and reproducibility. These constraints hinder their scalability and talent to deal with numerous and complicated prompts successfully.
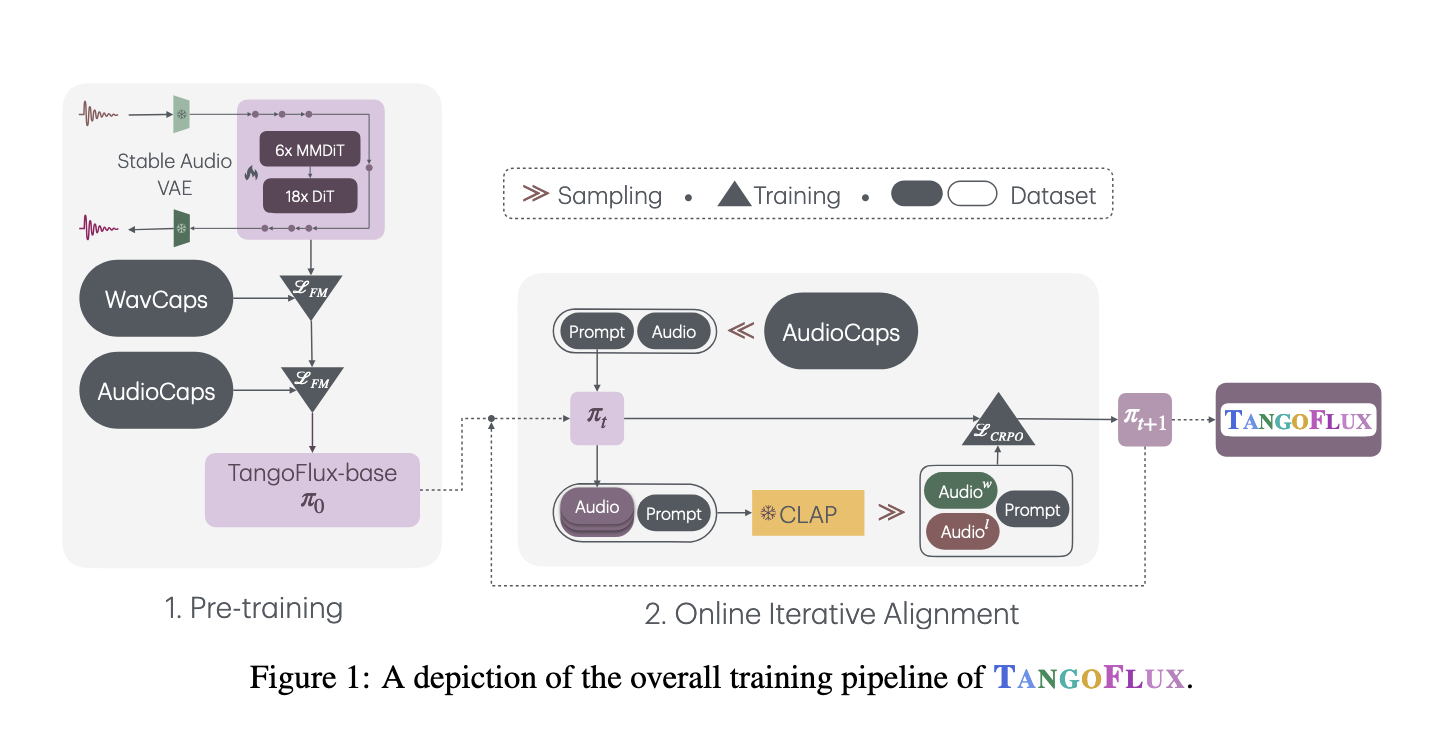
To handle these challenges, researchers from the Singapore College of Expertise and Design (SUTD) and NVIDIA launched TANGOFLUX, a complicated text-to-audio technology mannequin. This mannequin is designed for effectivity and high-quality output, attaining important enhancements over earlier strategies. TANGOFLUX makes use of the CLAP-Ranked Choice Optimization (CRPO) framework to refine audio technology and guarantee alignment with textual descriptions iteratively. Its compact structure and progressive coaching methods permit it to carry out exceptionally effectively whereas requiring fewer parameters.
TANGOFLUX integrates superior methodologies to realize state-of-the-art outcomes. It employs a hybrid structure combining Diffusion Transformer (DiT) and Multimodal Diffusion Transformer (MMDiT) blocks, enabling it to deal with variable-duration audio technology. In contrast to conventional diffusion-based fashions, which depend upon a number of denoising steps, TANGOFLUX makes use of a flow-matching framework to create a direct and rectified path from noise to output. This rectified circulate method reduces the computational steps required for high-quality audio technology. Throughout coaching, the system incorporates textual and length conditioning to make sure precision in capturing enter prompts’ nuances and the audio output’s desired size. The CLAP mannequin evaluates the alignment between audio and textual prompts by producing choice pairs and optimizing them iteratively, a course of impressed by alignment strategies utilized in language fashions.
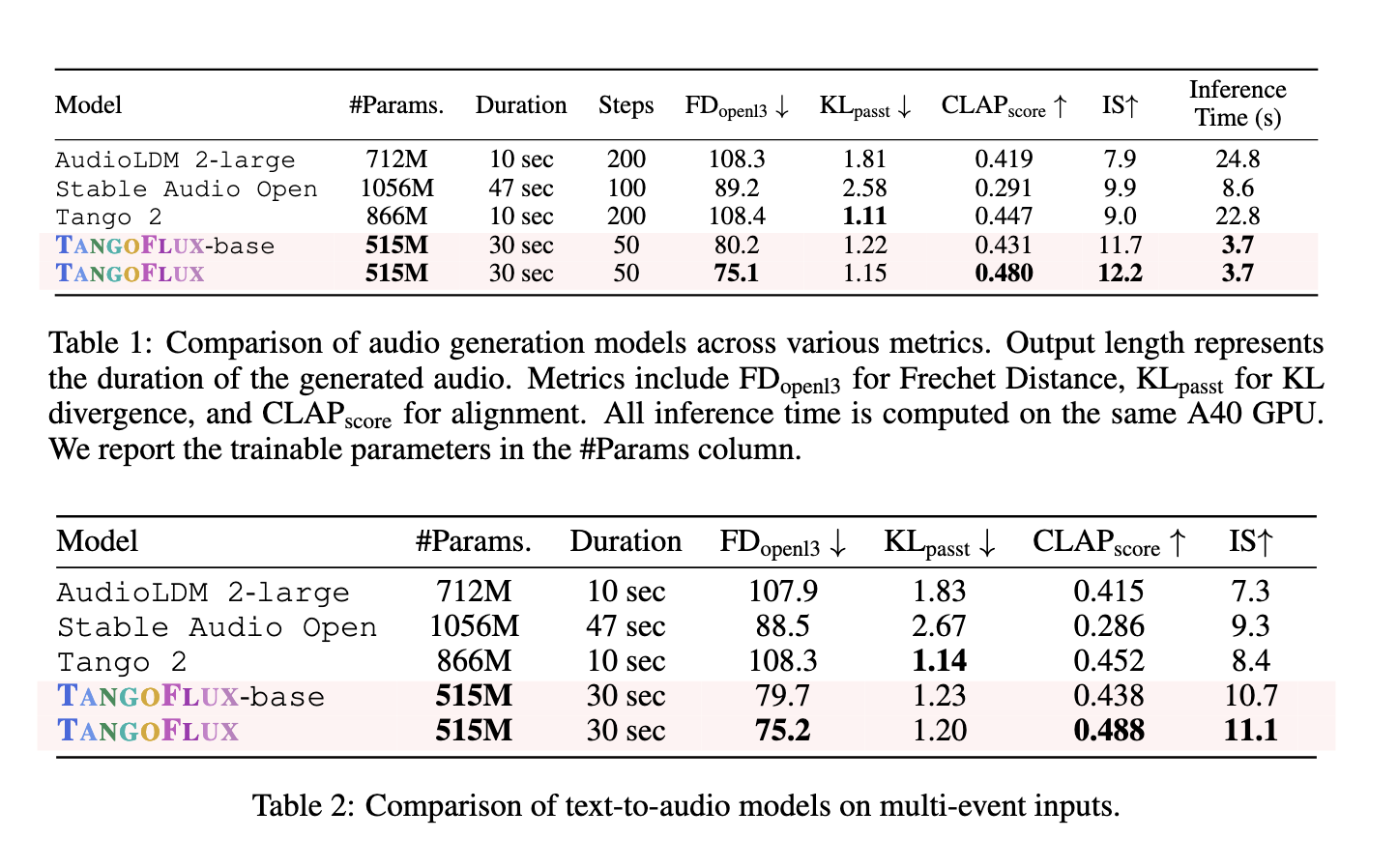
By way of efficiency, TANGOFLUX outshines its predecessors throughout a number of metrics. It generates 30 seconds of audio in simply 3.7 seconds utilizing a single A40 GPU, demonstrating distinctive effectivity. The mannequin achieves a CLAP rating of 0.48 and an FD rating of 75.1, each indicative of high-quality and text-aligned audio outputs. In comparison with Steady Audio Open, which achieves a CLAP rating of 0.29, TANGOFLUX considerably improves alignment accuracy. In multi-event eventualities, the place prompts embody a number of distinct occasions, TANGOFLUX excels, showcasing its potential to seize intricate particulars and temporal relationships successfully. The system’s robustness is additional highlighted by its potential to take care of efficiency even with diminished sampling steps, a characteristic that enhances its practicality in real-time purposes.
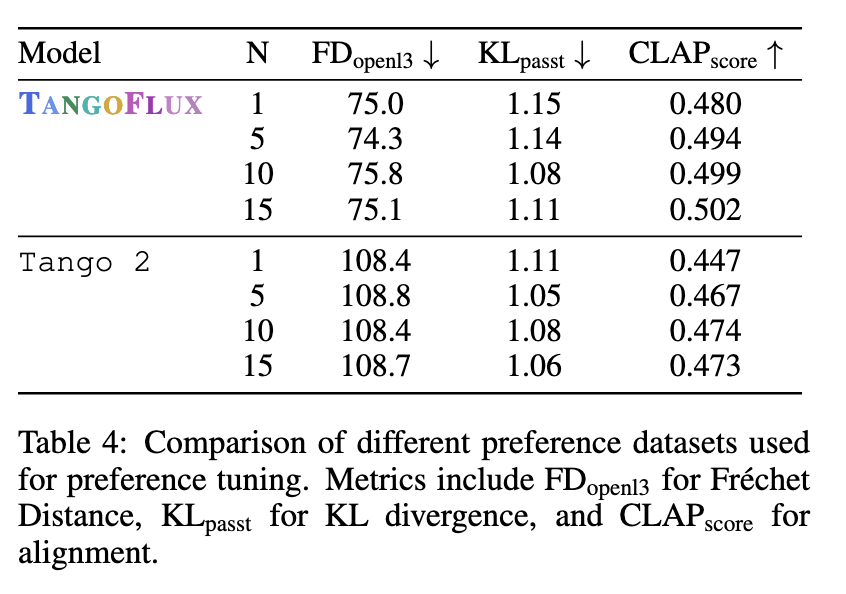
Human evaluations corroborate these outcomes, with TANGOFLUX scoring the best in subjective metrics corresponding to general high quality and immediate relevance. Annotators constantly rated its outputs as clearer and extra aligned than different fashions like AudioLDM and Tango 2. The researchers additionally emphasised the significance of the CRPO framework, which allowed for making a choice dataset that outperformed alternate options corresponding to BATON and Audio-Alpaca. The mannequin prevented efficiency degradation sometimes related to offline datasets by producing new artificial information throughout every coaching iteration.
The analysis efficiently addresses important limitations in text-to-audio programs by introducing TANGOFLUX, which mixes effectivity with superior efficiency. Its progressive use of rectified circulate and choice optimization units a benchmark for future developments within the subject. This improvement enhances the standard and alignment of generated audio and demonstrates scalability, making it a sensible answer for widespread adoption. The work of SUTD and NVIDIA represents a major leap ahead in text-to-audio expertise, pushing the boundaries of what’s achievable on this quickly evolving area.
Take a look at the Paper, Code Repo, and Pre-Educated Mannequin. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Information and Analysis Intelligence–Be a part of this webinar to achieve actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding information privateness.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.