{kind=link}

Pure language processing (NLP) has skilled a surge in progress with the emergence of enormous language fashions (LLMs), that are utilized in numerous purposes akin to textual content era, translation, and conversational brokers. These fashions can course of and perceive human languages at an unprecedented stage, enabling seamless communication between machines and customers. Nevertheless, regardless of their success, deploying these fashions throughout a number of languages poses vital challenges as a result of required computational sources. The complexity of multilingual settings, which entails numerous language buildings and vocabulary variations, additional complicates the environment friendly deployment of LLMs in sensible, real-world purposes.
Excessive inference time is a serious drawback when deploying LLMs in multilingual contexts. Inference time refers back to the length required by a mannequin to generate responses primarily based on given inputs, and this time will increase dramatically in multilingual settings. One issue contributing to this situation is the discrepancy in tokenization and vocabulary sizes between languages, which results in variations in encoding lengths. For instance, languages with intricate grammatical buildings or bigger character units, akin to Japanese or Russian, require considerably extra tokens to encode the identical quantity of knowledge as English. Consequently, LLMs are inclined to exhibit slower response occasions and better computational prices when processing such languages, making it tough to take care of constant efficiency throughout language pairs.
Researchers have explored numerous strategies to optimize LLM inference effectivity to beat these challenges. Strategies like information distillation and mannequin compression cut back the scale of enormous fashions by coaching smaller fashions to duplicate their outputs. One other promising approach is speculative decoding, which leverages an assistant mannequin—a “drafter”—to generate preliminary drafts of the goal LLM’s outputs. This drafter mannequin might be considerably smaller than the first LLM, lowering the computational price. Nevertheless, speculative decoding strategies are sometimes designed with a monolingual focus and don’t successfully generalize to multilingual eventualities, leading to suboptimal efficiency when utilized to numerous languages.
Researchers from KAIST AI and KT Company have launched an progressive method to multilingual speculative decoding, leveraging a pre-train-and-finetune technique. The method begins by pretraining the drafter fashions utilizing multilingual datasets on a basic language modeling job. Afterward, the fashions are finetuned for every particular language to raised align with the goal LLM’s predictions. This two-step course of permits the drafters to specialise in dealing with the distinctive traits of every language, leading to extra correct preliminary drafts. The researchers validated this method by experimenting with a number of languages and evaluating the drafters’ efficiency in translation duties involving German, French, Japanese, Chinese language, and Russian.
The methodology launched by the analysis crew entails a three-stage course of often known as the draft-verify-accept paradigm. Throughout the preliminary “draft” stage, the drafter mannequin generates potential future tokens primarily based on the enter sequence. The “confirm” stage compares these drafted tokens towards the predictions made by the first LLM to make sure consistency. If the drafter’s output aligns with the LLM’s predictions, the tokens are accepted; in any other case, they’re both discarded or corrected, and the cycle is repeated. This course of successfully reduces the first LLM’s computational burden by filtering out incorrect tokens early, permitting it to focus solely on verifying and refining the drafts offered by the assistant mannequin.
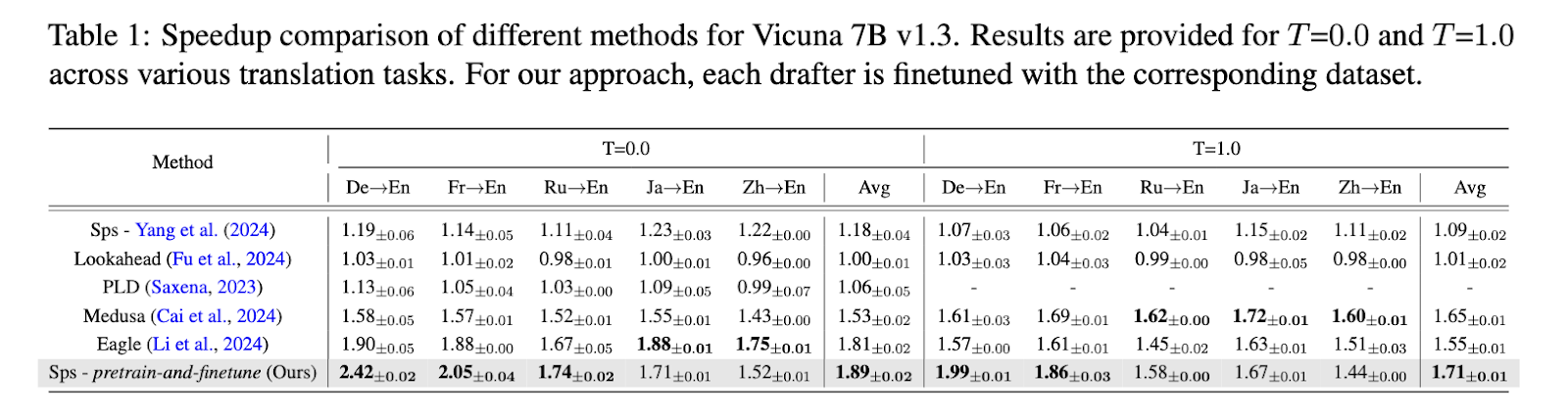
The efficiency of this method was totally examined, and spectacular outcomes have been produced. The analysis crew noticed a big discount in inference time, attaining a mean speedup ratio of 1.89 occasions in comparison with the usual autoregressive decoding strategies. On particular multilingual translation duties, the proposed technique recorded a speedup ratio of as much as 2.42 occasions when utilized to language pairs akin to German-to-English and French-to-English. These outcomes have been obtained utilizing the Vicuna 7B mannequin as the first LLM, with the drafter fashions being considerably smaller. For example, the German drafter mannequin comprised solely 68 million parameters, but it efficiently accelerated the interpretation course of with out compromising accuracy. Relating to GPT-4o judgment scores, the researchers reported that the specialised drafter fashions persistently outperformed present speculative decoding methods throughout a number of translation datasets.
Additional breakdowns of the speedup efficiency revealed that the specialised drafter fashions achieved a speedup ratio of 1.19 in deterministic settings (T=0) and a ratio of 1.71 in additional numerous sampling settings (T=1), demonstrating their robustness throughout completely different eventualities. Moreover, the outcomes indicated that the proposed pre-train-and-finetune technique considerably enhances the drafter’s capacity to foretell future tokens precisely, particularly in multilingual contexts. This discovering is essential for purposes that prioritize sustaining efficiency consistency throughout languages, akin to world buyer assist platforms and multilingual conversational AI programs.
The analysis introduces a novel technique for bettering LLM inference effectivity in multilingual purposes by means of specialised drafter fashions. The researchers efficiently enhanced the alignment between the drafter and the first LLM by using a two-step coaching course of, attaining substantial reductions in inference time. These outcomes recommend that focused pretraining and finetuning of drafters might be more practical than merely scaling up mannequin measurement, thereby setting a brand new benchmark for the sensible deployment of LLMs in numerous language settings.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 52k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report can be launched in late October/early November 2024. Click on right here to arrange a name!
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.