{kind=link}

Graph Neural Networks (GNNs) are a quickly advancing discipline in machine studying, particularly designed to research graph-structured information representing entities and their relationships. These networks have been broadly utilized in social community evaluation, suggestion methods, and molecular information interpretation functions. A subset of GNNs, Consideration-based Graph Neural Networks (AT-GNNs), employs consideration mechanisms to enhance predictive accuracy and interpretability by emphasizing essentially the most related relationships within the information. Nevertheless, their computational complexity poses vital challenges, notably in using GPUs effectively for coaching and inference.
One of many vital points in AT-GNN coaching is the inefficiency brought on by fragmented GPU operations. The computation includes a number of intricate steps, comparable to calculating consideration scores, normalizing these scores, and aggregating function information, which require frequent kernel launches and information motion. Present frameworks should adapt to real-world graph buildings’ heterogeneous nature, resulting in workload imbalance and decreased scalability. The issue is additional exacerbated by tremendous nodes—nodes with unusually giant neighbors—which pressure reminiscence sources and undermine efficiency.
Present GNN frameworks, comparable to PyTorch Geometric (PyG) and the Deep Graph Library (DGL), try to optimize operations utilizing kernel fusion and thread scheduling. Strategies like Seastar and dgNN have improved sparse operations and basic GNN workloads. Nevertheless, these strategies depend on mounted parallel methods that can’t dynamically adapt to the distinctive computational wants of AT-GNNs. For instance, they need assistance with mismatched thread utilization and totally exploit the advantages of kernel fusion when confronted with graph buildings containing tremendous nodes or irregular computational patterns.

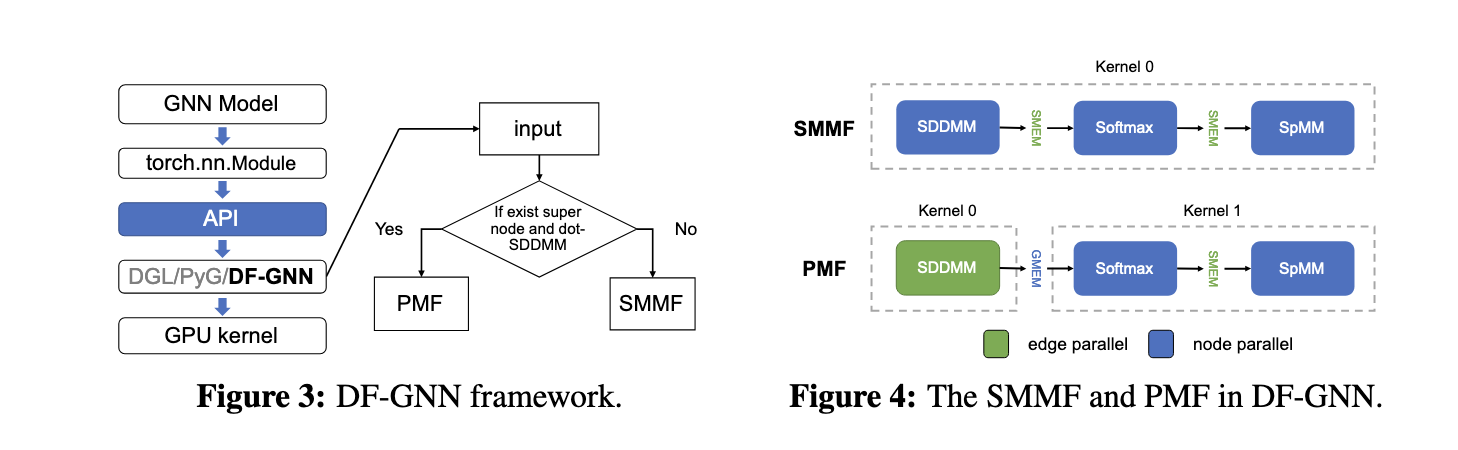
The analysis group from Shanghai Jiao Tong College and Amazon Net Companies proposed DF-GNN, a dynamic fusion framework explicitly designed to optimize the execution of AT-GNNs on GPUs. Built-in with the PyTorch framework, DF-GNN introduces an progressive bi-level thread scheduling mechanism that permits dynamic changes to string distribution. This flexibility ensures that operations like Softmax normalization and sparse matrix multiplications are executed with optimum thread utilization, considerably bettering efficiency. DF-GNN addresses inefficiencies related to static kernel fusion strategies by permitting totally different scheduling methods for every operation.
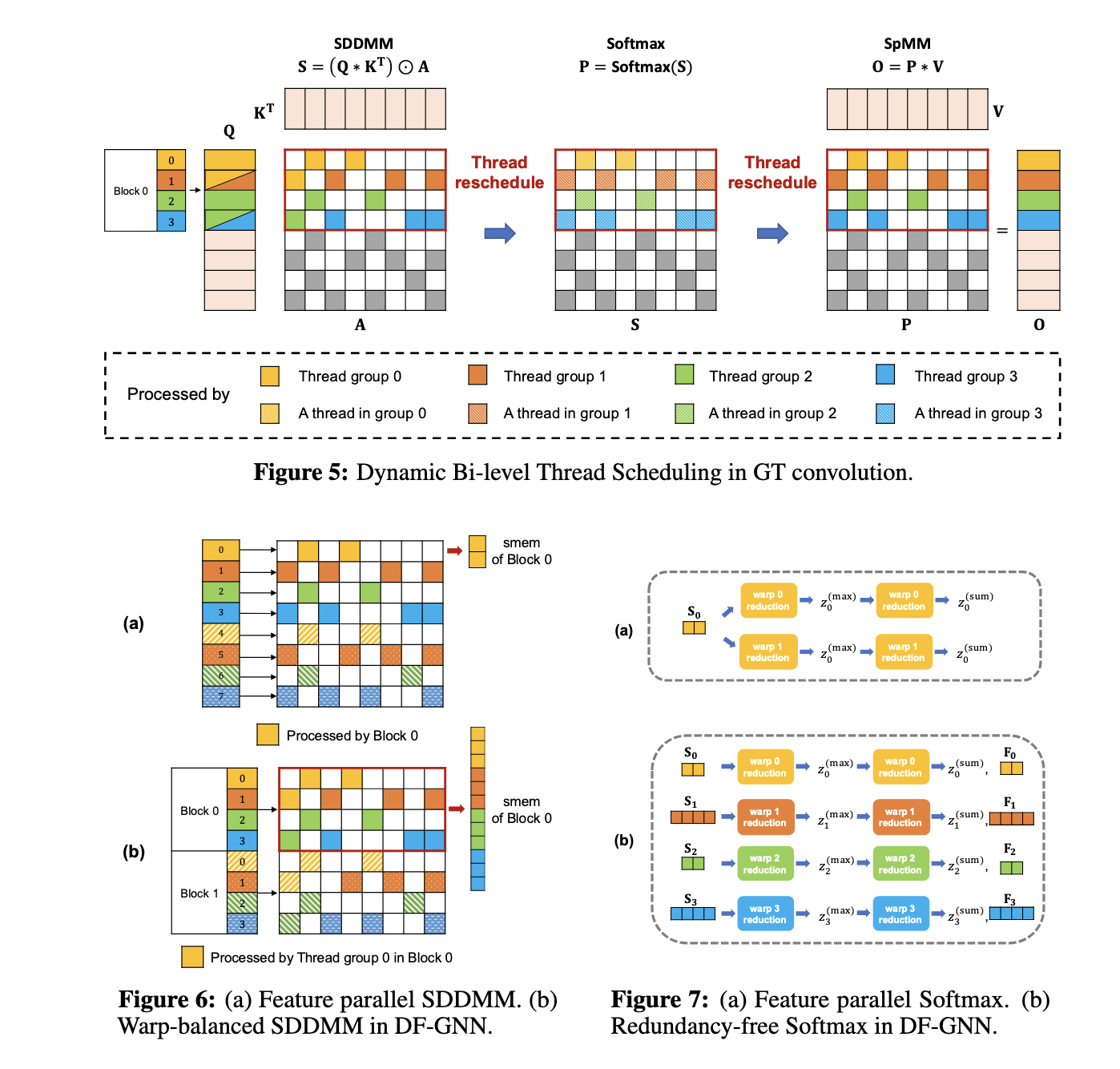
DF-GNN employs two main fusion methods: Shared Reminiscence Maximization Fusion (SMMF) and Parallelism Maximization Fusion (PMF). SMMF consolidates operations right into a single kernel, optimizing reminiscence utilization by storing intermediate ends in shared reminiscence, thereby lowering information motion. Conversely, PMF focuses on graphs with tremendous nodes, the place edge-parallel methods outperform node-parallel ones. Additional, the framework introduces tailor-made optimizations comparable to warp-balanced scheduling for edge computations, redundancy-free Softmax to eradicate repeated calculations, and vectorized reminiscence entry to reduce international reminiscence overhead. These options guarantee environment friendly ahead and backward computations processing, facilitating end-to-end coaching acceleration.
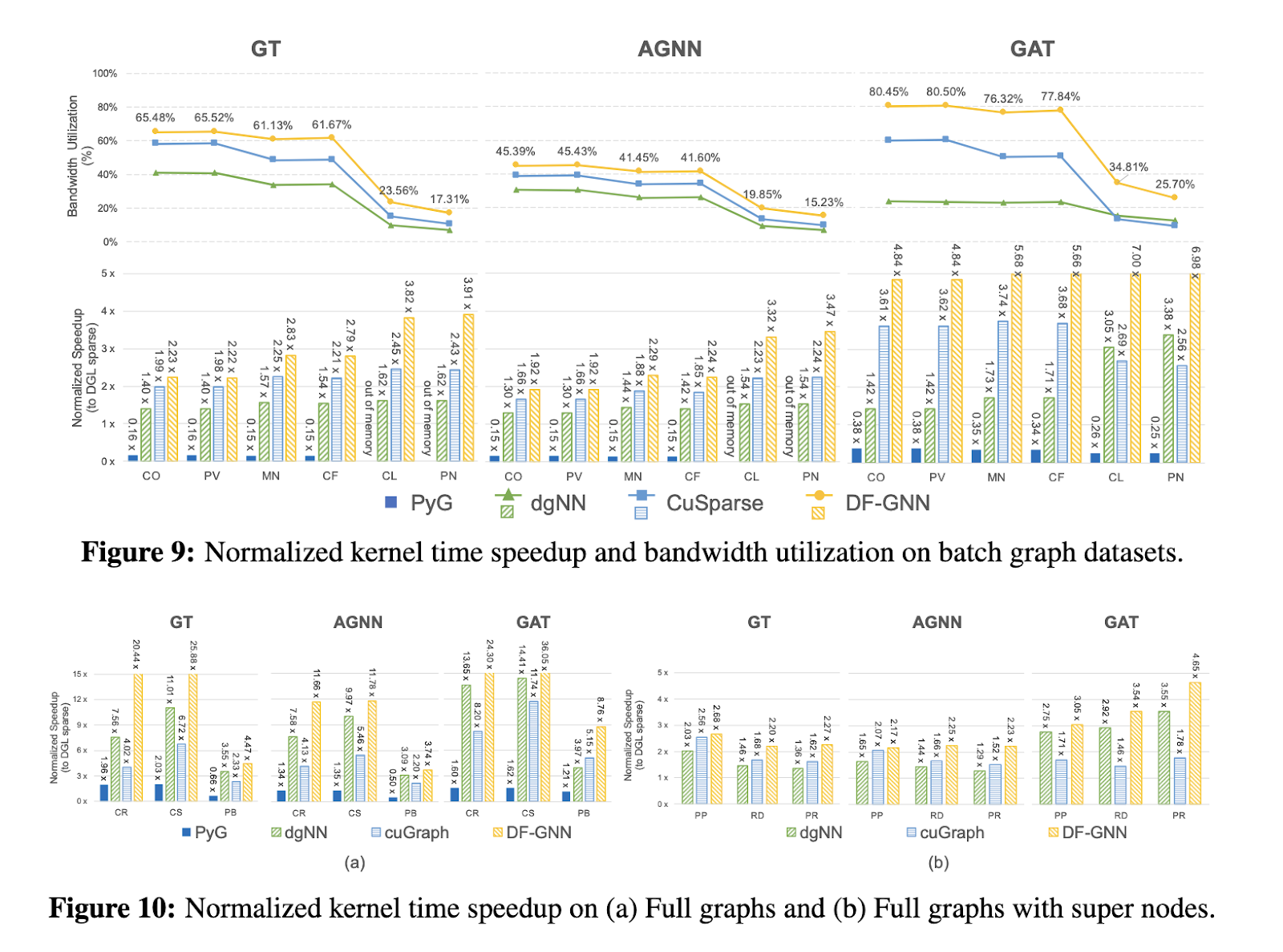
Intensive evaluations reveal DF-GNN’s outstanding efficiency positive factors. On full graph datasets like Cora and Citeseer, DF-GNN achieved a mean speedup of 16.3x in comparison with the DGL sparse library, with peak enhancements of as much as 7x on kernel operations. On batch graph datasets, together with high-degree graphs like PATTERN, it supplied a mean speedup of 3.7x, surpassing rivals like cuGraph and dgNN, which achieved solely 2.4x and 1.7x, respectively. Moreover, DF-GNN exhibited superior adaptability on tremendous node-laden datasets like Reddit and Protein, reaching a mean 2.8x speedup whereas sustaining strong reminiscence utilization. The bandwidth utilization of the framework remained persistently excessive, making certain optimum efficiency throughout graph sizes and buildings.
Past kernel-level enhancements, DF-GNN additionally accelerates end-to-end coaching workflows. In batch graph datasets, it achieved a mean speedup of 1.84x for full coaching epochs, with particular person ahead go enhancements reaching 3.2x. The speedup prolonged to 2.6x in full graph datasets, highlighting DF-GNN’s effectivity in dealing with numerous workloads. These outcomes underline the framework’s means to adapt dynamically to totally different computational situations, making it a flexible software for large-scale GNN functions.
In tackling the inherent inefficiencies of AT-GNN coaching on GPUs, DF-GNN introduces a well-rounded resolution that dynamically adapts to various computation and graph traits. By addressing essential bottlenecks comparable to reminiscence utilization and thread scheduling, this framework units a brand new benchmark in GNN optimization. Its integration with PyTorch and help for numerous datasets guarantee broad applicability, paving the best way for quicker, extra environment friendly graph-based studying methods.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.