{kind=link}

Scaling the dimensions of massive language fashions (LLMs) and their coaching information have now opened up emergent capabilities that enable these fashions to carry out extremely structured reasoning, logical deductions, and summary thought. These usually are not incremental enhancements over earlier instruments however mark the journey towards reaching Synthetic normal intelligence (AGI).
Coaching LLMs to motive nicely is without doubt one of the largest challenges of their creation. The approaches developed up to now can not practically grasp multi-step issues or these the place the answer have to be coherent and logical. A principal trigger is utilizing human-annotated coaching information, which is pricey and inherently restricted. With out sufficient annotated examples, these fashions fail to generalize throughout domains. This limitation presents a significant barrier to exploiting LLMs for extra advanced, real-world issues requiring superior reasoning.
Earlier strategies have discovered partial options to this drawback. Researchers have explored supervised fine-tuning, reinforcement studying from human suggestions (RLHF), and prompting methods comparable to chain of thought. Whereas these methods enhance LLMs’ capabilities, they’re nonetheless strongly depending on high quality datasets and important computational assets. Positive-tuning with reasoning examples or integrating step-by-step problem-solving trajectories has proved profitable; nonetheless, the approaches stay computationally intensive and usually are not usually scalable to mass purposes. Addressing these challenges, researchers started to pay attention extra on strategies for automated information development and reinforcement studying frameworks that make minimal calls for on human effort however maximize reasoning accuracy.
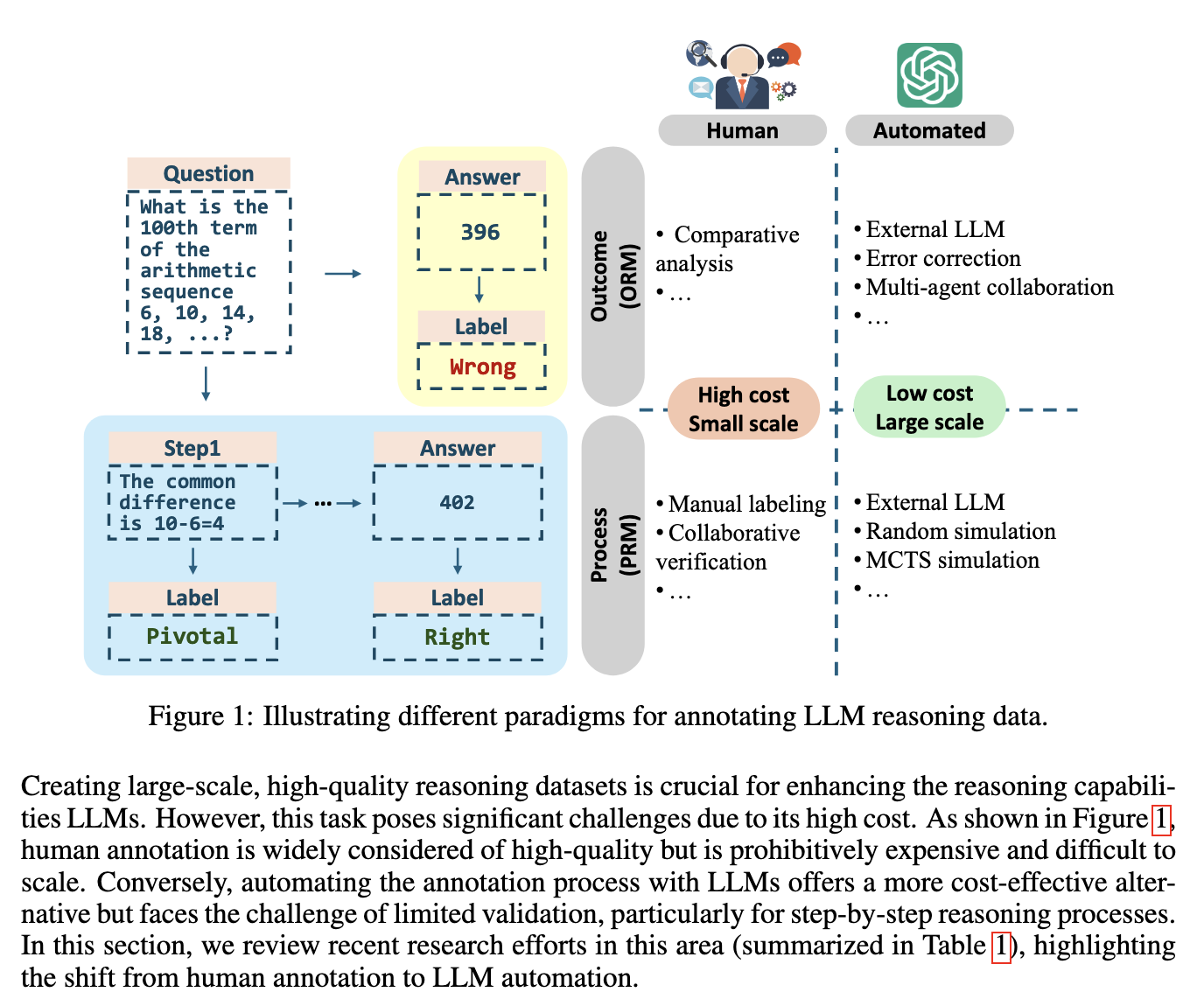
Researchers from Tsinghua College, Emory College, and HKUST launched a bolstered studying paradigm for coping with the challenges of coaching LLMs for reasoning duties. Their strategy makes use of Course of Reward Fashions (PRMs) to information intermediate steps inside the reasoning course of, considerably enhancing logical coherence and process efficiency. Utilizing a mixture of automated annotation with Monte Carlo simulations, the researchers have robotically generated high-quality reasoning information that doesn’t depend on guide intervention. This progressive methodology eliminates reliance on human annotations in regards to the information high quality however allows fashions to carry out superior reasoning via iterative studying cycles. The bolstered studying technique encompasses quite a lot of elements, together with PRM-guided automated reasoning trajectories and test-time reasoning.
PRMs present step-level rewards centered round intermediate steps slightly than last outcomes. The detailed steering ensures the mannequin can be taught incrementally and refine its understanding throughout coaching. Check-time scaling additional improves reasoning capabilities by dedicating extra computation assets for deliberate considering throughout inference. Strategies comparable to Monte Carlo Tree Search (MCTS) and self-refinement cycles are essential to this course of, permitting the fashions to simulate and consider a number of reasoning paths effectively. Efficiency outcomes present that these strategies work nicely.
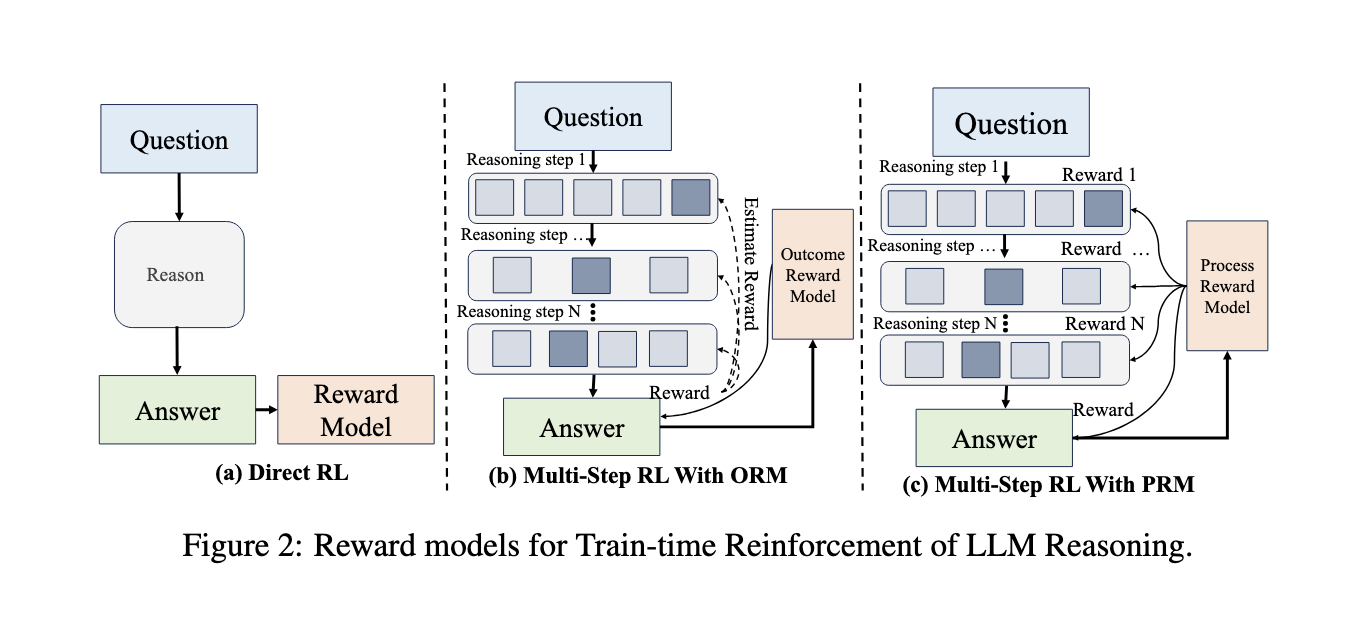
The fashions skilled utilizing this bolstered paradigm present important enchancment in reasoning benchmarks. The OpenAI o1 collection, one of the vital distinguished implementations of such methods, achieves an 83.3% success charge in aggressive programming duties by leveraging structured reasoning and logical deduction. The o1 mannequin has additionally demonstrated PhD-level efficiency in arithmetic, physics, and biology, scoring at gold-medal ranges within the Worldwide Arithmetic Olympiad. Systematic evaluations reveal that integrating step-level reasoning processes improves accuracy by 150% in comparison with earlier fashions. These outcomes emphasize the flexibility of the mannequin to decompose advanced issues, synthesize interdisciplinary data, and keep consistency in long-horizon duties.
The examine showcases the promising perspective that LLMs can understand as soon as endowed with superior reinforcement studying strategies and test-time scaling methods. The instances of information annotation and the discount of computational assets culminate in novel prospects for reasoning-focused AI methods. This work enhances the state of LLMs and establishes a basis for future exploration in creating fashions for dealing with extremely advanced duties with minimal human intervention.
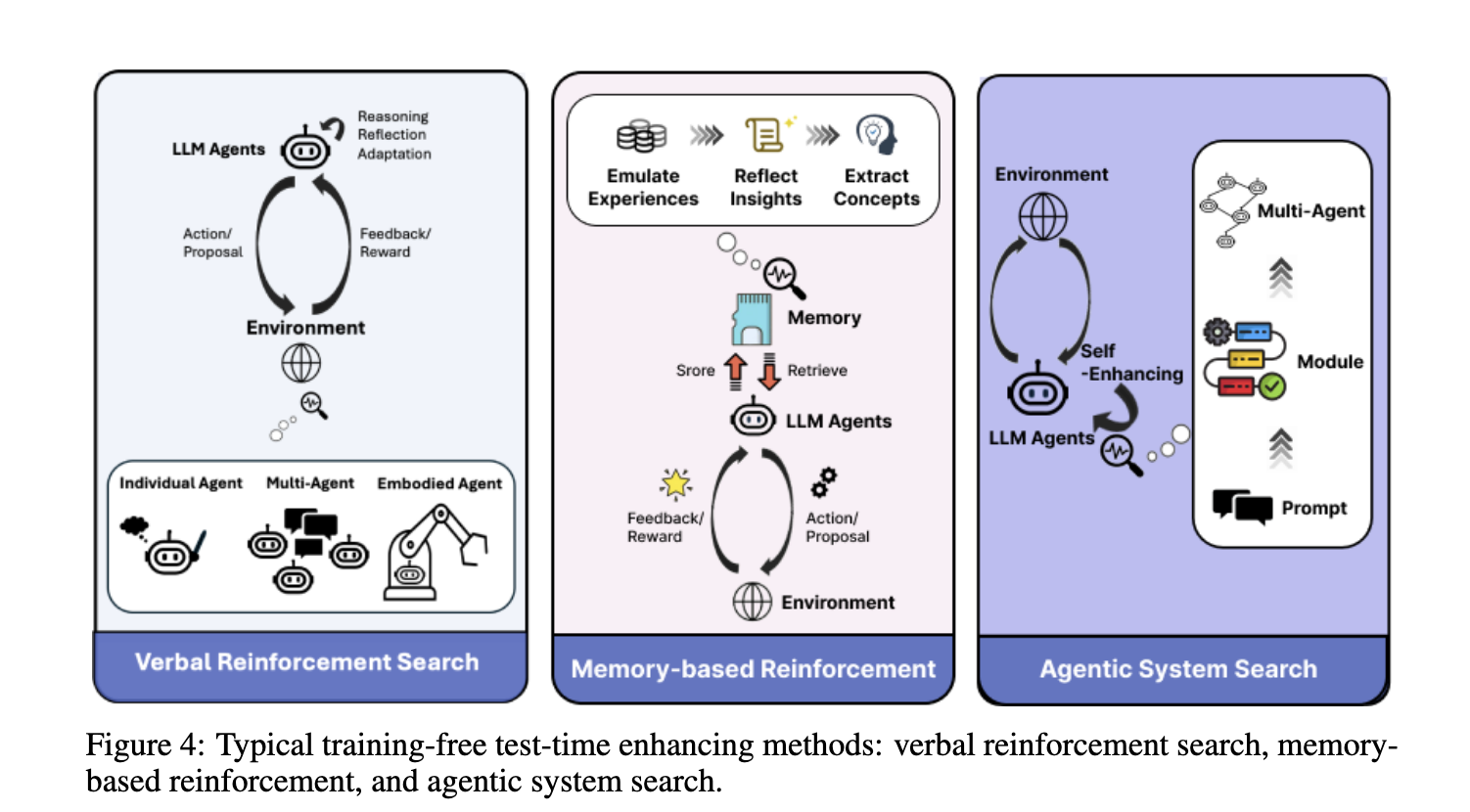
In abstract, analysis factors in the direction of the transformational power of the merge of reinforcement studying and check time scaling in constructing LLM. By addressing issues related to conventional trAIning strategies and deploying novel methods of progressive design and software, such a mannequin exhibits nice promise as an efficient creation for reasoning energy. The strategies offered by authors from Tsinghua College, Emory College, and HKUST are an unlimited step in pursuing the specified objective of well-established AI and human-like reasoning methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 65k+ ML SubReddit.
🚨 Suggest Open-Supply Platform: Parlant is a framework that transforms how AI brokers make choices in customer-facing situations. (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.