{kind=link}

Human beings possess innate extraordinary perceptual judgments, and when pc imaginative and prescient fashions are aligned with them, mannequin’s efficiency might be improved manifold. Varied attributes akin to scene structure, topic location, digicam pose, shade, perspective, and semantics assist us have a transparent image of the world and objects inside. The alignment of imaginative and prescient fashions with visible notion makes them delicate to those attributes and extra human-like. Whereas it has been established that molding imaginative and prescient fashions alongside the traces of human notion helps attain particular objectives in sure contexts, akin to picture era, their affect in general-purpose roles is but to be ascertained. Inferences drawn from analysis till now are nuanced with naive incorporation of human notion talents, badly harming fashions and distorting representations. It is usually argued whether or not the mannequin truly issues or whether or not the outcomes rely upon goal operate and coaching knowledge. Moreover, labels’ sensitivity and implications make the puzzle extra difficult. All these elements additional complicate understanding human perceptual talents concerning imaginative and prescient duties.
Researchers from MIT and UC Berkeley analyze this query in depth. Their paper “When Does Perceptual Alignment Profit Imaginative and prescient Representations?” investigates how a human imaginative and prescient perceptual aligned mannequin performs on numerous downstream visible duties. The authors finetuned state-of-the-art fashions ViTs on human similarity judgments for picture triplets and evaluated them throughout commonplace imaginative and prescient benchmarks. They introduce the concept of a second pretraining stage, which aligns the characteristic representations from giant imaginative and prescient fashions with human judgments earlier than making use of them to downstream duties.
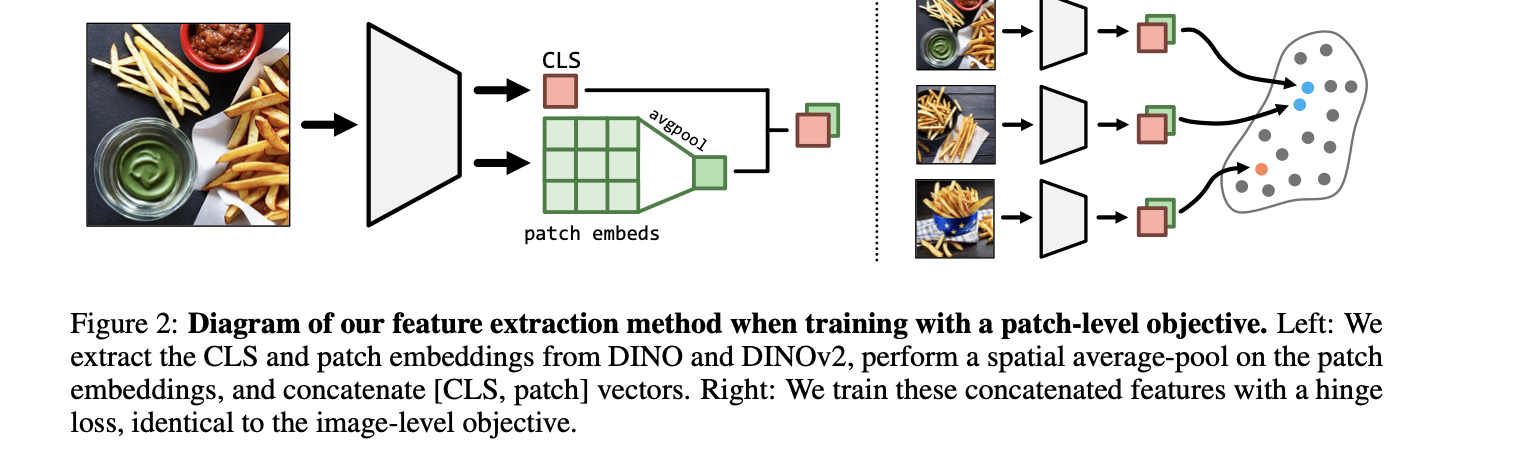
To grasp this additional, we first focus on the picture triplets talked about above. The authors used the famend artificial NIGHTS dataset with picture triplets annotated with pressured alternative human similarity judgments the place people selected two photos with the very best similarity to the primary picture. They formulate a patch alignment goal operate to catch spatial representations current in patch tokens and translate visible attributes from international annotations; as an alternative of computing the loss simply between international CLS tokens of Imaginative and prescient Transformer, they targeted CLS and pooled patch embeddings of ViT for this function to optimize native patch options collectively with the worldwide picture label.After this, numerous state-of-the-art Imaginative and prescient Transformer fashions, akin to DINO, CLIP, and so forth, have been finetuned on the above knowledge utilizing Low-Rank Adaptation (LoRA). The authors additionally integrated artificial photos in triplets with SynCLR to compute the efficiency delta.
These fashions carried out higher in imaginative and prescient duties than the bottom Imaginative and prescient Transformers. For Dense prediction duties, human-aligned fashions outperformed base fashions in over 75 % of the circumstances in case of each semantic segmentation and depth estimation. Shifting on within the realm of generative imaginative and prescient and LLMs, activity of Retrieval-Augmented Technology have been checked by humanizing a imaginative and prescient language mannequin. Outcomes once more favored prompts retrieved by human-aligned fashions as they boosted classification accuracy throughout domains. Additional, within the activity of object counting, these modified fashions outperformed the bottom in additional than 95 % of the circumstances. An identical pattern persists in occasion retrieval. These fashions failed on classification duties as a result of their excessive stage of semantic understanding.
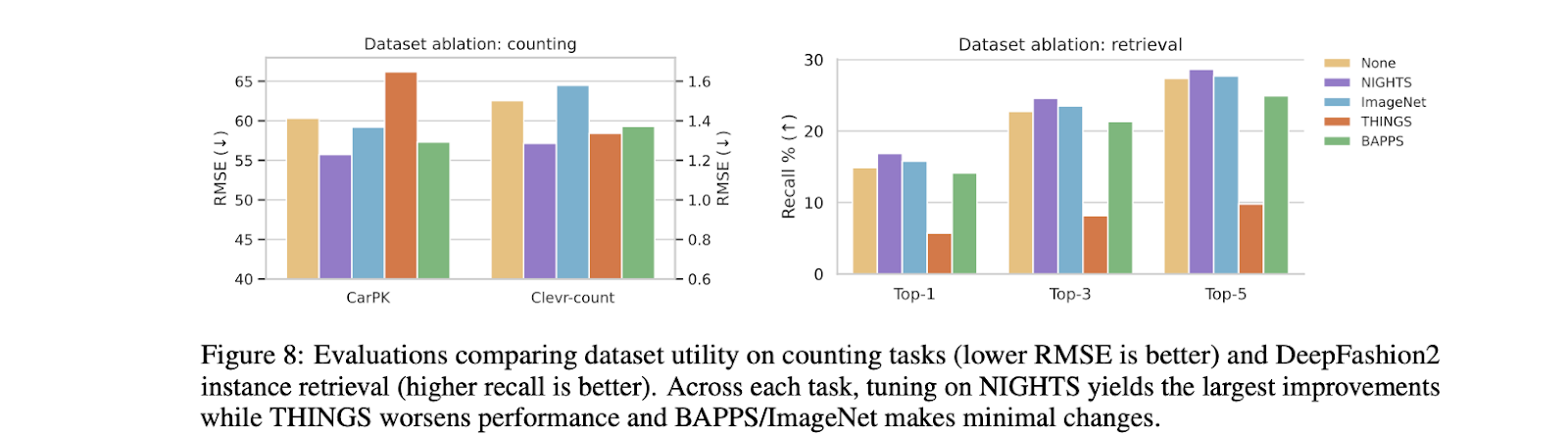
The authors additionally addressed whether or not coaching knowledge had a extra vital function than the coaching technique. For this function, extra datasets with picture triplets have been thought-about. The outcomes have been astonishing, with the NIGHTS dataset providing essentially the most appreciable affect and the remaining barely affected. The perceptual cues captured in NIGHTS play a vital function on this with its options like fashion, pose, shade, and object depend. Others failed as a result of lack of ability to seize required mid-level perceptual options.
General, human-aligned imaginative and prescient fashions carried out effectively generally. Nonetheless, these fashions are susceptible to overfitting and bias propagation. Thus, if the standard and variety of human annotation are ensured, visible intelligence could possibly be taken a notch above.
Try the Paper, GitHub, and Undertaking. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Adeeba Alam Ansari is presently pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by way of modern options pushed by empathy and a deep understanding of real-world challenges.