{kind=link}

The development of synthetic intelligence hinges on the supply and high quality of coaching information, significantly as multimodal basis fashions develop in prominence. These fashions depend on various datasets spanning textual content, speech, and video to allow language processing, speech recognition, and video content material technology duties. Nonetheless, the dearth of transparency relating to dataset origins and attributes creates important boundaries. Utilizing coaching information that’s geographically and linguistically skewed, inconsistently licensed, or poorly documented introduces moral, authorized, and technical challenges. Understanding the gaps in information provenance is crucial for advancing accountable and inclusive AI applied sciences.
AI methods face a vital subject in dataset illustration and traceability, which limits the event of unbiased and legally sound applied sciences. Present datasets typically rely closely on a number of web-based or synthetically generated sources. These embrace platforms like YouTube, which accounts for a big share of speech and video datasets, and Wikipedia, which dominates textual content information. This dependency leads to datasets failing to signify underrepresented languages and areas adequately. As well as, the unclear licensing practices of many datasets create authorized ambiguities, as greater than 80% of broadly used datasets carry some type of undocumented or implicit restrictions regardless of solely 33% being explicitly licensed for non-commercial use.
Makes an attempt to deal with these challenges have historically targeted on slim facets of information curation, equivalent to eradicating dangerous content material or mitigating bias in textual content datasets. Nonetheless, such efforts are sometimes restricted to single modalities and lack a complete framework to judge datasets throughout modalities like speech and video. Platforms internet hosting these datasets, equivalent to HuggingFace or OpenSLR, typically lack the mechanisms to make sure metadata accuracy or implement constant documentation practices. This fragmented strategy underscores the pressing want for a scientific audit of multimodal datasets that holistically considers their sourcing, licensing, and illustration.
To shut this hole, researchers from the Information Provenance Initiative carried out the most important longitudinal audit of multimodal datasets, analyzing practically 4,000 public datasets created between 1990 and 2024. The audit spanned 659 organizations from 67 international locations, protecting 608 languages and practically 1.9 million hours of speech and video information. This intensive evaluation revealed that web-crawled and social media platforms now account for many coaching information, with artificial sources additionally quickly rising. The research highlighted that whereas solely 25% of textual content datasets have explicitly restrictive licenses, practically all content material sourced from platforms like YouTube or OpenAI carries implicit non-commercial constraints, elevating questions on authorized compliance and moral use.
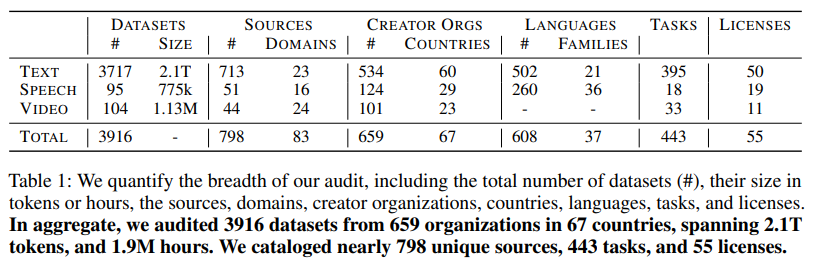
The researchers utilized a meticulous methodology to annotate datasets, tracing their lineage again to sources. This course of uncovered important inconsistencies in how information is licensed and documented. As an illustration, whereas 96% of textual content datasets embrace business licenses, over 80% of their supply supplies impose restrictions that aren’t carried ahead within the dataset’s documentation. Equally, video datasets extremely relied on proprietary or restricted platforms, with 71% of video information originating from YouTube alone. Such findings underscore the challenges practitioners face in accessing information responsibly, significantly when datasets are repackaged or re-licensed with out preserving their unique phrases.
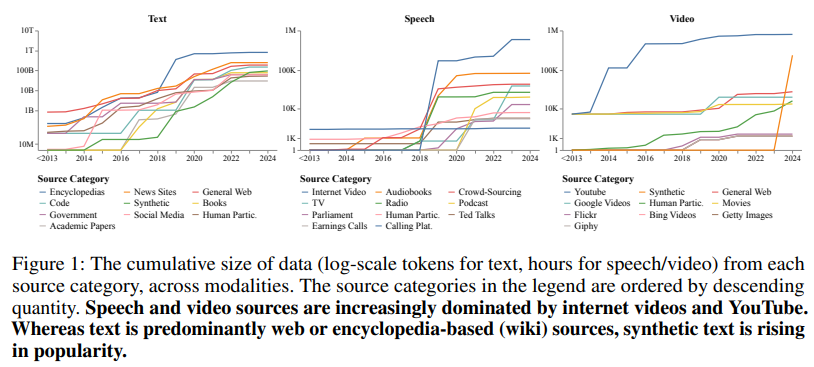
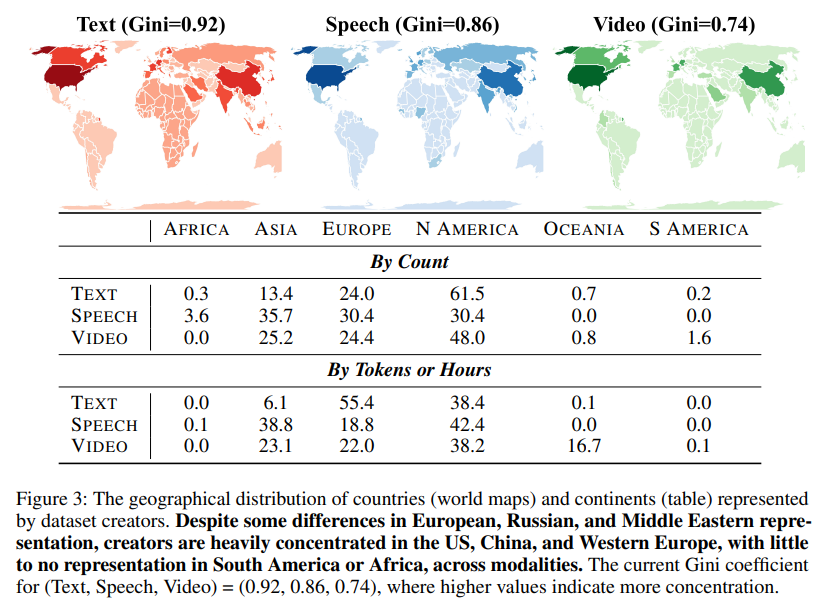
Notable findings from the audit embrace the dominance of web-sourced information, significantly for speech and video. YouTube emerged as essentially the most important supply, contributing practically 1 million hours to every speech and video content material, surpassing different sources like audiobooks or films. Artificial datasets, whereas nonetheless a smaller portion of general information, have grown quickly, with fashions like GPT-4 contributing considerably. The audit additionally revealed stark geographical imbalances. North American and European organizations accounted for 93% of textual content information, 61% of speech information, and 60% of video information. Compared, areas like Africa and South America collectively represented lower than 0.2% throughout all modalities.
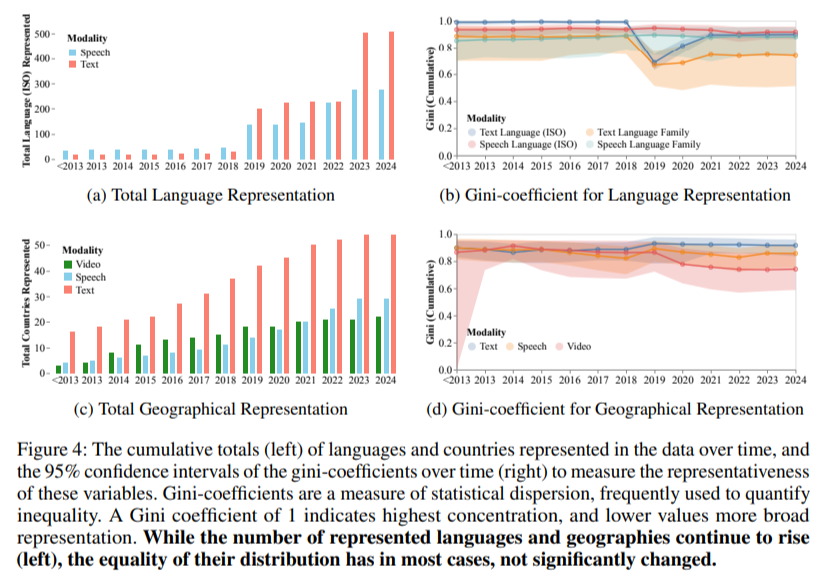
Geographical and linguistic illustration stays a persistent problem regardless of nominal will increase in variety. Over the previous decade, the variety of languages represented in coaching datasets has grown to over 600, but measures of equality in illustration have proven no important enchancment. The Gini coefficient, which measures inequality, stays above 0.7 for geographical distribution and above 0.8 for language illustration in textual content datasets, highlighting the disproportionate focus of contributions from Western international locations. For speech datasets, whereas illustration from Asian international locations like China and India has improved, African and South American organizations proceed to lag far behind.
The analysis supplies a number of vital takeaways, providing precious insights for builders and policymakers:
- Over 70% of speech and video datasets are derived from internet platforms like YouTube, whereas artificial sources have gotten more and more fashionable, accounting for practically 10% of all textual content information tokens.
- Whereas solely 33% of datasets are explicitly non-commercial, over 80% of supply content material is restricted. This mismatch complicates authorized compliance and moral use.
- North American and European organizations dominate dataset creation, with African and South American contributions at lower than 0.2%. Linguistic variety has grown nominally however stays concentrated in lots of dominant languages.
- GPT-4, ChatGPT, and different fashions have considerably contributed to the rise of artificial datasets, which now signify a rising share of coaching information, significantly for inventive and generative duties.
- The shortage of transparency and chronic Western-centric biases name for extra rigorous audits and equitable practices in dataset curation.
In conclusion, this complete audit sheds gentle on the rising reliance on web-crawled and artificial information, the persistent inequalities in illustration, and the complexities of licensing in multimodal datasets. By figuring out these challenges, the researchers present a roadmap for creating extra clear, equitable, and accountable AI methods. Their work underscores the necessity for continued vigilance and measures to make sure that AI serves various communities pretty and successfully. This research is a name to motion for practitioners, policymakers, and researchers to deal with the structural inequities within the AI information ecosystem and prioritize transparency in information provenance.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.