{kind=link}

Giant language fashions (LLMs) have revolutionized the sphere of synthetic intelligence by performing a variety of duties throughout completely different domains. These fashions are anticipated to work seamlessly in a number of languages, fixing complicated issues whereas guaranteeing security. Nonetheless, the problem lies in sustaining security with out compromising efficiency, particularly in multilingual settings. As AI applied sciences turn into globally pervasive, addressing the security issues that come up when fashions skilled predominantly in English are deployed throughout numerous languages and cultural contexts is important.
The core difficulty revolves round balancing efficiency and security in LLMs. Security issues come up when fashions produce biased or dangerous outputs, significantly in languages with restricted coaching information. Usually, the strategies to handle this contain fine-tuning fashions on blended datasets, combining general-purpose and security duties. Nonetheless, these approaches can result in undesirable trade-offs. In lots of instances, growing the security measures in LLMs can negatively affect their capability to carry out effectively on basic duties. The problem, due to this fact, is to develop an method that improves each security and efficiency in multilingual LLMs with out requiring huge quantities of task-specific information.
Present strategies used to steadiness these goals usually depend on data-mixing methods. This includes making a single mannequin by coaching it on numerous datasets from numerous duties and languages. Whereas these strategies assist obtain some degree of multitasking capability, they can lead to under-addressed security issues in languages apart from English. As well as, the complexity of managing quite a few duties concurrently usually reduces the mannequin’s capability to carry out effectively in any of them. The shortage of specialised consideration to every job and language limits the mannequin’s capability to handle security and basic efficiency successfully.
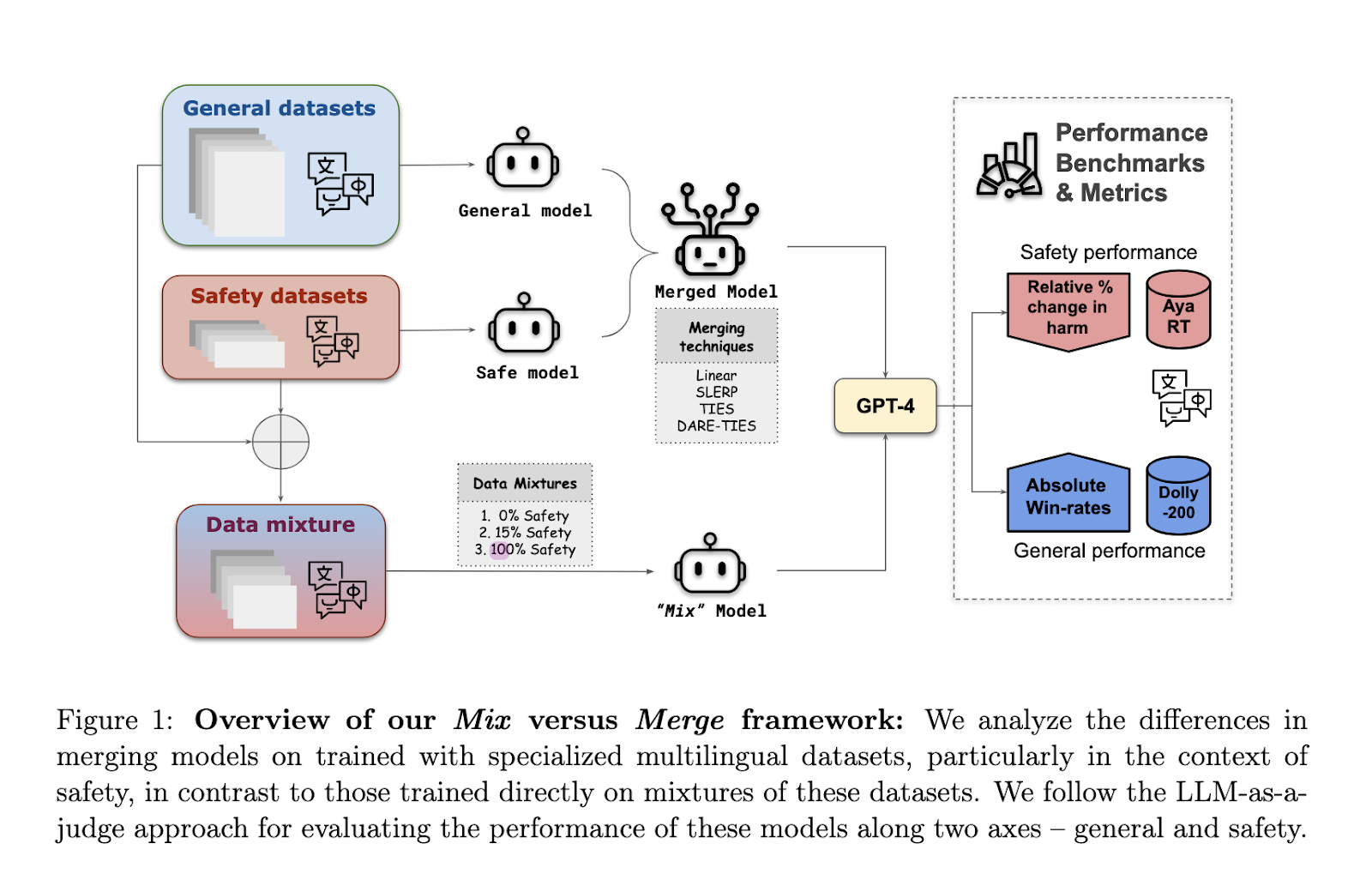
To beat these limitations, researchers from Cohere AI have launched an modern method based mostly on mannequin merging. As a substitute of counting on the standard methodology of knowledge mixing, the place a single mannequin is skilled throughout a number of duties and languages, the researchers suggest merging separate fashions which were independently fine-tuned for particular duties and languages. This methodology permits for higher specialization inside every mannequin earlier than merging them right into a unified system. By doing so, the fashions retain their distinctive capabilities, providing enhancements in security and basic efficiency throughout numerous languages.
The merging course of is carried out by means of a number of methods. The first methodology launched by the researchers is Spherical Linear Interpolation (SLERP), which permits for clean transitions between completely different fashions by mixing their weights alongside a spherical path. This method ensures that the distinctive properties of every mannequin are preserved, permitting the merged mannequin to deal with numerous duties with out compromising security or efficiency. One other methodology, TIES (Job Interference Elimination Technique), focuses on resolving conflicts between task-specific fine-tuned fashions by adjusting mannequin parameters to align higher. The merging methods additionally embrace linear merging and DARE-TIES, which additional improve the robustness of the ultimate mannequin by addressing interference points and guaranteeing that the mannequin parameters contribute positively to efficiency.
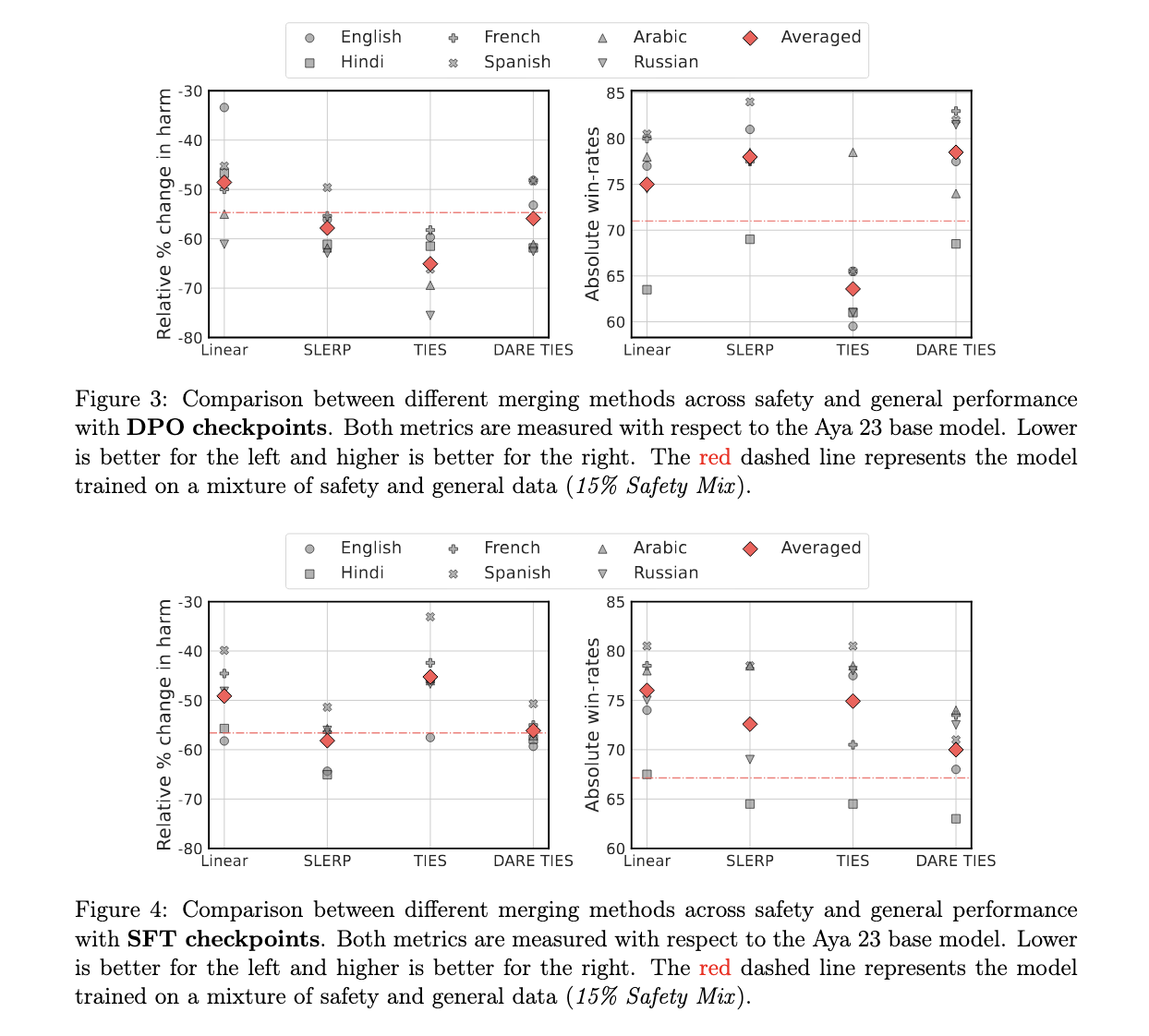
The outcomes of this analysis present clear enhancements in each basic efficiency and security. For example, SLERP merging achieved a formidable 7% enchancment normally efficiency and a 3.1% discount in dangerous outputs in comparison with conventional information mixing strategies. Then again, TIES merging delivered a outstanding 10.4% discount in dangerous outputs, though it barely diminished basic efficiency by 7.4%. These numbers point out that mannequin merging considerably outperforms information mixing when balancing security and efficiency. Furthermore, when fashions have been fine-tuned for particular person languages and merged, the researchers noticed as much as a 6.6% discount in dangerous outputs and a 3.8% enchancment normally benchmarks, additional proving the effectiveness of language-specific mannequin merging over multilingual mannequin coaching.
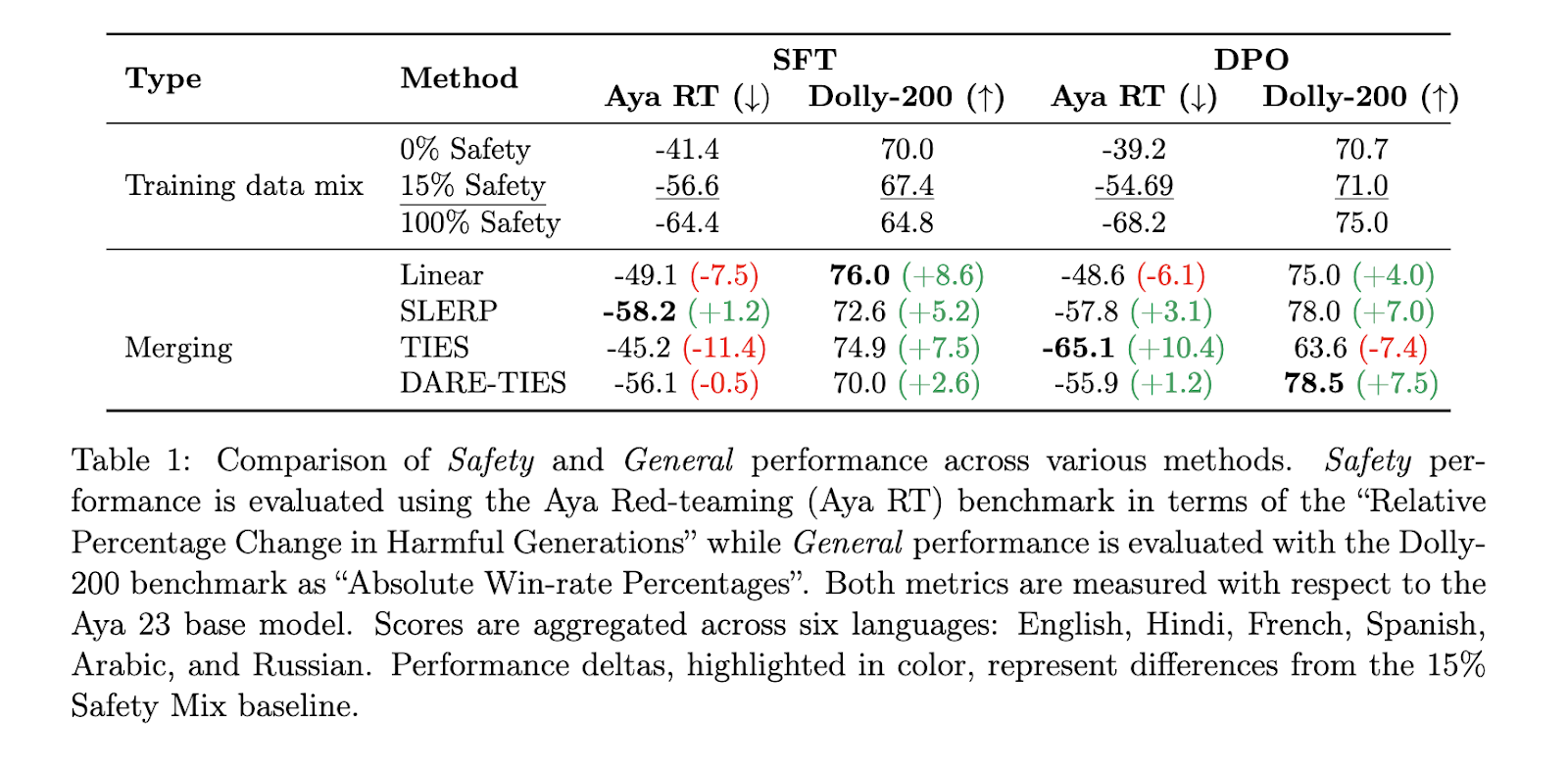
The efficiency enhancements have been significantly noteworthy in some languages, with Russian exhibiting the very best discount in dangerous generations (as much as 15%) utilizing TIES merging. Spanish, in the meantime, exhibited a ten% enchancment normally efficiency with each SLERP and TIES strategies. Nonetheless, not all languages profit equally. English fashions, for instance, confirmed a decline in security efficiency when merged, highlighting the variability in outcomes based mostly on the underlying coaching information and merging technique.
The analysis offers a complete framework for constructing safer and more practical multilingual LLMs. By merging fashions fine-tuned for security and efficiency on particular duties and languages, the researchers from Cohere AI demonstrated a extra environment friendly and scalable methodology for bettering LLMs. The method reduces the necessity for large quantities of coaching information and permits for higher alignment of security protocols throughout languages, which is critically wanted in at the moment’s AI panorama.
In conclusion, mannequin merging represents a promising step ahead in addressing balancing efficiency and security challenges in LLMs, significantly in multilingual settings. This methodology considerably improves LLMs’ capability to ship protected and high-quality outputs, particularly when utilized to low-resource languages. As AI evolves, methods like mannequin merging may turn into important instruments for guaranteeing that AI techniques are strong and protected throughout numerous linguistic and cultural contexts.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Fantastic-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.