{kind=link}

Do you utilize GPT-4o, GPT-4o Mini, or GPT-3.5 Turbo? Understanding the prices related to every mannequin is essential for managing your price range successfully. By monitoring utilization on the process degree, you get an in depth perspective of prices related along with your venture. Let’s discover methods to monitor and handle your OpenAI API Worth utilization effectively within the following sections.

OpenAI API Worth
These are the costs per 1 million tokens:
| Mannequin | Enter Tokens (per 1M) | Output Tokens (per 1M) |
| GPT-3.5-Turbo | $3.00 | $6.00 |
| GPT-4 | $30.00 | $60.00 |
| GPT-4o | $2.50 | $10.00 |
| GPT-4o-mini | $0.15 | $0.60 |
- GPT-4o-mini is essentially the most inexpensive choice, costing considerably lower than the opposite fashions, with a context size of 16k, making it splendid for light-weight duties that don’t require processing giant quantities of enter or output tokens.
- GPT-4 is the costliest mannequin, with a context size of 32k, offering unmatched efficiency for duties requiring intensive input-output interactions or complicated reasoning.
- GPT-4o presents a balanced choice for high-volume functions, combining a decrease value with a bigger context size of 128k, making it appropriate for duties requiring detailed, high-context processing at scale.
- GPT-3.5-Turbo, with a context size of 16k, just isn’t a multimodal choice and solely processes textual content enter, providing a center floor by way of value and performance.
For decreased prices you’ll be able to think about Batch API which is charged 50% much less on each Enter Tokens and Output Tokens. Cached Inputs additionally assist cut back prices:
Cached Inputs: Cached inputs consult with tokens which were beforehand processed by the mannequin, permitting for quicker and cheaper reuse in subsequent requests. It reduces Enter Tokens prices by 50%.
Batch API: The Batch API permits for submitting a number of requests collectively, processing them in bulk and offers the response inside a 24-hour window.
Prices in Precise Utilization
You possibly can at all times test your OpenAI dashboard to trace your utilization and test exercise to see the variety of requests despatched: OpenAI Platform.
Let’s concentrate on monitoring it per request to get a task-level thought. Let’s ship a number of prompts to the fashions and estimate the fee incurred.
from openai import OpenAI
# Initialize the OpenAI consumer
consumer = OpenAI(api_key = "API-KEY")
# Fashions and prices per 1M tokens
fashions = [
{"name": "gpt-3.5-turbo", "input_cost": 3.00, "output_cost": 6.00},
{"name": "gpt-4", "input_cost": 30.00, "output_cost": 60.00},
{"name": "gpt-4o", "input_cost": 2.50, "output_cost": 10.00},
{"name": "gpt-4o-mini", "input_cost": 0.15, "output_cost": 0.60}
]
# A query to ask the fashions
query = "What is the largest metropolis in India?"
# Initialize an empty listing to retailer outcomes
outcomes = []
# Loop by means of every mannequin and ship the request
for mannequin in fashions:
completion = consumer.chat.completions.create(
mannequin=mannequin["name"],
messages=[
{"role": "user", "content": question}
]
)
# Extract the response content material and token utilization from the completion
response_content = completion.decisions[0].message.content material
input_tokens = completion.utilization.prompt_tokens
output_tokens = completion.utilization.completion_tokens
total_tokens = completion.utilization.total_tokens
model_name = completion.mannequin
# Calculate the fee based mostly on token utilization (value per million tokens)
input_cost = (input_tokens / 1_000_000) * mannequin["input_cost"]
output_cost = (output_tokens / 1_000_000) * mannequin["output_cost"]
total_cost = input_cost + output_cost
# Append the end result to the outcomes listing
outcomes.append({
"Mannequin": model_name,
"Enter Tokens": input_tokens,
"Output Tokens": output_tokens,
"Complete value": total_cost,
"Response": response_content
})
import pandas as pd
# show the ends in a desk format
df = pd.DataFrame(outcomes)
df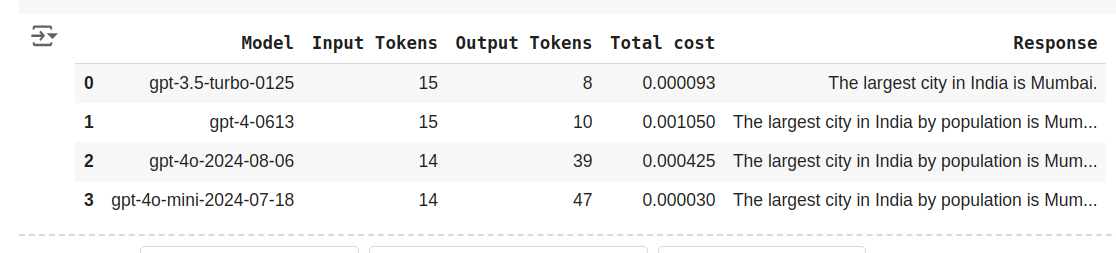
The prices are $ 0.000093, $ 0.001050, $ 0.000425, $ 0.000030 for GPT-3.5-Turbo, GPT-4, GPT-4o and GPT-4o-mini respectively. The fee relies on each enter tokens and output tokens and we are able to see that regardless of GPT-4o-mini producing 47 tokens for the query “What’s the most important metropolis in India” it’s the most affordable amongst all the opposite fashions right here.
Be aware: Tokens are a sequence of characters and so they’re not precisely phrases and see that the enter tokens are completely different regardless of the immediate being the identical as they use a unique tokenizer.
The way to cut back prices?
Set an higher restrict on Max Tokens
query = "Clarify VAE?"
completion = consumer.chat.completions.create(
mannequin="gpt-4o-mini-2024-07-18",
messages=[
{"role": "user", "content": question}
],
max_tokens=50 # Set the specified higher restrict for output tokens
)
print("Output Tokens: ",completion.utilization.completion_tokens, "n")
print("Output: ", completion.decisions[0].message.content material)Limiting the output tokens helps cut back prices and this may also let the mannequin focus extra on the reply. However selecting an acceptable quantity for the restrict is essential right here.
Batch API
Utilizing Batch API reduces prices by 50% on each Enter Tokens and Output Tokens, the one trade-off right here is that it takes a while to get the responses (It may be as much as 24 hours relying on the variety of requests).
query="What's a tokenizer"Making a dictionary with request parameters for a POST request.
input_dict = {
"custom_id": f"request-1",
"technique": "POST",
"url": "/v1/chat/completions",
"physique": {
"mannequin": "gpt-4o-mini-2024-07-18",
"messages": [
{
"role": "user",
"content": question
}
],
"max_tokens": 100
}
}Writing the serialized input_dict to a JSONL file.
import json
request_file = "/content material/batch_request_file.jsonl"
with open(request_file, 'w') as f:
f.write(json.dumps(input_dict))
f.write('n')
print(f"Efficiently wrote a dictionary to {request_file}.")Sending a Batch Request utilizing ‘consumer.batches.create’
from openai import OpenAI
consumer = OpenAI(api_key = "API-KEY")
batch_input_file = consumer.information.create(
file=open(request_file, "rb"),
objective="batch"
)
batch_input_file_id = batch_input_file.id
input_batch = consumer.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "GPT4o-Mini-Take a look at"
}
)Checking the standing of the batch, it may well take as much as 24 hours to get the response. If the variety of requests or batches are much less it ought to be fast sufficient (like on this instance).
status_response = consumer.batches.retrieve(input_batch.id)
print(input_batch.id,status_response.standing, status_response.request_counts)
accomplished BatchRequestCounts(accomplished=1, failed=0, whole=1)
if status_response.standing == 'accomplished':
output_file_id = status_response.output_file_id
# Retrieve the content material of the output file
output_response = consumer.information.content material(output_file_id)
output_content = output_response.content material
# Write the content material to a file
with open('/content material/batch_output.jsonl', 'wb') as f:
f.write(output_content)
print("Batch outcomes saved to batch_output.jsonl")That is the response I obtained within the JSONL file:
"content material": "A tokenizer is a instrument or course of utilized in pure language
processing (NLP) and textual content evaluation that splits a stream of textual content into
smaller, manageable items known as tokens. These tokens can characterize numerous
information models akin to phrases, phrases, symbols, or different significant parts in
the textual content.nnThe technique of tokenization is essential for numerous NLP
functions, together with:nn1. **Textual content Evaluation**: Breaking down textual content into
elements makes it simpler to investigate, permitting for duties like frequency
evaluation, sentiment evaluation, and extra"
Conclusion
Understanding and managing ChatGPT API Price is crucial for maximizing the worth of OpenAI’s fashions in your initiatives. By analyzing token utilization and model-specific pricing, you can also make knowledgeable selections to stability efficiency and affordability. Among the many choices, GPT-4o-mini is an economical mannequin for many of the duties, whereas GPT-4o presents a robust but economical various for high-volume functions because it has an even bigger context size at 128k. Batch API is one other useful various to assist save prices for bulk processing for non-urgent duties.
Additionally in case you are on the lookout for a Generative AI course on-line then discover: GenAI Pinnacle Program
Ceaselessly Requested Questions
Ans. You possibly can cut back prices by setting an higher restrict on Max Tokens, utilizing Batch API for bulk processing
Ans. Set a month-to-month price range in your billing settings to cease requests as soon as the restrict is reached. You can even set an e-mail alert for whenever you method your price range and monitor utilization by means of the monitoring dashboard.
Ans. Sure, Playground utilization is taken into account the identical as common API utilization.
Ans. Examples embrace gpt-4-vision-preview, gpt-4-turbo, gpt-4o and gpt-4o-mini which course of and analyze each textual content and pictures for numerous duties.
I am a tech fanatic, graduated from Vellore Institute of Know-how. I am working as a Knowledge Science Trainee proper now. I’m very a lot enthusiastic about Deep Studying and Generative AI.