{kind=link}

Retrieval Augmented Era (RAG) is the highest use case for Databricks clients who need to customise AI workflows on their very own information. The tempo of huge language mannequin releases is extremely quick, and lots of of our clients are searching for up-to-date steering on the best way to construct the perfect RAG pipelines. In a earlier weblog put up, we ran over 2,000 lengthy context RAG experiments on 13 common open supply and industrial LLMs to uncover their efficiency on numerous domain-specific datasets. After we launched this weblog put up, we acquired plenty of enthusiastic requests to additional benchmark extra state-of-the-art fashions.
In September, OpenAI launched a brand new o1 household of highly effective massive language fashions (LLMs) that depend on additional inference-time compute to reinforce “reasoning.” We have been wanting to see how these new fashions carried out on our inside benchmarks; does extra inference-time compute result in vital enhancements?
We designed our analysis suite to stress-test RAG workflows with very lengthy contexts. The Google Gemini 1.5 fashions are the one state-of-the-art fashions that boast a context size of two million tokens, and we have been excited to see how the Gemini 1.5 fashions (launched in Might) held up. 2 million tokens is roughly equal to a small corpus of tons of of paperwork; on this state of affairs, builders constructing customized AI programs might in precept skip retrieval and RAG completely and easily embrace the whole corpus within the LLM context window. Can these excessive lengthy context fashions actually change retrieval?
On this followup weblog put up, we benchmark new state-of-the-art fashions OpenAI o1-preview, o1-mini, in addition to Google Gemini 1.5 Professional, Gemini 1.5 Flash (Might launch). After operating these further experiments, we discovered that:
- OpenAI o1 fashions present a constant enchancment over Anthropic and Google fashions on our lengthy context RAG Benchmark as much as 128k tokens.
- Regardless of decrease efficiency than the SOTA OpenAI and Anthropic fashions, Google Gemini 1.5 fashions have constant RAG efficiency at excessive context lengths of as much as 2 million tokens.
- Fashions fail on lengthy context RAG in extremely distinct methods
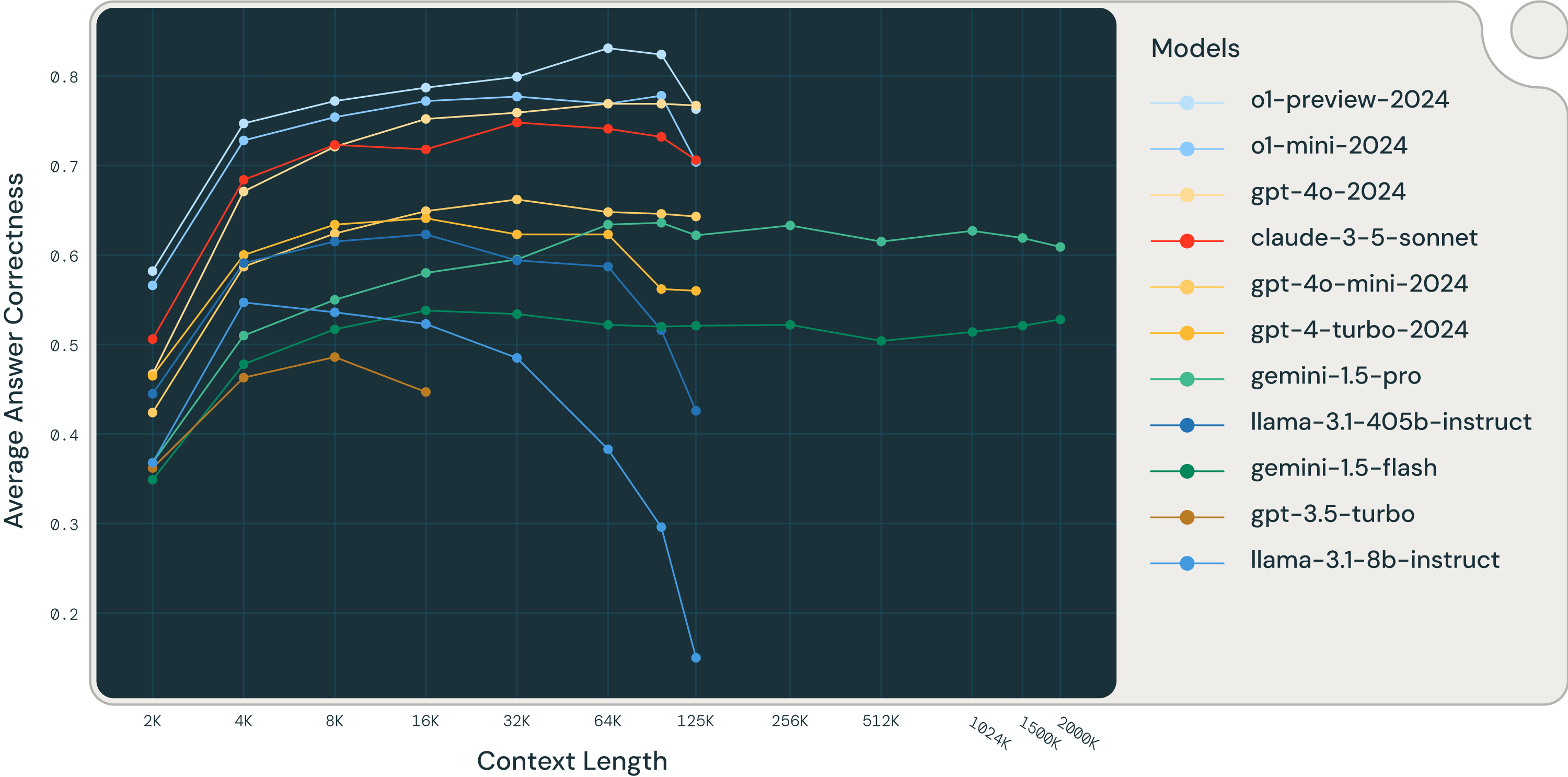
Recap of our earlier weblog put up:
We designed our inside benchmark with a purpose to take a look at the lengthy context, end-to-end RAG capabilities of the state-of-the-art LLMs. The fundamental setup is as follows:
- Retrieve doc chunks from a vector database with paperwork embedded utilizing OpenAI’s text-embedding-3-large. Paperwork are cut up into 512 token chunks with a stride of 256 tokens.
- Range the full variety of tokens by together with extra retrieved paperwork within the context window. We fluctuate the full variety of tokens from 2,000 tokens as much as 2,000,000 tokens.
- The system has to appropriately reply questions primarily based on the retrieved paperwork. The reply is judged by a calibrated LLM-as-a-judge utilizing GPT-4o.
Our inside benchmark consists of three separate curated datasets: Databricks DocsQA, FinanceBench, and Pure Questions (NQ).
In our earlier weblog put up Lengthy Context RAG Efficiency of LLMs, we discovered that:
- Retrieving extra paperwork can certainly be helpful: Retrieving extra data for a given question will increase the probability that the best data is handed on to the LLM. Fashionable LLMs with lengthy context lengths can benefit from this and thereby enhance the general RAG system.
- Longer context just isn’t at all times optimum for RAG: Most mannequin efficiency decreases after a sure context measurement. Notably, Llama-3.1-405b efficiency begins to lower after 32k tokens, GPT-4-0125-preview begins to lower after 64k tokens, and just a few fashions can keep constant lengthy context RAG efficiency on all datasets.
- Fashions fail at lengthy context duties in extremely distinct methods: We performed deep dives into the long-context efficiency of DBRX and Mixtral and recognized distinctive failure patterns corresponding to rejecting resulting from copyright issues or at all times summarizing the context. Most of the behaviors recommend an absence of ample lengthy context post-training.
On this weblog put up, we apply the identical evaluation to OpenAI o1-preview, o1-mini and Google Gemini 1.5 Professional and Gemini 1.5 Flash. For a full description of our datasets, methodology and experimental particulars, please consult with Lengthy Context RAG Efficiency of LLMs.
OpenAI o1 outcomes: a brand new SOTA on Lengthy Context RAG
The brand new SOTA: The OpenAI o1-preview and o1-mini fashions beat all the opposite fashions on our three lengthy context RAG benchmarks, with the o1-mini outcomes intently matching these of GPT-4o (Figures 1-2). Such a efficiency enchancment over GPT-4o-mini is sort of spectacular,because the “mini” model of the brand new launch is best than the strongest from the final launch.
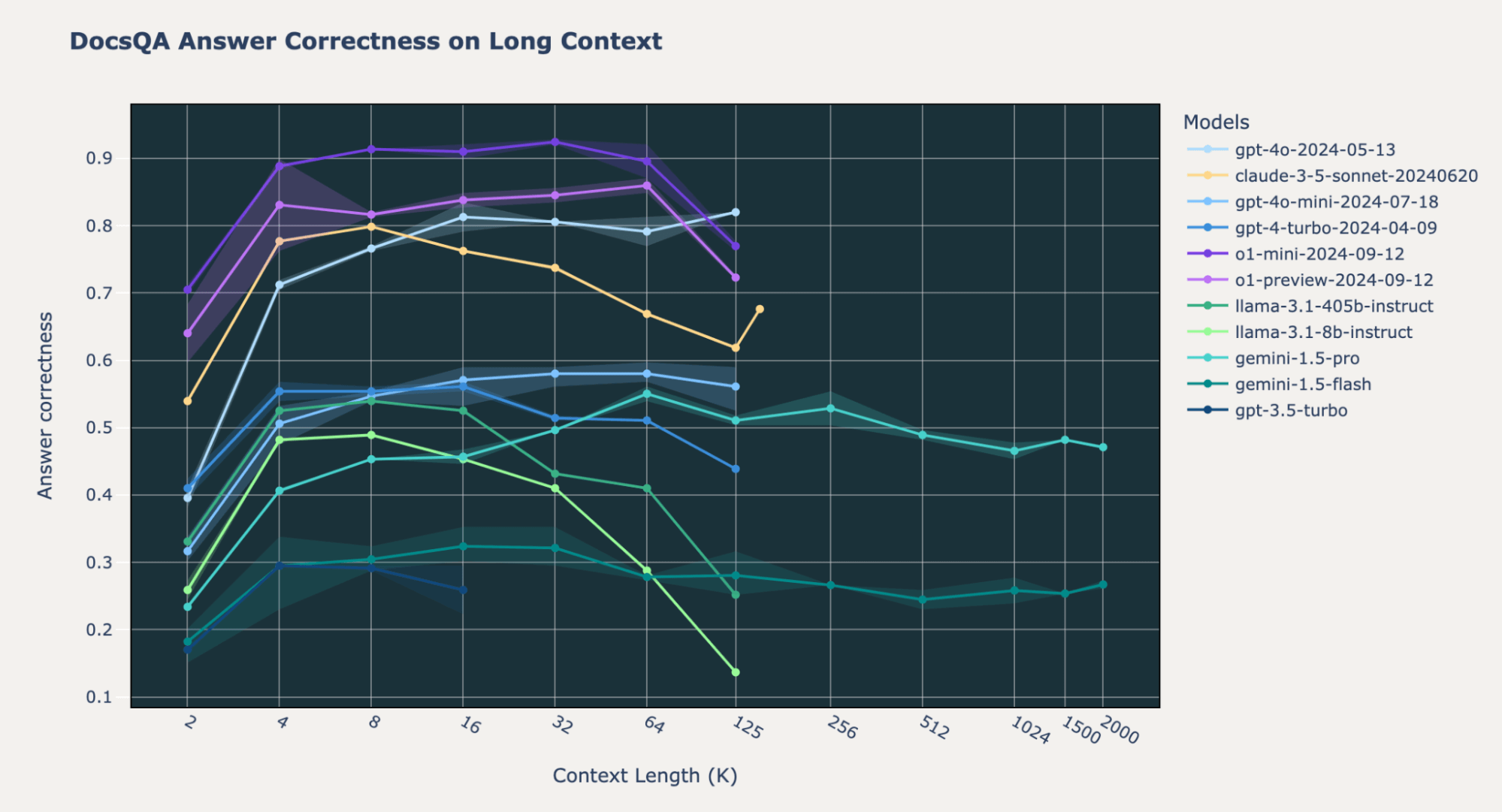
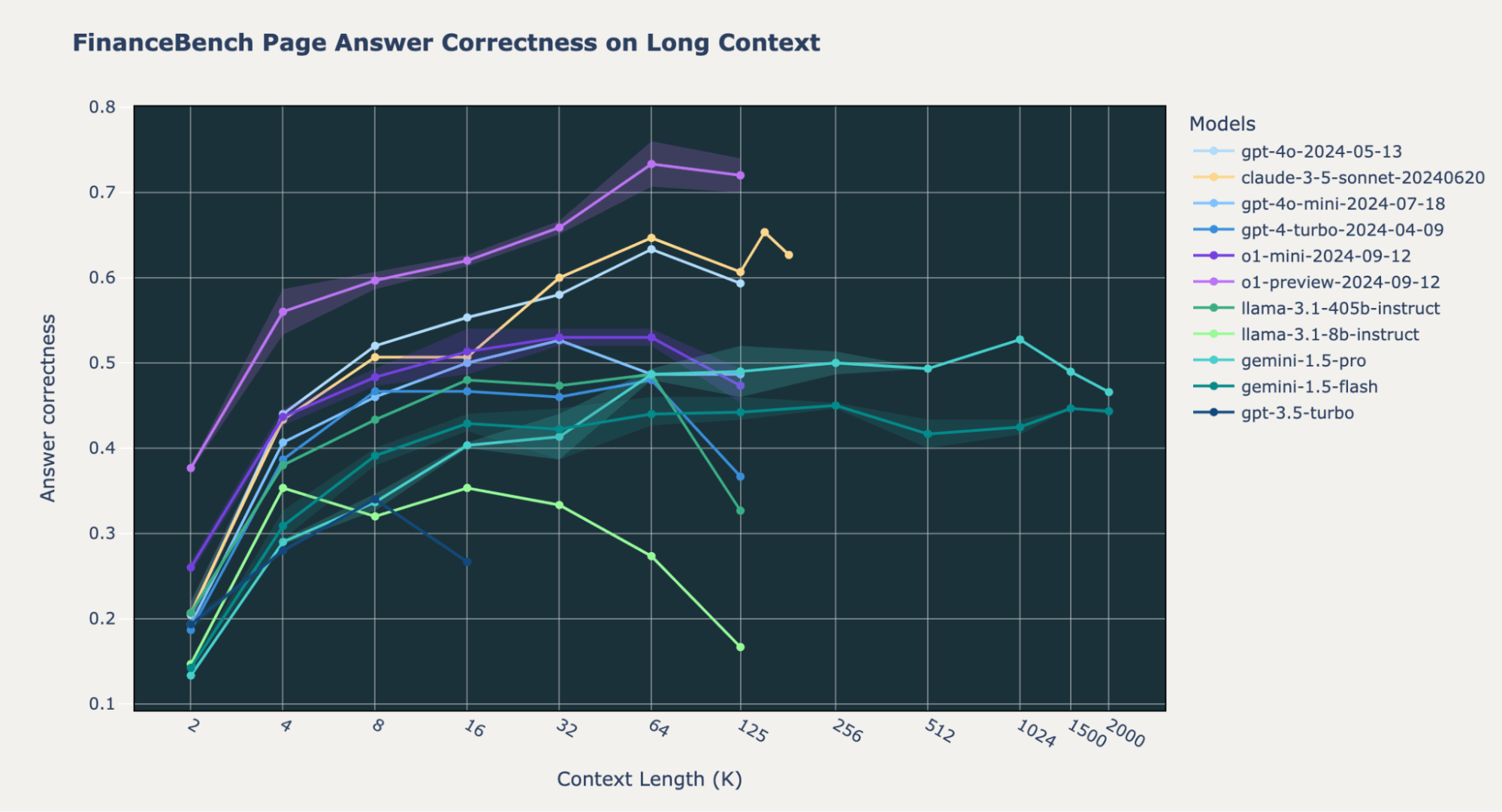
We observed some variations in o1 mannequin conduct throughout benchmarks. On our inside Databricks DocsQA and FinanceBench datasets, the o1-preview and o1-mini fashions do considerably higher than the GPT-4o and Gemini fashions throughout all context lengths. That is largely true for the Pure Questions (NQ) dataset; nevertheless, we observed that each the o1-preview and o1-mini fashions have decrease efficiency at quick context size (2k tokens). We delve into this peculiar conduct on the finish of this blogpost.
Gemini 1.5 Fashions Preserve Constant RAG efficiency as much as 2 Million Tokens
Though the general reply correctness of the Google Gemini 1.5 Professional and Gemini 1.5 Flash fashions is way decrease than that of the o1 and GPT-4o fashions as much as 128,000 tokens, the Gemini fashions keep constant efficiency at extraordinarily lengthy contexts as much as 2,000,000 tokens.
On Databricks DocsQA and FinanceBench, the Gemini 1.5 fashions do worse than OpenAI o1, GPT4o-mini, and Anthropic Claude-3.5-Sonnet. Nevertheless, on NQ, all of those fashions have comparable excessive efficiency with reply correctness values constantly above 0.8. For essentially the most half, the Gemini 1.5 fashions don’t have a efficiency lower on the finish of their most context size, not like most of the different fashions.
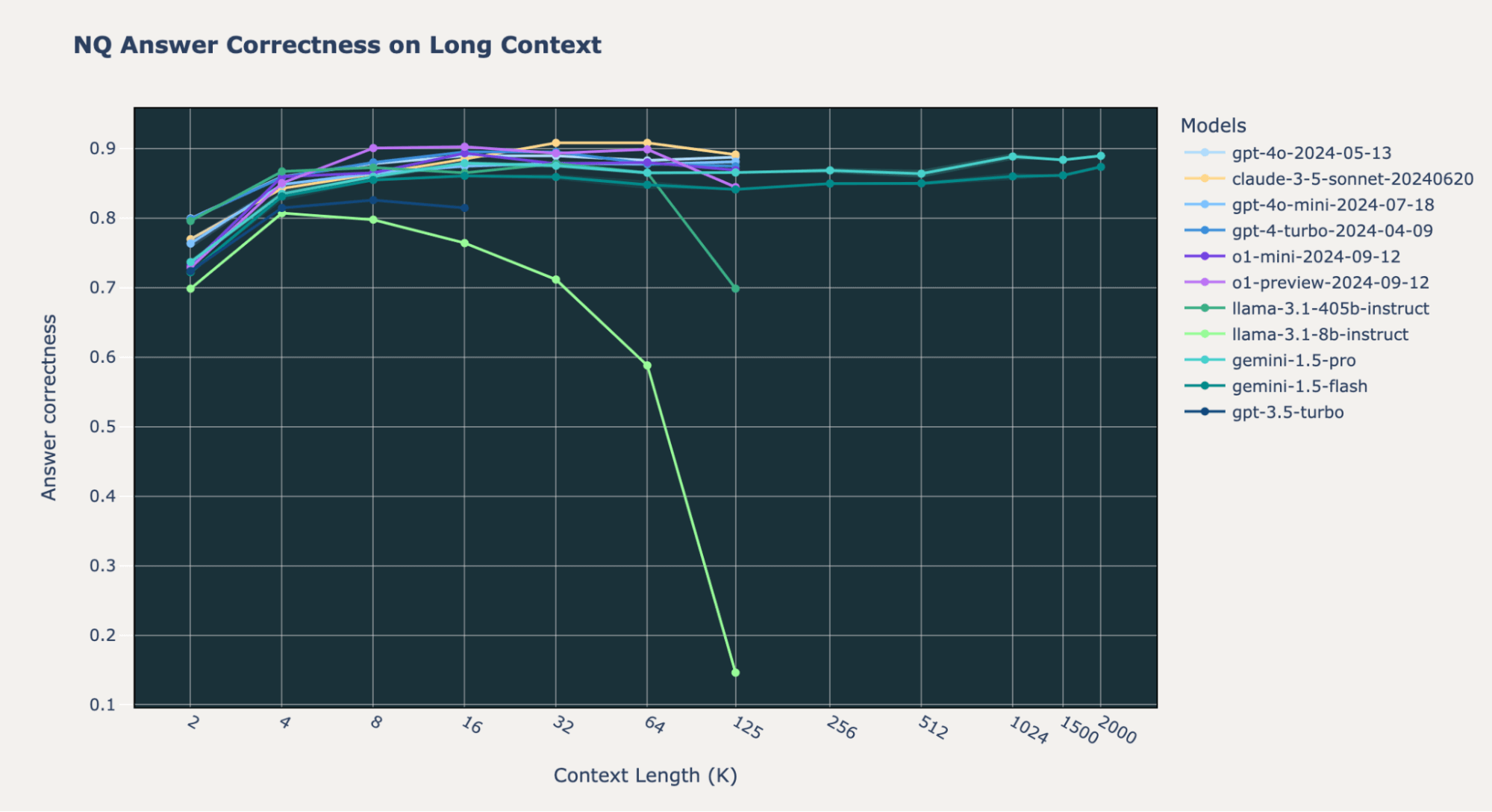
These outcomes suggest that for a corpus smaller than 2 million tokens, it’s doable to skip the retrieval step in a RAG pipeline and as a substitute immediately feed the whole dataset into the Gemini fashions. Though this is able to be fairly costly and have decrease efficiency, such a setup might permit builders to commerce larger prices for a extra simplified developer expertise when constructing LLM functions.
LLMs Fail at Lengthy Context RAG in Totally different Methods
To evaluate the failure modes of technology fashions at longer context size, we analyzed samples from OpenAI o1 and Gemini 1.5 Professional utilizing the identical methodology as our earlier weblog put up. We extracted the solutions for every mannequin at totally different context lengths, manually inspected a number of samples, and – primarily based on these observations – outlined the next broad failure classes:
- repeated_content: when the LLM reply is totally (nonsensical) repeated phrases or characters.
- random_content: when the mannequin produces a solution that is totally random, irrelevant to the content material, or would not make logical or grammatical sense.
- fail_follow_inst: when the mannequin would not perceive the intent of the instruction or fails to observe the instruction specified within the query. For instance, when the instruction is about answering a query primarily based on the given context whereas the mannequin is making an attempt to summarize the context.
- empty_resp: the technology reply is empty
- wrong_answer: when the mannequin makes an attempt to observe the instruction however the supplied reply is fallacious.
- others: the failure would not fall beneath any of the classes listed above
We added two extra classes, since this conduct was particularly prevalent with the Gemini fashions:
- refusal: the mannequin both refuses to reply the query, mentions that the reply cannot be discovered within the context, or states that the context just isn’t related to the query.
- process failure resulting from API filtering: the mannequin API merely blocked the immediate resulting from strict filtering tips. Notice that if the duty failed resulting from API filtering, we didn’t embrace this within the remaining Reply Correctness calculation.
We developed prompts that describe every class and used GPT-4o to categorise the entire failures of the fashions into the above classes. We additionally be aware that the failure patterns on these datasets is probably not consultant of different datasets; it’s additionally doable for the sample to vary with totally different technology settings and immediate templates.
o1-preview and o1-mini failures
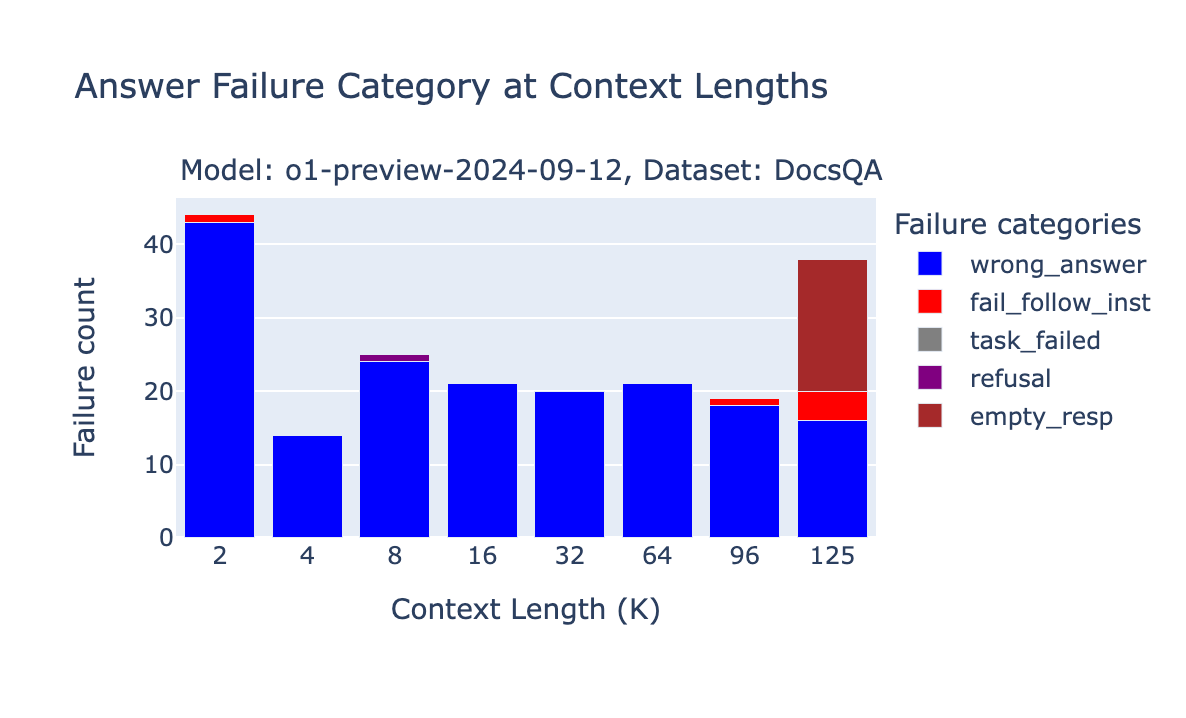
Whereas the OpenAI o1-preview and o1-mini scores ranked on the high of our benchmark, we nonetheless observed some distinctive failures resulting from context size. Because of the unpredictable size of the reasoning tokens utilized in o1 fashions, if the immediate grows resulting from intermediate “reasoning” steps, OpenAI doesn’t fail the request immediately however as a substitute returns a response with an empty string.
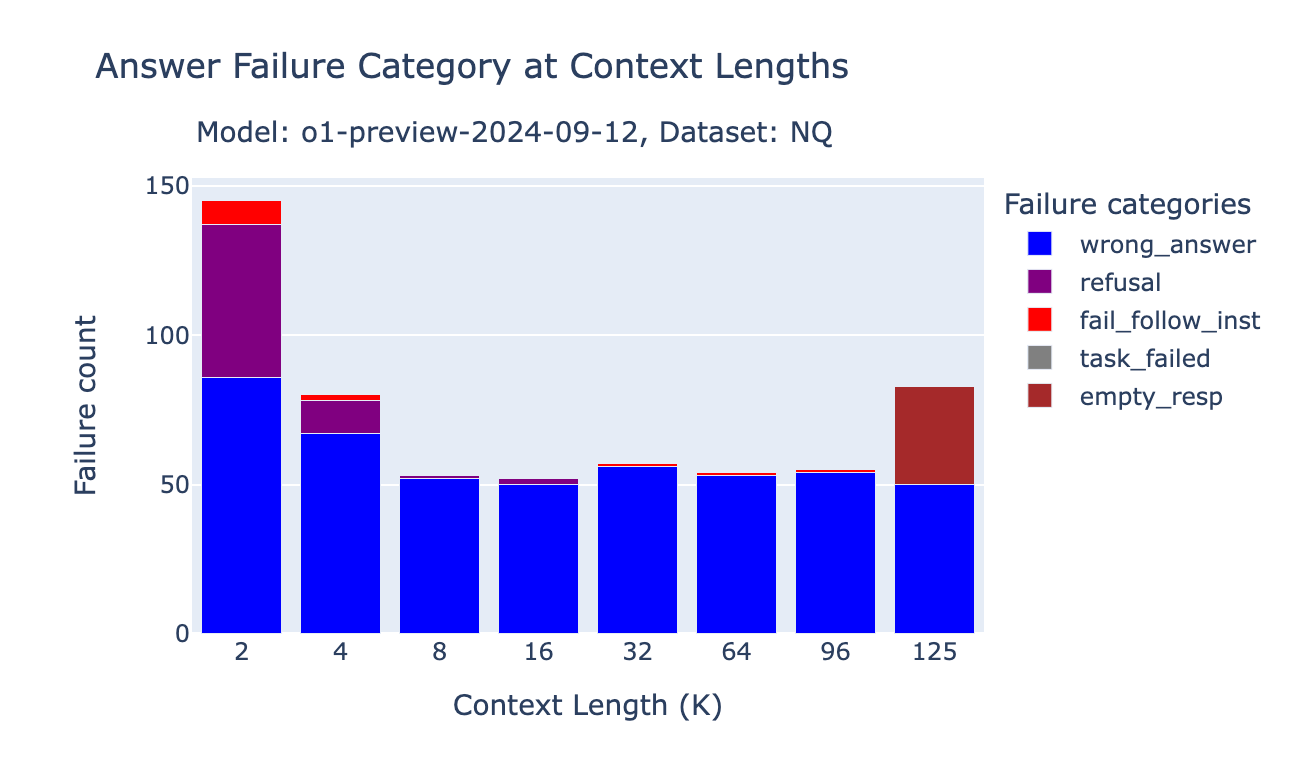
o1 mannequin conduct change on NQ
Regardless of the efficiency improve on the Databricks DocsQA and FinanceBench datasets, we noticed efficiency drops for the o1-preview and o1-mini fashions on NQ at quick context size. We discovered that at quick context size, if the data just isn’t within the retrieved paperwork, o1 fashions usually tend to merely reply “Data not accessible” (our prompts embrace an instruction “if there isn’t a related passage, please reply utilizing your information” – see our the Appendix of earlier blogpost for the total prompts).
We additionally observed a good portion of samples the place the o1 fashions failed to offer the proper reply even with the oracle doc was current. Such efficiency regression is stunning for such a robust mannequin.
Within the following instance with out an oracle doc current, o1 refuses to reply the query, whereas GPT-4o answered primarily based by itself information:
|
question |
expected_answer |
answer_o1_preview |
answer_gpt4o |
oracle_present |
|
when does dragon ball tremendous episode 113 begin |
October 29 , 2017 |
Data not accessible. |
October 29, 2017 |
FALSE |
|
who performs colin on younger and the stressed |
Tristan Rogers |
Data not accessible. |
Tristan Rogers |
FALSE |
Within the following instance, o1-preview did not reply the query when the oracle doc was retrieved:
|
question |
expected_answer |
answer_o1_preview |
answer_gpt4o |
oracle_present |
|
who’s the longest serving member of the home in historical past |
John Dingell |
Title not supplied |
John Dingell |
TRUE |
|
when does episode 29 of boruto come out |
October 18 , 2017 |
Data not accessible within the supplied context |
October 18, 2017 |
TRUE |
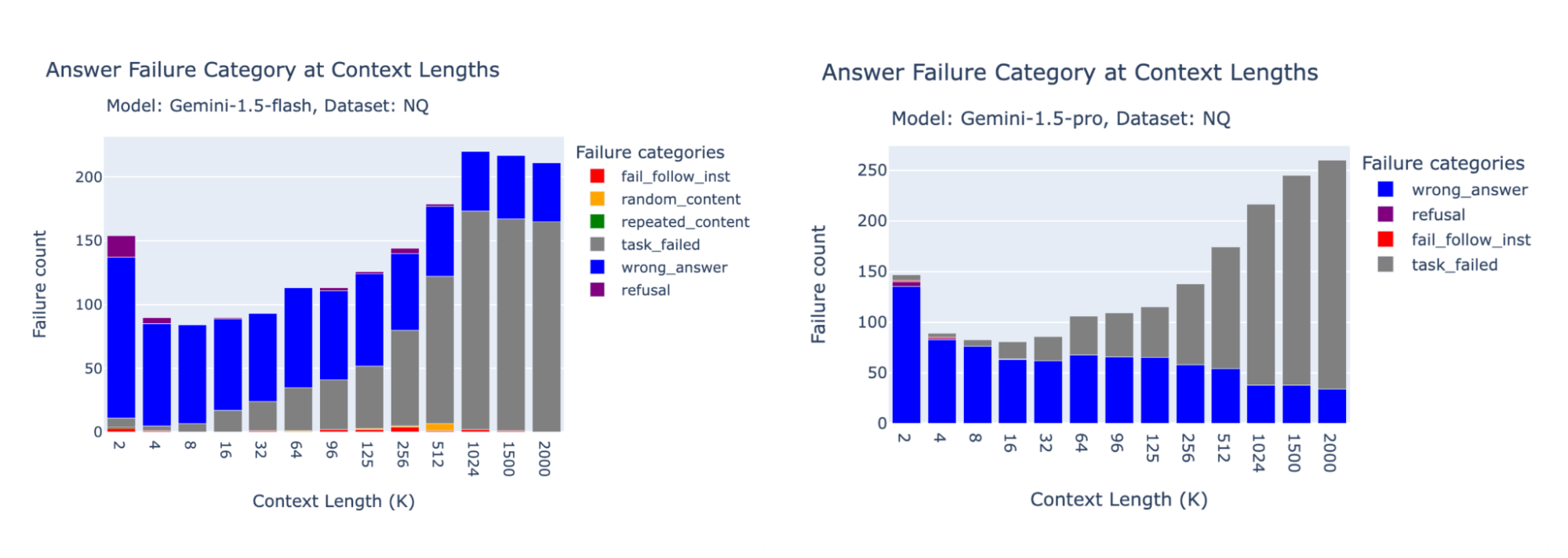
Gemini 1.5 Professional and Flash Failures
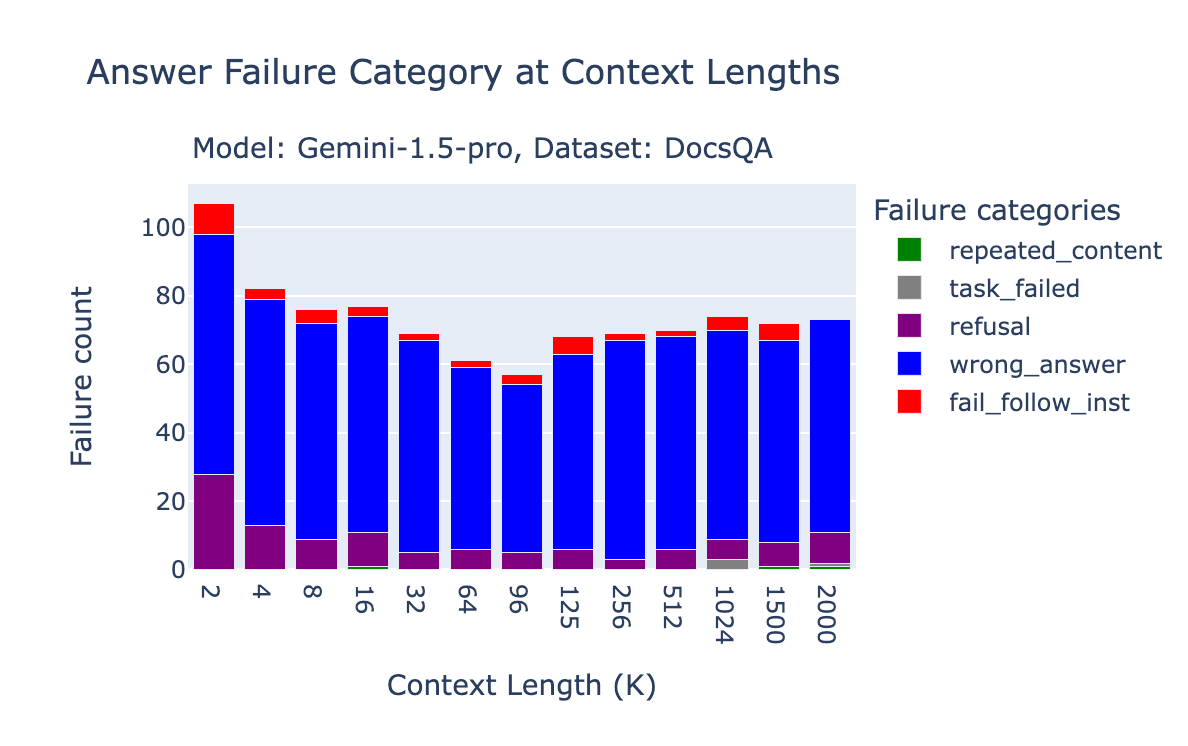
The bar charts under present the failure attribution for Gemini 1.5 Professional and Gemini 1.5 Flash on FinanceBench, Databricks DocsQA and NQ.
Gemini’s technology API could be very delicate to the matters in our prompts. We discovered that on our NQ benchmark there have been many process failures resulting from immediate content material filtering. This was stunning, as NQ is a regular tutorial benchmark that we have been in a position to efficiently benchmark with all different API fashions. We due to this fact discovered that among the Gemini efficiency decreases in Gemini wereas merely resulting from security filtering! Notice nevertheless that we determined to not embrace process failure resulting from API filtering within the remaining accuracy measure.
Right here is an instance of a rejected response from the Google Gemini API BlockedPromptException:
finish_reason: SAFETY
safety_ratings {
class: HARM_CATEGORY_SEXUALLY_EXPLICIT
likelihood: MEDIUM
}
safety_ratings {
class: HARM_CATEGORY_HATE_SPEECH
likelihood: NEGLIGIBLE
}
safety_ratings {
class: HARM_CATEGORY_HARASSMENT
likelihood: NEGLIGIBLE
}
safety_ratings {
class: HARM_CATEGORY_DANGEROUS_CONTENT
likelihood: NEGLIGIBLE
}
On FinanceBench, a big portion of errors for Gemini 1.5 Professional have been resulting from “refusal,” the place the mannequin both refuses to reply the query or mentions that the reply cannot be discovered within the context. That is extra pronounced at shorter context lengths, the place the OpenAI text-embedding-3-large retriever may not have retrieved the proper paperwork. Particularly, at 2k context size, the 96.2% of “refusal” circumstances are certainly when the oracle doc just isn’t current. The accuracy is 89% at 4k, 87% at 8k, 77% at 16k.
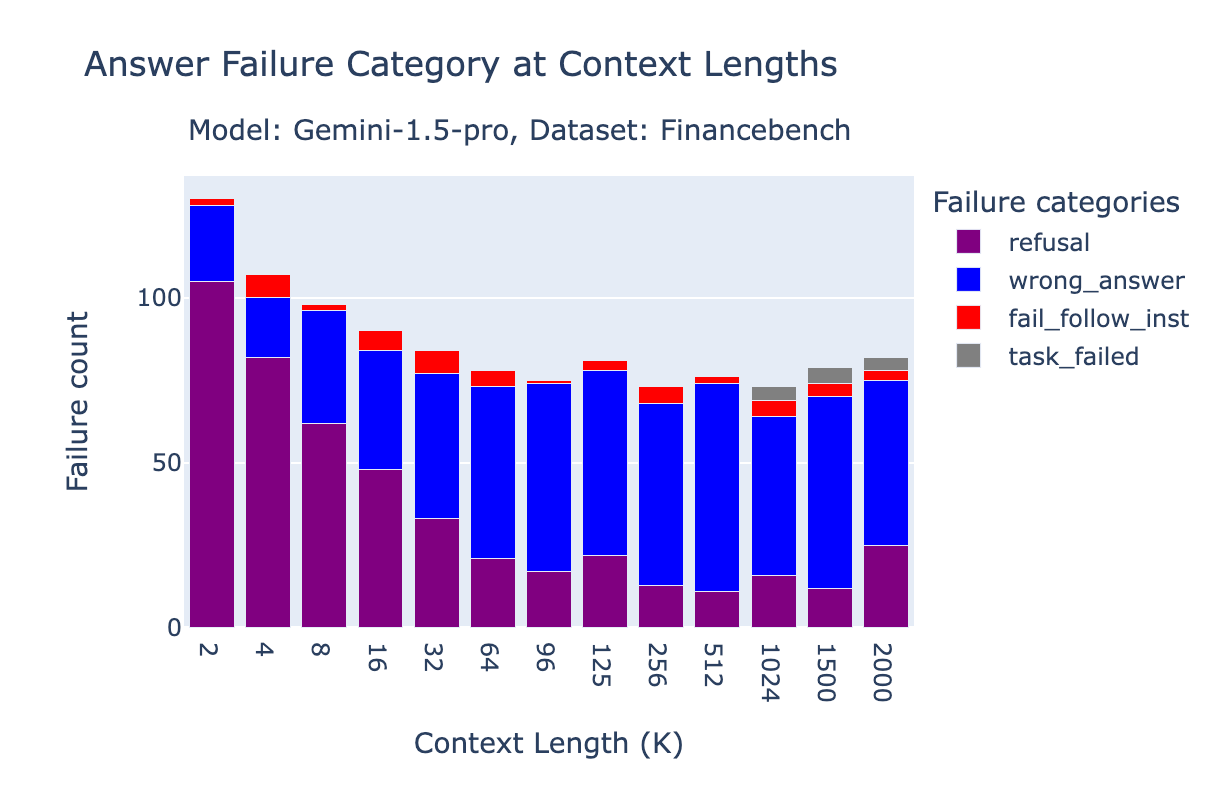
On the Databricks DocsQA dataset, nearly all of failures are merely resulting from incorrect solutions.
Conclusions:
We have been pleasantly stunned to see robust efficiency from the OpenAI o1 fashions; as reported elsewhere, the o1 fashions appear to be a substantive enchancment over GPT-4 and GPT-4o. We have been additionally stunned to see constant efficiency from the Gemini 1.5 fashions at as much as 2 million tokens, albeit with decrease total accuracy. We hope that our benchmarks will assist inform builders and companies constructing RAG workflows.
Strong benchmarking and analysis instruments are essential for growing advanced AI programs. To this finish, Databricks Mosaic AI Analysis is dedicated to sharing analysis analysis (e.g. Calibrating the Mosaic Analysis Gauntlet) and merchandise corresponding to Mosaic AI Agent Framework and Agent Analysis that assist builders efficiently construct state-of-the-art AI merchandise.
Appendix:
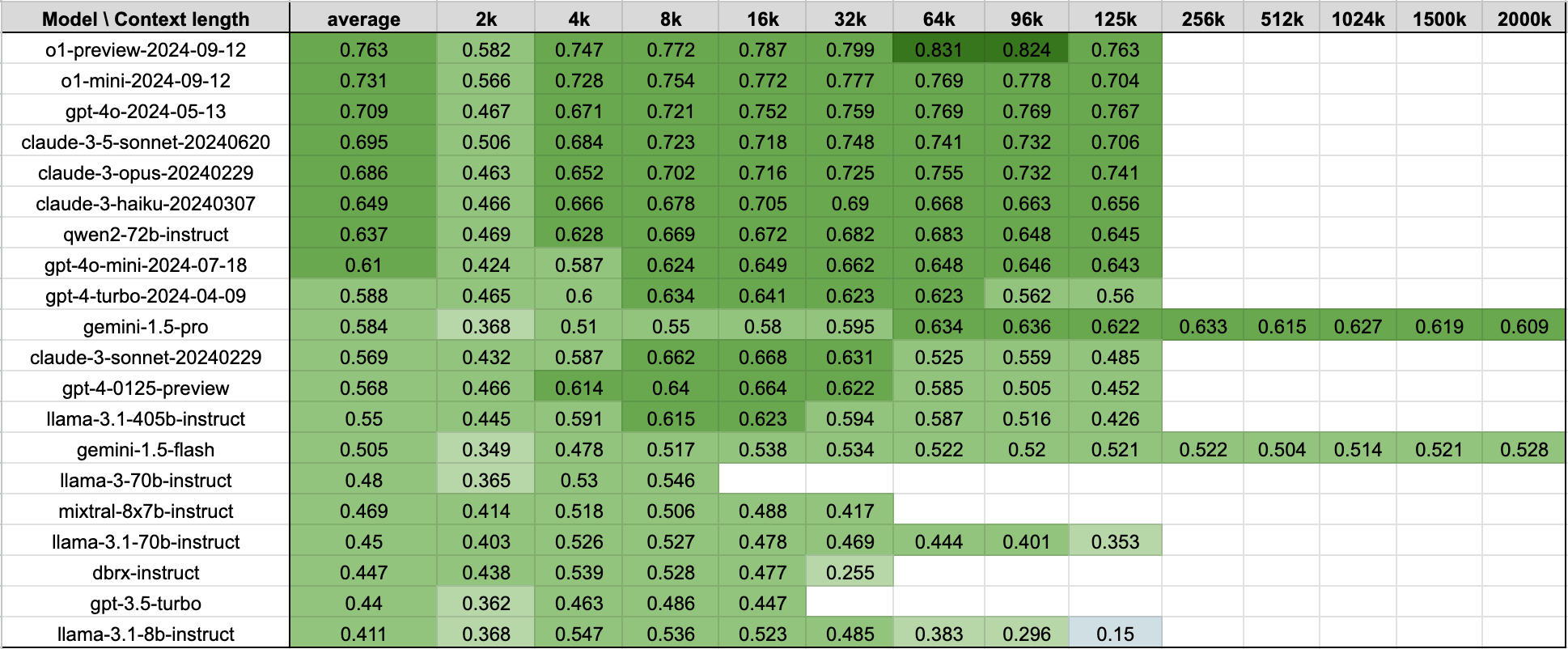
Lengthy context RAG efficiency desk:
By combining these RAG duties collectively, we get the next desk that exhibits the typical efficiency of fashions on the 4 datasets listed above. The desk is identical information as Determine 1.
Immediate templates:
We used the next immediate templates (similar as in our earlier weblog put up):
Databricks DocsQA:
|
You’re a useful assistant good at answering questions associated to databricks merchandise or spark options. You will be supplied with a query and a number of other passages that is perhaps related. Your process is to offer a solution primarily based on the query and passages. Notice that passages may not be related to the query; please solely use the passages which might be related. If there isn’t a related passage, please reply utilizing your information. The supplied passages as context: {context} The query to reply: {query} Your reply: |
FinanceBench:
|
You’re a useful assistant good at answering questions associated to monetary studies. You will be supplied with a query and a number of other passages that is perhaps related. Your process is to offer a solution primarily based on the query and passages. Notice that passages may not be related to the query; please solely use the passages which might be related. If there isn’t a related passage, please reply utilizing your information. The supplied passages as context: {context} The query to reply: {query} Your reply: |
NQ:
|
You’re an assistant that solutions questions. Use the next items of retrieved context to reply the query. Some components of the context could also be irrelevant, wherein case you shouldn’t use them to type the reply. Your reply ought to be a brief phrase; don’t reply in a whole sentence. Query: {query} Context: {context} Reply: |