{kind=link}

The speedy scaling of diffusion fashions has led to reminiscence utilization and latency challenges, hindering their deployment, notably in resource-constrained environments. Such fashions have manifested spectacular capability in rendering highly-fidelity photos however are demanding in each reminiscence and computation, which limits their availability in consumer-grade gadgets and functions that require low latencies. Subsequently, these challenges should be addressed to make it possible to coach large-scale diffusion fashions throughout an unlimited multiplicity of platforms in actual time.
Present methods to unravel reminiscence and velocity problems with diffusion fashions embody post-training quantization and quantization-aware coaching primarily with weight-only quantization strategies akin to NormalFloat4 (NF4). Whereas these strategies work nicely for language fashions, they fall brief for diffusion fashions due to the next computational requirement. In contrast to language fashions, diffusion fashions require simultaneous low-bit quantization of each weights and activations to stop efficiency degradation. The prevailing strategies for quantization endure as a result of presence of outliers in each weights and activations at 4-bit precision accuracy and contribute in the direction of compromised visible high quality together with computational inefficiencies, making a case for a extra sturdy resolution.
Researchers from MIT, NVIDIA, CMU, Princeton, UC Berkeley, SJTU, and Pika Labs suggest SVDQuant. This quantization paradigm introduces a low-rank department to soak up outliers, facilitating efficient 4-bit quantization for diffusion fashions. Utilizing inventive SVD to cope with the outliers, SVDQuant would switch it throughout from activations to weight after which soak up it right into a low-rank department which permits residual to be quantized at 4 bit with out loss in efficiency and keep away from one frequent error associated to the outliers additional optimization of the method of quantization with out overhead re-quantization. The scientists developed an inference engine referred to as Nunchaku that mixes low-rank and low-bit computation kernels with reminiscence entry optimization to chop latency.

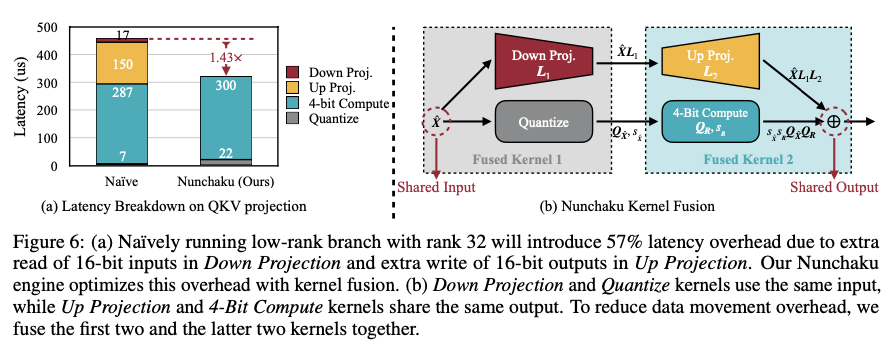
SVDQuant works by smoothing and sending outliers from activations to weights. Then making use of SVD decomposition over weights, break up the weights right into a low rank and residual. The low-rank part would suck within the outliers at 16-bit precision whereas the residual will get quantized at 4-bit precision. The Nunchaku inference engine additional optimizes this by permitting the low-rank and the low-bit branches collectively, thereby merging the enter and output dependencies, which leads to decreased reminiscence entry and subsequently decreased latency. Impressively, evaluations on fashions akin to FLUX.1 and SDXL, utilizing datasets like MJHQ and sDCI, reveal enormous reminiscence financial savings of three.5× and latency financial savings of as much as 10.1× on laptop computer gadgets. As an example, making use of SVDQuant reduces the 12 billion parameter FLUX.1 mannequin from 22.7 GB down to six.5 GB, avoiding CPU offloading in memory-constrained settings.
The SVDQuant surpassed the state-of-the-art quantization strategies each in effectivity and visible fidelities. For 4-bit quantization, SVDQuant consistently reveals nice perceptual similarity accompanied with high-quality numerical constructs that may be preserved for any picture era job all through with a constant outperforming of rivals, akin to NF4, regarding their Fréchet Inception Distance, ImageReward, LPIPS, and PSNR scores throughout a number of diffusion mannequin architectures and for instance, in comparison with the FLUX.1-dev mannequin, SVDQuant’s configuration is nicely tuned at LPIPS scores aligned carefully with the 16-bit baseline whereas saving 3.5× in mannequin dimension and reaching round a ten.1× speedup on GPU gadgets with out having CPU offloading. Such effectivity helps the real-time era of high-quality photos on memory-limited gadgets underlines the efficient sensible deployment of enormous diffusion fashions.

In conclusion, the proposed strategy SVDQuant employs superior 4-bit quantization; right here, the outlier issues discovered within the diffusion mannequin are coped with whereas sustaining the standard of the photographs, with vital reductions in reminiscence and latency. Optimizing quantization and eliminating redundant information motion by the Nunchaku inference engine kinds a basis for the environment friendly deployment of enormous diffusion fashions and, thus, propels their potential use in real-world interactive functions on shopper {hardware}.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[AI Magazine/Report] Learn Our Newest Report on ‘SMALL LANGUAGE MODELS‘
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.