{kind=link}

Overview
This weblog put up is a follow-up to the session From Supernovas to LLMs at Knowledge + AI Summit 2024, the place I demonstrated how anybody can devour and course of publicly out there NASA satellite tv for pc knowledge from Apache Kafka.
In contrast to most Kafka demos, which aren’t simply reproducible or depend on simulated knowledge, I’ll present the right way to analyze a reside knowledge stream from NASA’s publicly accessible Gamma-ray Coordinates Community (GCN) which integrates knowledge from supernovas and black holes coming from numerous satellites.
Whereas it is doable to craft an answer utilizing solely open supply Apache Spark™ and Apache Kafka, I’ll present the numerous benefits of utilizing the Databricks Knowledge Intelligence Platform for this job. Additionally, the supply code for each approaches might be offered.
The answer constructed on the Knowledge Intelligence Platform leverages Delta Reside Tables with serverless compute for knowledge ingestion and transformation, Unity Catalog for knowledge governance and metadata administration, and the facility of AI/BI Genie for pure language querying and visualization of the NASA knowledge stream. The weblog additionally showcases the facility of Databricks Assistant for the era of advanced SQL transformations, debugging and documentation.
Supernovas, black holes and gamma-ray bursts
The evening sky will not be static. Cosmic occasions like supernovas and the formation of black holes occur steadily and are accompanied by highly effective gamma-ray bursts (GRBs). Such gamma-ray bursts usually final solely two seconds, and a two-second GRB usually releases as a lot power because the Solar’s throughout its total lifetime of some 10 billion years.
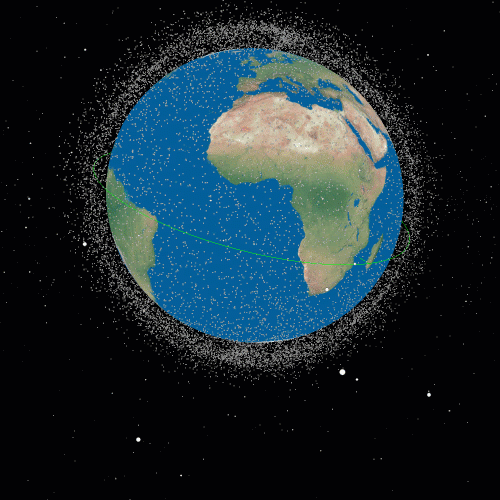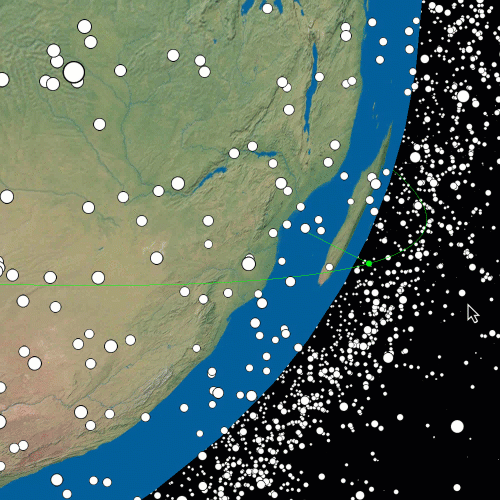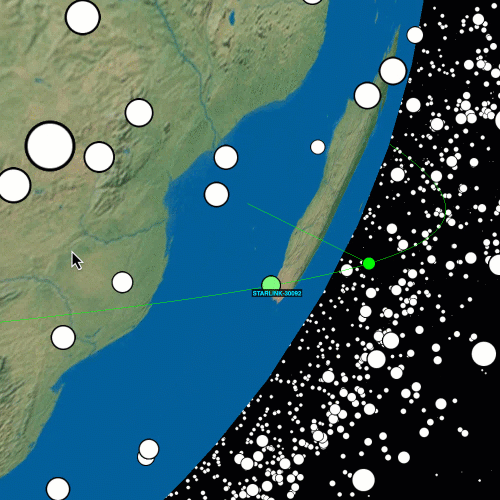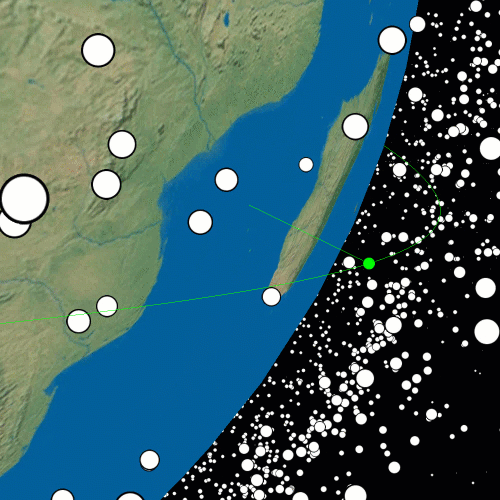
Throughout the Chilly Conflict, particular satellites constructed to detect covert nuclear weapon exams coincidentally found these intense flashes of gamma radiation originating from deep house. Immediately, NASA makes use of a fleet of satellites like Swift and Fermi to detect and examine these bursts that originated billions of years in the past in distant galaxies. The inexperienced line within the following animation exhibits the SWIFT satellite tv for pc’s orbit at 11 AM CEST on August 1, 2024, generated with Satellite tv for pc Tracker 3D, courtesy of Marko Andlar.
GRB 221009A, one of many brightest and most energetic GRBs ever recorded, blinded most devices due to its power. It originated from the constellation of Sagitta and is believed to have occurred roughly 1.9 billion years in the past. Nevertheless, because of the enlargement of the universe over time, the supply of the burst is now about 2.4 billion light-years away from Earth. GRB 221009A is proven within the picture beneath.

Wikipedia. July 18, 2024. “GRB 221009A.” https://en.wikipedia.org/wiki/GRB_221009A.
Trendy astronomy now embraces a multi-messenger strategy, capturing numerous alerts collectively corresponding to neutrinos along with gentle and gamma rays. The IceCube observatory on the South Pole, for instance, makes use of over 5,000 detectors embedded inside a cubic kilometer of Antarctic ice to detect neutrinos passing by the Earth.
The Gamma-ray Coordinates Community challenge connects these superior observatories — hyperlinks supernova knowledge from house satellites and neutrino knowledge from Antarctica — and makes NASA’s knowledge streams accessible worldwide.
Whereas analyzing knowledge from NASA satellites could appear daunting, I would prefer to show how simply any knowledge scientist can discover these scientific knowledge streams utilizing the Databricks Knowledge Intelligence Platform, due to its sturdy instruments and pragmatic abstractions.
As a bonus, you’ll find out about one of many coolest publicly out there knowledge streams you can simply reuse in your personal research.
Now, let me clarify the steps I took to deal with this problem.
Consuming Supernova Knowledge From Apache Kafka
Getting OICD token from GCN Quickstart
NASA presents the GCN knowledge streams as Apache Kafka matters the place the Kafka dealer requires authentication through an OIDC credential. Acquiring GCN credentials is simple:
- Go to the GCN Quickstart web page
- Authenticate utilizing Gmail or different social media accounts
- Obtain a shopper ID and shopper secret
The Quickstart will create a Python code snippet that makes use of the GCN Kafka dealer, which is constructed on the Confluent Kafka codebase.
It is essential to notice that whereas the GCN Kafka wrapper prioritizes ease of use, it additionally abstracts most technical particulars such because the Kafka connection parameters for OAuth authentication.
The open supply manner with Apache Spark™
To be taught extra about that supernova knowledge, I made a decision to start with essentially the most common open supply answer that may give me full management over all parameters and configurations. So I carried out a POC with a pocket book utilizing Spark Structured Streaming. At its core, it boils right down to the next line:
spark.readStream.format("kafka").choices(**kafka_config)...In fact, the essential element right here is within the **kafka_config connection particulars which I extracted from the GCN wrapper. The complete Spark pocket book is offered on GitHub (see repo on the finish of the weblog).
My final objective, nonetheless, was to summary the lower-level particulars and create a stellar knowledge pipeline that advantages from Databricks Delta Reside Tables (DLT) for knowledge ingestion and transformation.
Incrementally ingesting supernova knowledge from GCN Kafka with Delta Reside Tables
There have been a number of the reason why I selected DLT:
- Declarative strategy: DLT permits me to give attention to writing the pipeline declaratively, abstracting a lot of the complexity. I can give attention to the info processing logic making it simpler to construct and keep my pipeline whereas benefiting from Databricks Assistant, Auto Loader and AI/BI.
- Serverless infrastructure: With DLT, infrastructure administration is totally automated and compute assets are provisioned serverless, eliminating guide setup and configuration. This allows superior options corresponding to incremental materialized view computation and vertical autoscaling, permitting for environment friendly, scalable and cost-efficient knowledge processing.
- Finish-to-end pipeline growth in SQL: I wished to discover the opportunity of utilizing SQL for the whole pipeline, together with ingesting knowledge from Kafka with OIDC credentials and sophisticated message transformations.
This strategy allowed me to streamline the event course of and create a easy, scalable and serverless pipeline for cosmic knowledge with out getting slowed down in infrastructure particulars.
A DLT knowledge pipeline will be coded completely in SQL (Python is out there too, however solely required for some uncommon metaprogramming duties, i.e., if you wish to write code that creates pipelines).
With DLT’s new enhancements for builders, you possibly can write code in a pocket book and join it to a working pipeline. This integration brings the pipeline view and occasion log immediately into the pocket book, making a streamlined growth expertise. From there, you possibly can validate and run your pipeline, all inside a single, optimized interface — primarily a mini-IDE for DLT.
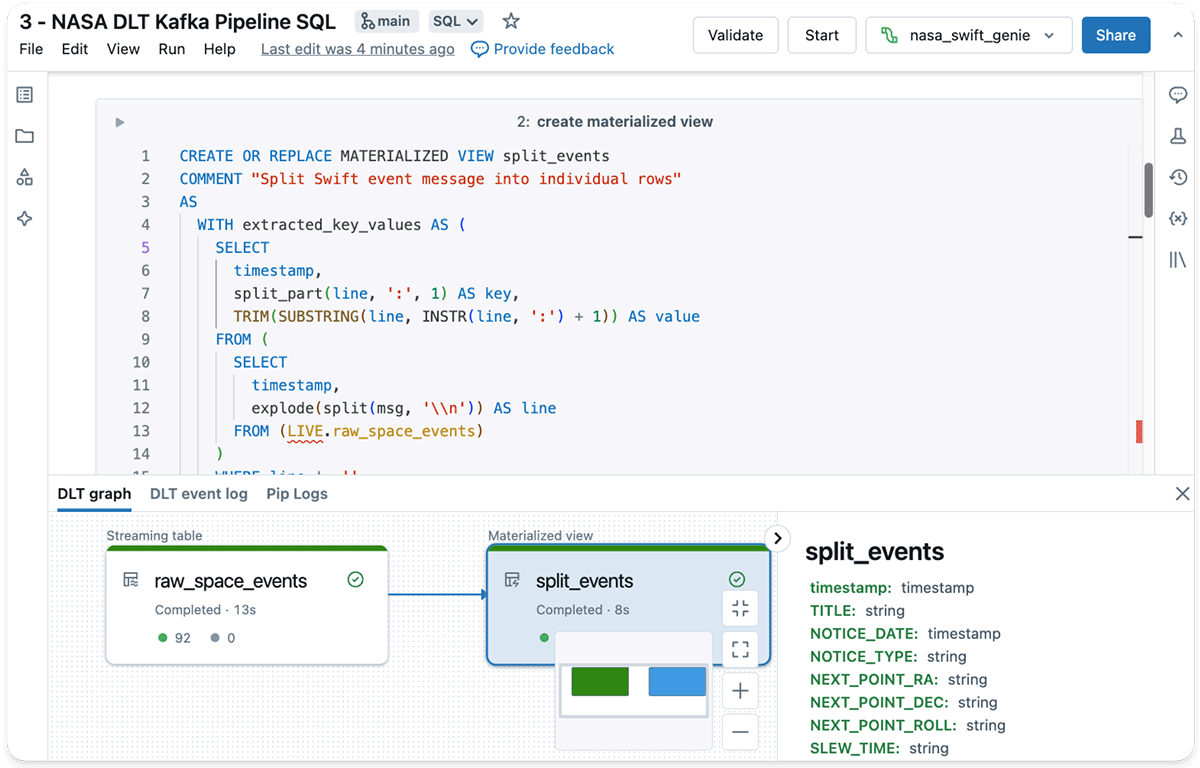
DLT streaming tables
DLT makes use of streaming tables to ingest knowledge incrementally from all types of cloud object shops or message brokers. Right here, I take advantage of it with the read_kafka() operate in SQL to learn knowledge immediately from the GCN Kafka dealer right into a streaming desk.
That is the primary essential step within the pipeline to get knowledge off the Kafka dealer. On the Kafka dealer, knowledge lives for a set retention interval solely, however as soon as ingested to the lakehouse, the info is endured completely and can be utilized for any form of analytics or machine studying.
Ingesting a reside knowledge stream is feasible due to the underlying Delta knowledge format. Delta tables are the high-speed knowledge format for DWH functions, and you’ll concurrently stream knowledge to (or from) a Delta desk.
The code to devour the info from the Kafka dealer with Delta Reside Tables appears to be like as follows:
CREATE OR REPLACE STREAMING TABLE raw_space_events AS
SELECT offset, timestamp, worth::string as msg
FROM STREAM read_kafka(
bootstrapServers => 'kafka.gcn.nasa.gov:9092',
subscribe => 'gcn.traditional.textual content.SWIFT_POINTDIR',
startingOffsets => 'earliest',
-- kafka connection particulars omitted for brevity
);For brevity, I omitted the connection setting particulars within the instance above (full code in GitHub).
By clicking on Unity Catalog Pattern Knowledge within the UI, you possibly can view the contents of a Kafka message after it has been ingested:
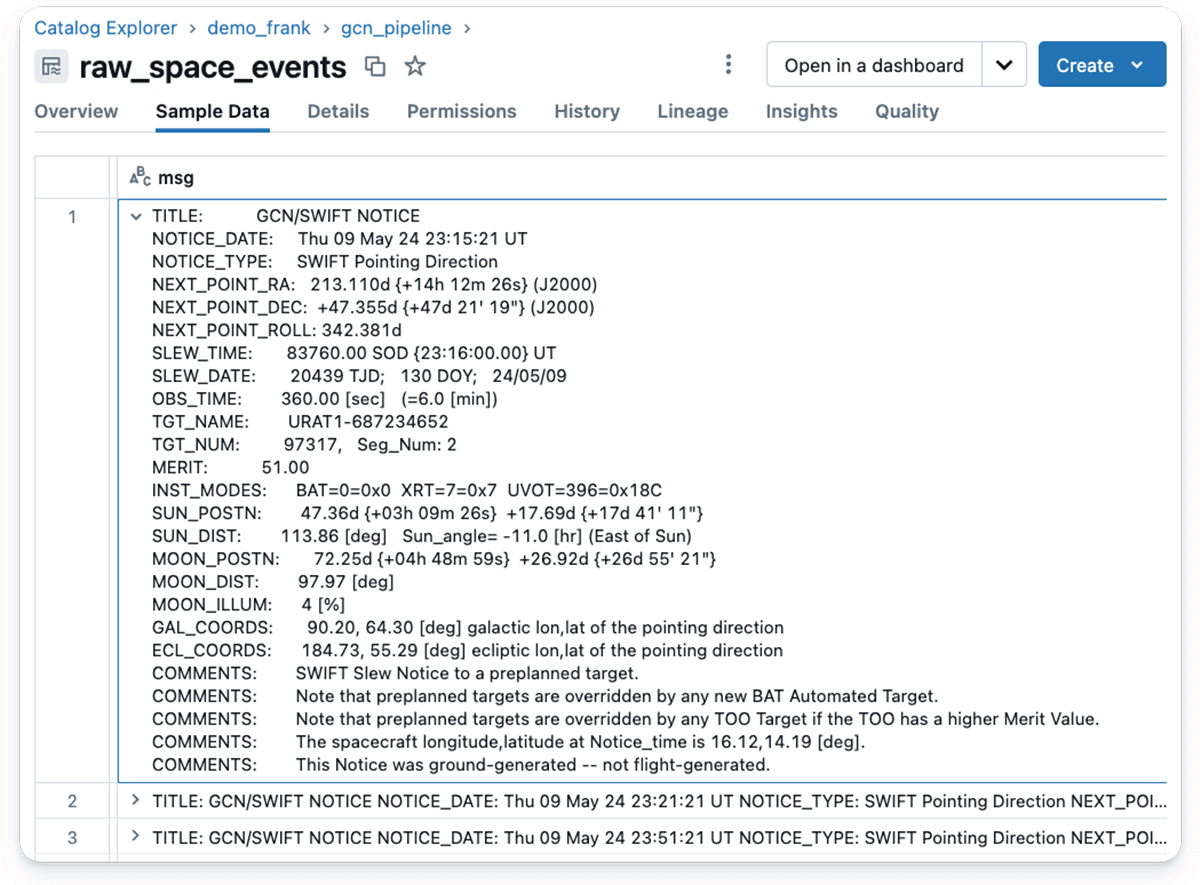
As you possibly can see, the SQL retrieves the whole message as a single entity composed of traces, every containing a key phrase and worth.
Notice: The Swift messages include the main points of when and the way a satellite tv for pc slews into place to watch a cosmic occasion like a GRB.
As with my Kafka shopper above, a few of the largest telescopes on Earth, in addition to smaller robotic telescopes, decide up these messages. Based mostly on the advantage worth of the occasion, they determine whether or not to alter their predefined schedule to watch it or not.
The above Kafka message will be interpreted as follows:
The discover was issued on Thursday, Could 24, 2024, at 23:51:21 Common Time. It specifies the satellite tv for pc’s subsequent pointing path, which is characterised by its Proper Ascension (RA) and Declination (Dec) coordinates within the sky, each given in levels and within the J2000 epoch. The RA is 213.1104 levels, and the Dec is +47.355 levels. The spacecraft’s roll angle for this path is 342.381 levels. The satellite tv for pc will slew to this new place at 83760.00 seconds of the day (SOD), which interprets to 23:16:00.00 UT. The deliberate remark time is 60 seconds.
The title of the goal for this remark is “URAT1-687234652,” with a advantage worth of 51.00. The advantage worth signifies the goal’s precedence, which helps in planning and prioritizing observations, particularly when a number of potential targets can be found.
Latency and frequency
Utilizing the Kafka settings above with startingOffsets => 'earliest', the pipeline will devour all present knowledge from the Kafka subject. This configuration permits you to course of present knowledge instantly, with out ready for brand spanking new messages to reach.
Whereas gamma-ray bursts are uncommon occasions, occurring roughly as soon as per million years in a given galaxy, the huge variety of galaxies within the observable universe ends in frequent detections. Based mostly alone observations, new messages usually arrive each 10 to twenty minutes, offering a gentle stream of knowledge for evaluation.
Streaming knowledge is usually misunderstood as being solely about low latency, nevertheless it’s really about processing an unbounded circulate of messages incrementally as they arrive. This permits for real-time insights and decision-making.
The GCN state of affairs demonstrates an excessive case of latency. The occasions we’re analyzing occurred billions of years in the past, and their gamma rays solely reached us now.
It is possible essentially the most dramatic instance of event-time to ingestion-time latency you will encounter in your profession. But, the GCN state of affairs stays an important streaming knowledge use case!
DLT materialized views for advanced transformations
Within the subsequent step, I needed to get this Character Massive OBject (CLOB) of a Kafka message right into a schema to have the ability to make sense of the info. So I wanted a SQL answer to first cut up every message into traces after which cut up every line into key/worth pairs utilizing the pivot methodology in SQL.
I utilized the Databricks Assistant and our personal DBRX massive language mannequin (LLM) from the Databricks playground for help. Whereas the ultimate answer is a little more advanced with the total code out there within the repo, a fundamental skeleton constructed on a DLT materialized view is proven beneath:
CREATE OR REPLACE MATERIALIZED VIEW split_events
-- Break up Swift occasion message into particular person rows
AS
WITH
-- Extract key-value pairs from uncooked occasions
extracted_key_values AS (
-- cut up traces and extract key-value pairs from LIVE.raw_space_events
...
),
-- Pivot desk to remodel key-value pairs into columns
pivot_table AS (
-- pivot extracted_key_values into columns for particular keys
...
)
SELECT timestamp, TITLE, CAST(NOTICE_DATE AS TIMESTAMP) AS
NOTICE_DATE, NOTICE_TYPE, NEXT_POINT_RA, NEXT_POINT_DEC,
NEXT_POINT_ROLL, SLEW_TIME, SLEW_DATE, OBS_TIME, TGT_NAME, TGT_NUM,
CAST(MERIT AS DECIMAL) AS MERIT, INST_MODES, SUN_POSTN, SUN_DIST,
MOON_POSTN, MOON_DIST, MOON_ILLUM, GAL_COORDS, ECL_COORDS, COMMENTS
FROM pivot_tableThe strategy above makes use of a materialized view that divides every message into correct columns, as seen within the following screenshot.
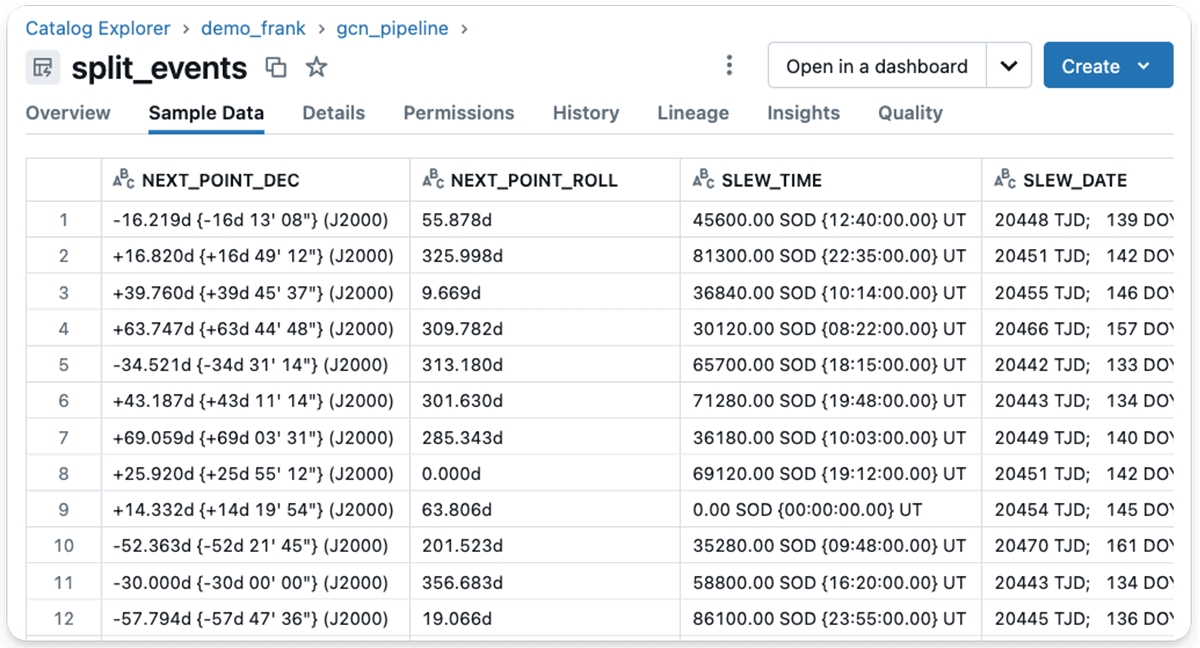
Materialized views in Delta Reside Tables are notably helpful for advanced knowledge transformations that should be carried out repeatedly. Materialized views enable for quicker knowledge evaluation and dashboards with decreased latency.
Databricks Assistant for code era
Instruments just like the Databricks Assistant will be extremely helpful for producing advanced transformations. These instruments can simply outperform your SQL expertise (or not less than mine!) for such use instances.
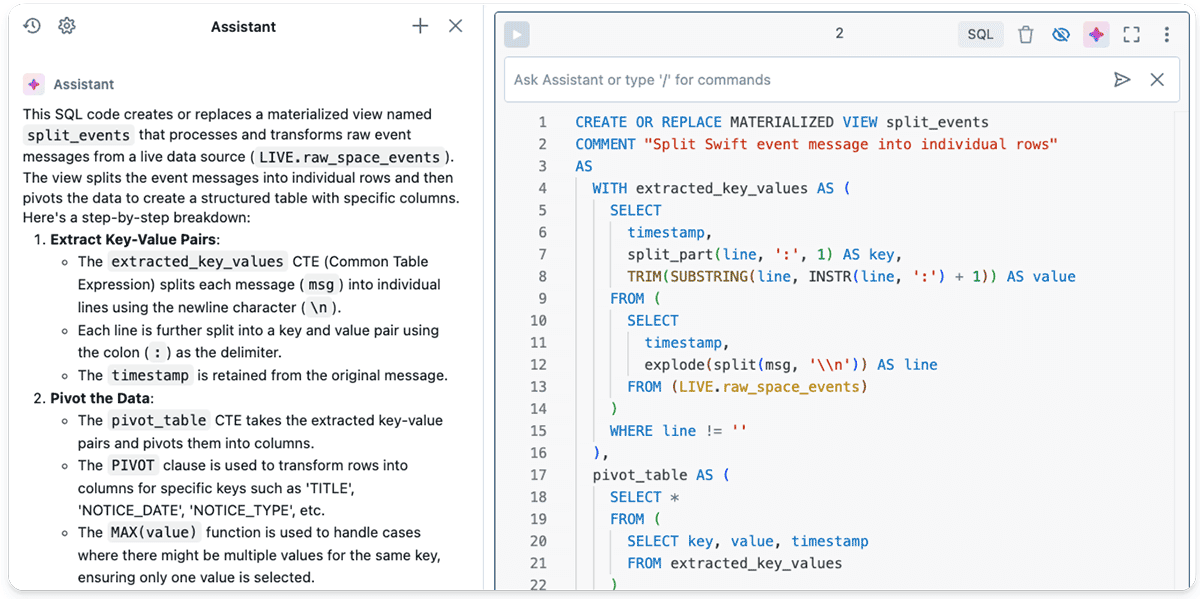
Professional tip: Helpers just like the Databricks Assistant or the Databricks DBRX LLM do not simply assist you discover a answer; you may as well ask them to stroll you thru their answer step-by-step utilizing a simplified dataset. Personally, I discover this tutoring functionality of generative AI much more spectacular than its code era expertise!
Analyzing Supernova Knowledge With AI/BI Genie
In case you attended the Knowledge + AI Summit this 12 months, you’d have heard quite a bit about AI/BI. Databricks AI/BI is a brand new kind of enterprise intelligence product constructed to democratize analytics and insights for anybody in your group. It consists of two complementary capabilities, Genie and Dashboards, that are constructed on high of Databricks SQL. AI/BI Genie is a strong software designed to simplify and improve knowledge evaluation and visualization throughout the Databricks Platform.
At its core, Genie is a pure language interface that enables customers to ask questions on their knowledge and obtain solutions within the type of tables or visualizations. Genie leverages the wealthy metadata out there within the Knowledge Intelligence Platform, additionally coming from its unified governance system Unity Catalog, to feed machine studying algorithms that perceive the intent behind the consumer’s query. These algorithms then remodel the consumer’s question into SQL, producing a response that’s each related and correct.
What I like most is Genie’s transparency: It shows the generated SQL code behind the outcomes relatively than hiding it in a black field.
Having constructed a pipeline to ingest and remodel the info in DLT, I used to be then capable of begin analyzing my streaming desk and materialized view. I requested Genie quite a few questions to raised perceive the info. Here is a small pattern of what I explored:
- What number of GRB occasions occurred within the final 30 days?
- What’s the oldest occasion?
- What number of occurred on a Monday? (It remembers the context. I used to be speaking in regards to the variety of occasions, and it is aware of the right way to apply temporal situations on an information stream.)
- What number of occurred on common per day?
- Give me a histogram of the advantage worth!
- What’s the most advantage worth?
Not too way back, I’d have coded questions like “on common per day” as window capabilities utilizing advanced Spark, Kafka and even Flink statements. Now, it is plain English!
Final however not least, I created a 2D plot of the cosmic occasions utilizing their coordinates. As a result of complexity of filtering and extracting the info, I first carried out it in a separate pocket book, as a result of the coordinate knowledge is saved within the celestial system utilizing by some means redundant strings. The unique knowledge will be seen within the following screenshot of the info catalog:
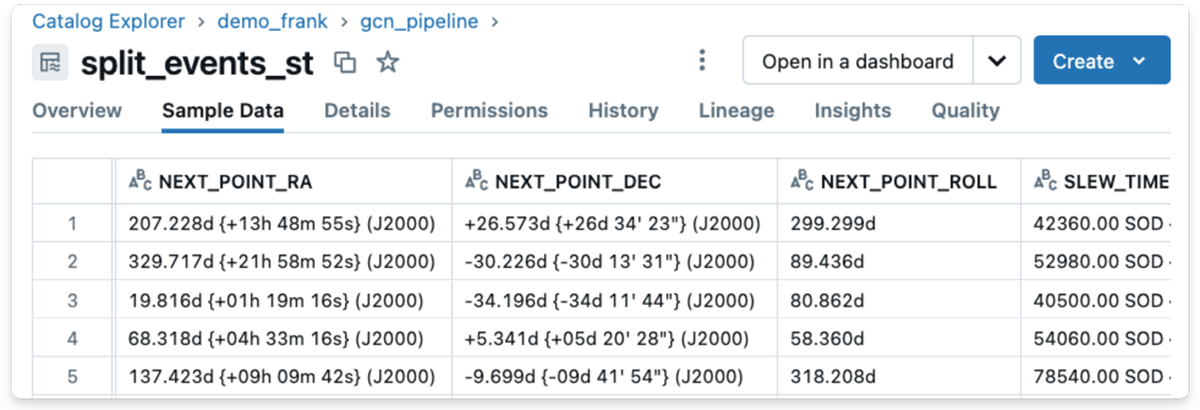
You may present directions in pure language or pattern queries to boost AI/BI’s understanding of jargon, logic and ideas like the actual coordinate system. So I attempted this out, and I offered a single instruction to AI/BI on retrieving floating-point values from the saved string knowledge and likewise gave it an instance.
Apparently, I defined the duty to AI/BI as I’d to a colleague, demonstrating the system’s means to know pure, conversational language.
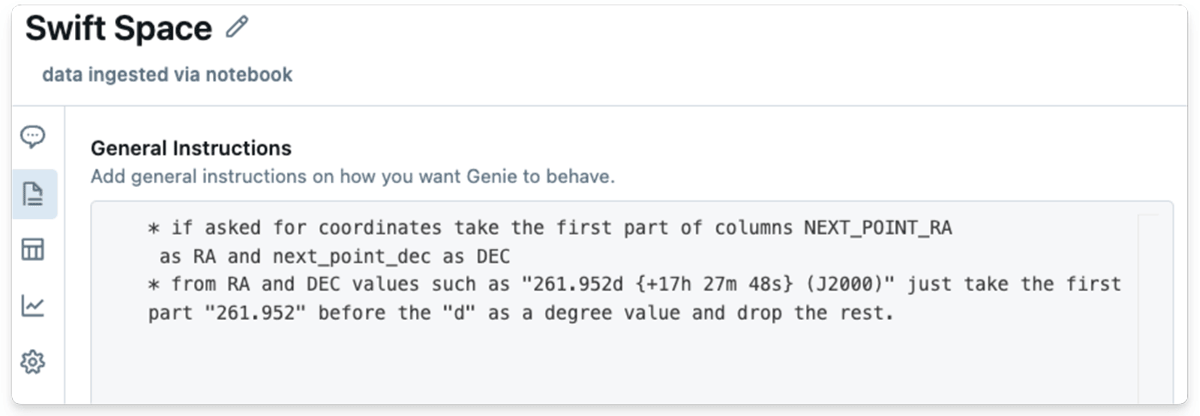
To my shock, Genie was capable of recreate the whole plot — which had initially taken me a complete pocket book to code manually — with ease.
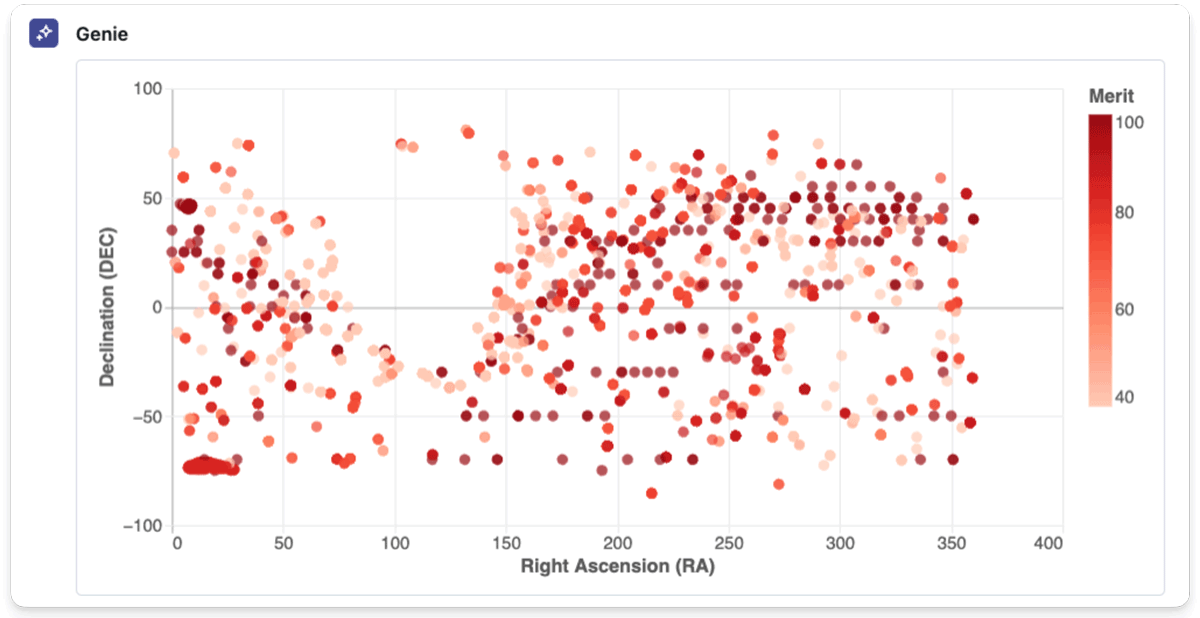
This demonstrated Genie’s means to generate advanced visualizations from pure language directions, making knowledge exploration extra accessible and environment friendly.
Abstract
- NASA’s GCN community supplies superb reside knowledge to everybody. Whereas I used to be diving deep into supernova knowledge on this weblog, there are actually a whole bunch of different (Kafka) matters on the market ready to be explored.
- I offered the total code so you possibly can run your personal Kafka shopper consuming the info stream and dive into the Knowledge Intelligence Platform or use open supply Apache Spark.
- With the Knowledge Intelligence Platform, accessing supernova knowledge from NASA satellites is as simple as copying and pasting a single SQL command.
- Knowledge engineers, scientists and analysts can simply ingest Kafka knowledge streams from SQL utilizing
read_kafka(). - DLT with AI/BI is the underestimated energy couple within the streaming world. I wager you will notice way more of it sooner or later.
- Windowed stream processing, usually carried out with Apache Kafka, Spark or Flink utilizing advanced statements, might be drastically simplified with Genie on this case. By exploring your tables in a Genie knowledge room, you need to use pure language queries, together with temporal qualifiers like “during the last month” or “on common on a Monday,” to simply analyze and perceive your knowledge stream.
Assets
- All options described on this weblog can be found on GitHub. To entry the challenge, clone the TMM repo with the cone sample
NASA-swift-genie - For extra context, please watch my Knowledge + AI Summit session From Supernovas to LLMs which features a demonstration of a compound AI software that learns from 36,000 NASA circulars utilizing RAG with DBRX and Llama with LangChain (take a look at the mini weblog).
- You will discover all of the playlists from Knowledge + AI Summit on YouTube. For instance, listed here are the lists for Knowledge Engineering and Streaming and Generative AI.
Subsequent Steps
Nothing beats first-hand expertise. I like to recommend working the examples in your personal account. You may attempt Databricks free.