{kind=link}

Introduction
Within the present data-focused society, high-dimensional information vectors at the moment are extra vital than ever for varied makes use of like suggestion techniques, picture recognition, NLP, and anomaly detection. Effectively looking via these vectors at scale will be tough, particularly with datasets containing tens of millions or billions of vectors. Extra superior indexing strategies are wanted as conventional strategies like B-trees and hash tables are insufficient for these conditions.
Vector databases, designed for dealing with and looking vectors, have gained reputation as a result of their fast search velocity, which stems from the indexing strategies they use. This weblog will deep dive into superior vector indexing strategies that energy these databases and guarantee blazing-fast searches, even in high-dimensional areas.
Studying Goals
- Study the significance of vector indexing in high-dimensional search.
- Study the primary strategies of indexing for efficient searches, comparable to Product Quantization (PQ), Approximate Nearest Neighbor Search (ANNS), and HNSW (Hierarchical Navigable Small World graphs).
- Learn to implement these indexing strategies with Python-based libraries like FAISS.
- Discover the optimization methods to make sure environment friendly querying and retrieval at scale.
This text was revealed as part of the Information Science Blogathon.
Challenges of Excessive-Dimensional Vector Search
Trying to find the closest neighbors to a question vector in vector search includes measuring “Closeness” utilizing metrics like Euclidean distance, cosine similarity, or different distance metrics. Brute-force strategies turn into extra computationally costly as the information dimensionality will increase, typically needing linear time complexity, which is O(n), with n representing the variety of vectors.
The notorious curse of dimensionality worsens efficiency by making distance metrics much less significant, including additional overhead to querying. This necessitates the necessity for specialised vector indexing mechanisms.
Superior Indexing Methods
Efficient indexing reduces the search house by creating constructions that permit quicker retrieval. Key strategies embody:
Product Quantization (PQ)
Product Quantization (PQ) is a sophisticated approach that compresses high-dimensional vectors by partitioning them into subspaces and quantizing every subspace independently. This enables us to reinforce the velocity of similarity search duties and enormously lower the quantity of reminiscence wanted.
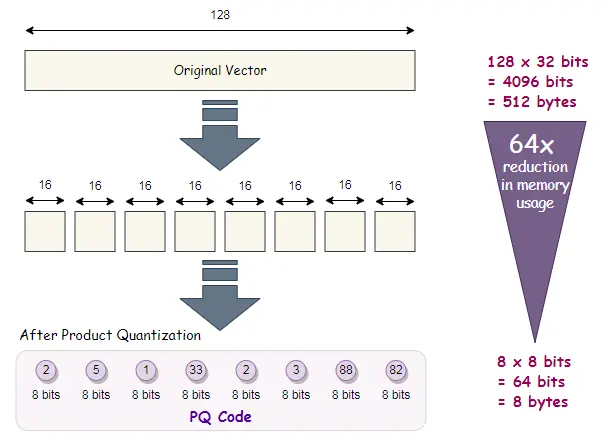
How PQ Works?
- Splitting the Vector: The vector is cut up into m smaller subvectors.
- Quantization: Every subvector is quantized independently utilizing a small codebook (set of centroids).
- Compressed Illustration: The ensuing compressed illustration is a mixture of the quantized subvectors, permitting for environment friendly storage and search.
Implementing PQ with FAISS
import numpy as np
import faiss
# Create a random set of vectors (dimension: 10000 vectors of 128 dimensions)
dimension = 128
n_vectors = 10000
information = np.random.random((n_vectors, dimension)).astype('float32')
# Create a product quantizer index in FAISS
quantizer = faiss.IndexFlatL2(dimension) # L2 distance quantizer
index = faiss.IndexIVFPQ(quantizer, dimension, 100, 8, 8) # PQ index with 8 sub-vectors
# Prepare the index along with your information
index.practice(information)
# Add vectors to the index
index.add(information)
# Carry out a seek for the closest neighbors
query_vector = np.random.random((1, dimension)).astype('float32')
distances, indices = index.search(query_vector, 5)
print(f"Nearest neighbors (indices): {indices}")
print(f"Distances: {distances}")Output:

On this code, we harness FAISS, a library created by Fb AI Analysis, to hold out product quantization. We first create a random set of vectors, practice the index, after which use it for vector search.
Benefits of PQ
- Reminiscence Effectivity: PQ dramatically reduces reminiscence utilization by compressing vectors.
- Pace: Searches over compressed information are quicker than working on full vectors.
Approximate Nearest Neighbor Search (ANNS)
ANNS provides a way to find vectors which might be “roughly” closest to a question vector, sacrificing some precision for a substantial improve in velocity. The 2 mostly used ANNS strategies are LSH (Locality Delicate Hashing) and IVF (Inverted File Index).
Inverted File Index (IVF)
IVF divides the vector house into a number of partitions (or clusters). As a substitute of looking your entire dataset, the search is restricted to vectors that fall inside just a few related clusters.
Implementing IVF with FAISS
# Identical dataset as above
quantizer = faiss.IndexFlatL2(dimension)
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, 100) # 100 clusters
# Prepare the index
index_ivf.practice(information)
# Add vectors to the index
index_ivf.add(information)
# Carry out the search
index_ivf.nprobe = 10 # Search 10 clusters
distances, indices = index_ivf.search(query_vector, 5)
print(f"Nearest neighbors (indices): {indices}")
print(f"Distances: {distances}")Output:

On this code, we created an Inverted File Index and restricted the search to a restricted variety of clusters (managed by the parameter nprobe).
Benefits of ANNS
- Sub-linear Search Time: By limiting the search house, ANNS strategies can obtain near-constant search time, making it possible to deal with very massive datasets.
- Customizable Commerce-off: ANSS strategies present the customized trade-off to fine-tune parameters like nprobe in FAISS to stability between velocity and search accuracy.
Hierarchical Navigable Small World (HNSW)
HNSW is a graph-based technique the place vectors are inserted right into a graph, connecting every node to its nearest neighbors. The exploration happens by shifting greedily via the graph from a randomly chosen node. We’ve got:
- Multi-Layer Graph: The graph consists of a number of layers. To permit a quick navigational search, the decrease layers are densely related whereas the highest layers are sparsely related.
- Grasping Search: The search begins from the topmost layer and progressively strikes down, narrowing right down to the closest neighbors.

Implementing HNSW with FAISS
# HNSW index in FAISS
index_hnsw = faiss.IndexHNSWFlat(dimension, 32) # 32 is the connectivity parameter
# Add vectors to the index
index_hnsw.add(information)
# Carry out the search
distances, indices = index_hnsw.search(query_vector, 5)
print(f"Nearest neighbors (indices): {indices}")
print(f"Distances: {distances}")Output

HNSW has been demonstrated to ship top-notch efficiency when it comes to search velocity whereas additionally sustaining excessive recall charges.
Benefits of HNSW
- Extremely Environment friendly for Massive Datasets: It supplies logarithmic scaling in search time with respect to the dataset dimension.
- Dynamic Updates: New vectors will be added effectively with out retraining your entire index.
Optimizing Vector Indexes for Actual-World Efficiency
Allow us to now on optimize vector indexes for real-world efficiency.
Distance Metrics
The number of the gap measurement (like Euclidean, cosine similarity) enormously impacts the result. Researchers generally use cosine similarity for textual content embeddings, whereas they typically depend on Euclidean distance for picture and audio vectors.
Tuning Index Parameters
Every indexing technique has its tunable parameters. As an illustration:
- nprobe for IVF.
- Sub-vector dimension for PQ.
- Connectivity for HNSW.
Correct tuning of those parameters is important to stability the trade-off between velocity and recall.
Conclusion
Mastering vector indexing is important for constructing high-performance search techniques. Whereas brute-force search over massive datasets is inefficient, superior strategies like Product Quantization, Approximate Nearest Neighbor Search, and HNSW allow ultra-fast retrievals with out compromising accuracy. By leveraging instruments like FAISS and fine-tuning index parameters, builders can create scalable techniques able to dealing with tens of millions of vectors.
Key Takeaways
- Vector indexing drastically reduces search time, making vector databases extremely environment friendly.
- Product Quantization compresses vectors for quicker retrieval, whereas ANNS and HNSW optimize search by limiting the search house.
- Vector databases are scalable and versatile, making them relevant to varied industries, from e-commerce and suggestion techniques to picture retrieval, NLP, and anomaly detection. The right alternative of vector index can result in efficiency enchancment for particular use circumstances.
Often Requested Questions
A. Brute-force search compares the question vector in opposition to all vectors, whereas approximate nearest neighbor (ANN) search narrows down the search house to a small subset, offering quicker outcomes with a slight loss in accuracy.
A. The important thing metrics for the efficiency analysis of a vector database embody Recall, Question Latency, Throughput, Index Construct Time, and Reminiscence Utilization. These metrics assist in assessing the stability between velocity, accuracy, and useful resource utilization
A. Sure, sure vector indexing strategies like HNSW go well with dynamic datasets effectively, enabling environment friendly insertion of latest vectors with out requiring retraining of your entire index. Nonetheless, some strategies, like Product Quantization, could require re-training when massive parts of the dataset change.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.