{kind=link}

People possess an innate understanding of physics, anticipating objects to behave predictably with out abrupt adjustments in place, form, or colour. This basic cognition is noticed in infants, primates, birds, and marine mammals, supporting the core data speculation, which suggests people have evolutionarily developed methods for reasoning about objects, house, and brokers. Whereas AI surpasses people in complicated duties like coding and arithmetic, it struggles with intuitive physics, highlighting Moravec’s paradox. AI approaches to bodily reasoning fall into two classes: structured fashions, which simulate object interactions utilizing predefined guidelines, and pixel-based generative fashions, which predict future sensory inputs with out specific abstractions.
Researchers from FAIR at Meta, Univ Gustave Eiffel, and EHESS discover how general-purpose deep neural networks develop an understanding of intuitive physics by predicting masked areas in pure movies. Utilizing the violation-of-expectation framework, they show that fashions skilled to foretell outcomes in an summary illustration house—corresponding to Joint Embedding Predictive Architectures (JEPAs)—can precisely acknowledge bodily properties like object permanence and form consistency. In distinction, video prediction fashions working in pixel house and multimodal massive language fashions carry out nearer to random guessing. This means that studying in an summary house, slightly than counting on predefined guidelines, is enough to amass an intuitive understanding of physics.
The research focuses on a video-based JEPA mannequin, V-JEPA, which predicts future video frames in a discovered illustration house, aligning with the predictive coding idea in neuroscience. V-JEPA achieved 98% zero-shot accuracy on the IntPhys benchmark and 62% on the InfLevel benchmark, outperforming different fashions. Ablation experiments revealed that intuitive physics understanding emerges robustly throughout completely different mannequin sizes and coaching durations. Even a small 115 million parameter V-JEPA mannequin or one skilled on only one week of video confirmed above-chance efficiency. These findings problem the notion that intuitive physics requires innate core data and spotlight the potential of summary prediction fashions in creating bodily reasoning.
The violation-of-expectation paradigm in developmental psychology assesses intuitive physics understanding by observing reactions to bodily not possible eventualities. Historically utilized to infants, this technique measures shock responses by means of physiological indicators like gaze time. Extra just lately, it has been prolonged to AI methods by presenting them with paired visible scenes, the place one features a bodily impossibility, corresponding to a ball disappearing behind an occluder. The V-JEPA structure, designed for video prediction duties, learns high-level representations by predicting masked parts of movies. This strategy permits the mannequin to develop an implicit understanding of object dynamics with out counting on predefined abstractions, as proven by means of its means to anticipate and react to sudden bodily occasions in video sequences.
V-JEPA was examined on datasets corresponding to IntPhys, GRASP, and InfLevel-lab to benchmark intuitive physics comprehension, assessing properties like object permanence, continuity, and gravity. In comparison with different fashions, together with VideoMAEv2 and multimodal language fashions like Qwen2-VL-7B and Gemini 1.5 professional, V-JEPA achieved considerably larger accuracy, demonstrating that studying in a structured illustration house enhances bodily reasoning. Statistical analyses confirmed its superiority over untrained networks throughout a number of properties, reinforcing that self-supervised video prediction fosters a deeper understanding of real-world physics. These findings spotlight the problem of intuitive physics for present AI fashions and counsel that predictive studying in a discovered illustration house is vital to bettering AI’s bodily reasoning talents.
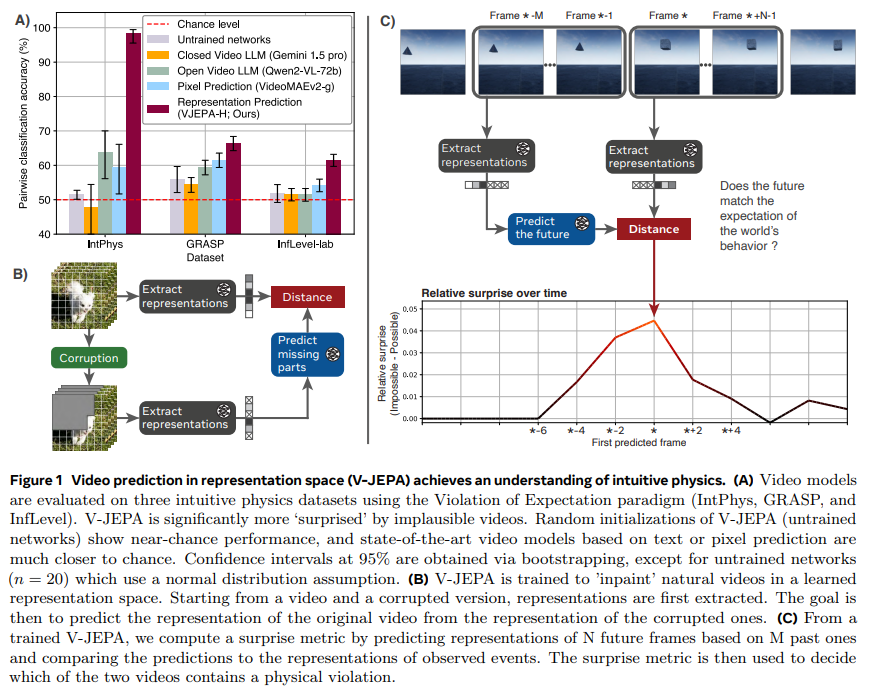
In conclusion, the research explores how state-of-the-art deep studying fashions develop an understanding of intuitive physics. The mannequin demonstrates intuitive physics comprehension with out task-specific adaptation by pretraining V-JEPA on pure movies utilizing a prediction process in a discovered illustration house. Outcomes counsel this means arises from basic studying ideas slightly than hardwired data. Nonetheless, V-JEPA struggles with object interactions, probably because of coaching limitations and brief video processing. Enhancing mannequin reminiscence and incorporating action-based studying might enhance efficiency. Future analysis could look at fashions skilled on infant-like visible information, reinforcing the potential of predictive studying for bodily reasoning in AI.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 75k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
