{kind=link}

Laptop imaginative and prescient is revolutionizing because of the growth of basis fashions in object recognition, picture segmentation, and monocular depth estimation, displaying sturdy zero- and few-shot efficiency throughout numerous downstream duties. Stereo matching, which helps understand depth and create 3D views of scenes, is essential for fields like robotics, self-driving vehicles, and augmented actuality. Nevertheless, the exploration of basis fashions in stereo matching stays restricted because of the problem of acquiring correct disparity floor reality (GT) knowledge. Many stereo datasets exist, however utilizing them successfully for coaching is troublesome. Furthermore, these annotated datasets can’t prepare a great basis mannequin even when mixed.
At present, Stereo-from-mono is a number one research specializing in creating stereo-image pairs and disparity maps immediately from single pictures to handle these challenges. Nevertheless, this strategy resulted in solely 500,000 knowledge samples, which is comparatively low in comparison with the size required to coach sturdy basis fashions successfully. Whereas this effort represents an necessary step in direction of decreasing the dependency on costly stereo knowledge assortment, the generated dataset remains to be inadequate for constructing large-scale fashions able to generalizing effectively to various real-world circumstances. Early Stereo-matching strategies primarily relied on hand-crafted options however shifted to CNN-based mostly fashions like GCNet and PSMNet, bettering accuracy with strategies like 3D value aggregation. Video stereo matching makes use of temporal knowledge for consistency however struggles with generalization. Cross-domain strategies tackle this by studying domain-invariant options utilizing strategies like unsupervised adaptation and contrastive studying, as seen in fashions like RAFT–Stereo and FormerStereo.
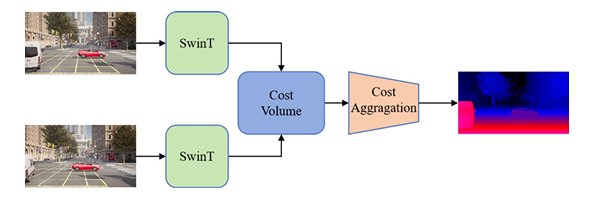
A bunch of researchers from Faculty of Laptop Science, Wuhan College, Institute of Synthetic Intelligence and Robotics, Xi’an Jiaotong College, Waytous, College of Bologna, Rock Universe, Institute of Automation, Chinese language Academy of Sciences and College of California, Berkeley performed detailed analysis to beat these points and proposed StereoAnything, a foundational mannequin for stereo matching developed to supply high-quality disparity estimates for any pair of matching stereo pictures, irrespective of how advanced the scene or difficult the environmental circumstances. It’s designed to coach a strong stereo community utilizing large-scale blended knowledge. It primarily consists of 4 elements: function extraction, value building, value aggregation, and disparity regression.
To enhance generalization, Supervised stereo knowledge was used with out depth normalization, as stereo matching depends on scale data. The coaching started with a single dataset and mixed top-ranked datasets to enhance robustness. For single-image studying, monocular depth fashions predicted depth transformed into disparity maps to generate real looking stereo pairs by way of ahead warping. Occlusions and gaps have been crammed utilizing textures from different pictures within the dataset.

The experiment confirmed the analysis of the StereoAnything framework utilizing OpenStereo and NMRF-Stereo baselines with Swin Transformer for function extraction. Coaching used AdamW optimizer, OneCycleLR scheduling, and fine-tuning on labeled, blended, and pseudo-labeled datasets with knowledge augmentation. Testing on KITTI, Middlebury, ETH3D, and DrivingStereo confirmed StereoAnything considerably diminished errors, with NMRF-Stereo-SwinT reducing the imply error from 18.11 to five.01. Advantageous-tuning StereoCarla on extra various datasets result in one of the best imply metric of 8.52%. This confirmed the significance of dataset range when regarding stereo-matching efficiency.
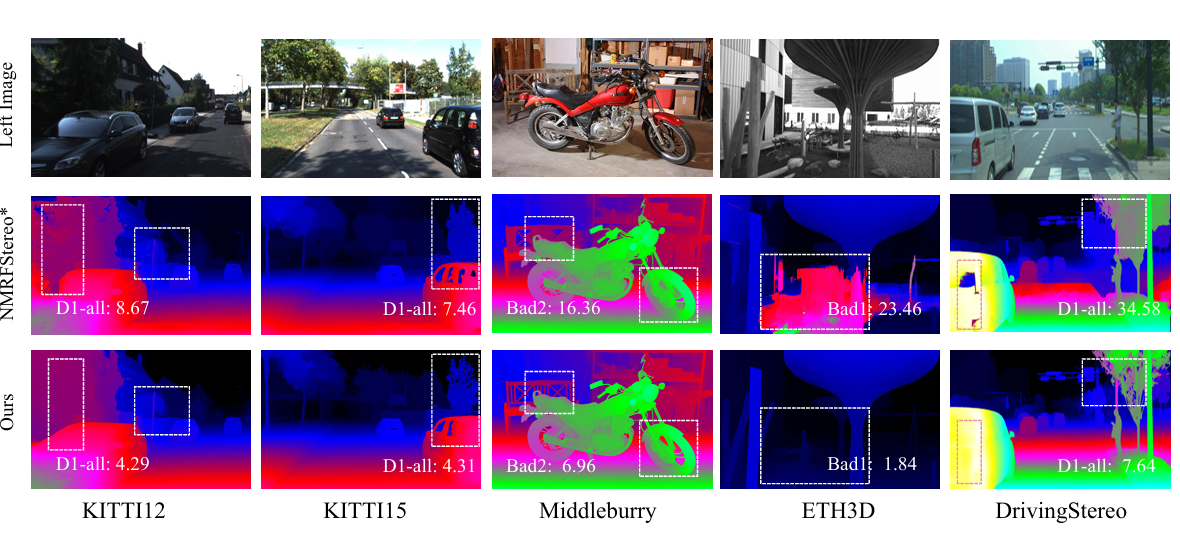
When it comes to outcomes, the StereoAnything confirmed sturdy robustness throughout numerous domains in each indoor and out of doors scenes. This strategy always delivered a disparity map that was extra correct than with the NMRF-Stereo-SwinTmode. Thus, this strategy exhibits sturdy generalization capabilities and performs higher throughout domains with quite a few visible and environmental variations.
It’s secure to conclude that StereoAnything offered a extremely helpful resolution for sturdy stereo matching. A brand new synthetic dataset known as StereoCarla is used to raised generalize throughout completely different situations and improve efficiency. Additionally, the effectiveness of labeled stereo datasets and pseudo stereo datasets generated utilizing monocular depth estimation fashions was investigated. When it comes to efficiency, StereoAnything achieved aggressive efficiency throughout numerous benchmarks and real-world situations. These outcomes present the potential of hybrid coaching methods, together with various knowledge sources to reinforce stereo mannequin robustness, and can be utilized because the baseline for future enchancment and analysis!
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and remedy challenges.