
Efficient lesson structuring stays a crucial problem in academic settings, significantly when conversations and tutoring periods want to handle predefined matters or worksheet issues. Educators face the complicated activity of optimally allocating time throughout completely different issues whereas accommodating numerous pupil studying wants. This problem is particularly pronounced for novice academics and people managing massive pupil teams, who continuously wrestle with time administration and lesson group. Whereas evidence-based insights into lesson structuring might present worthwhile suggestions to educators, tutoring platforms, and curriculum builders, acquiring such insights at scale presents vital difficulties. The evaluation of dialog construction round reference supplies entails two distinct pure language processing challenges: discourse segmentation and data retrieval, every presenting distinctive complexities when utilized to academic conversations the place educating approaches range based mostly on pupil wants.
Earlier approaches to dialog evaluation have primarily targeted on discourse segmentation as a preprocessing step for retrieval or summarization duties. Conventional strategies section conversations based mostly on varied standards like speech acts, matters, or dialog phases, relying on the area. When utilized to academic contexts, particularly for problem-oriented segments in arithmetic discussions, these typical approaches face vital limitations. Customary segmentation strategies function beneath the belief that conversations observe predictable patterns and constructions, which proves insufficient for academic conversations which might be inherently numerous and adaptable. Additionally, mathematical data retrieval presents distinctive challenges because of the complexity of representing mathematical expressions of their correct context. The distinctive nature of mathematical discourse, mixed with the variable construction of academic conversations, has highlighted the inadequacy of current approaches in successfully analyzing and retrieving problem-oriented segments from mathematical tutoring periods.
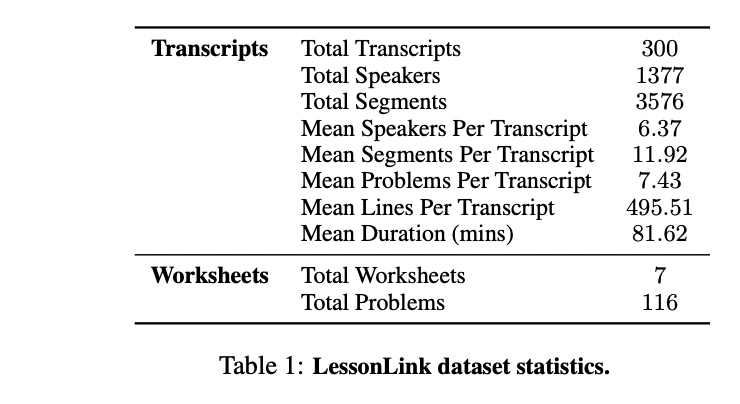
Researchers from Stanford College launched the Drawback-Oriented Segmentation and Retrieval (POSR) framework, a singular strategy that concurrently handles dialog segmentation and hyperlinks these segments to corresponding reference supplies. This built-in strategy distinguishes itself from conventional strategies by using identified reference matters to information each segmentation and retrieval processes, significantly in academic contexts. The framework’s effectiveness is demonstrated by way of LessonLink, a complete dataset designed to investigate mathematical tutoring periods. LessonLink encompasses 3,500 segments drawn from real-world tutoring conversations, masking 116 SAT® math issues throughout greater than 24,300 minutes of instruction. Every 1.5-hour dialog within the dataset is meticulously segmented and mapped to particular math issues, creating the first-ever assortment that mixes naturally structured conversations with their corresponding worksheet supplies.
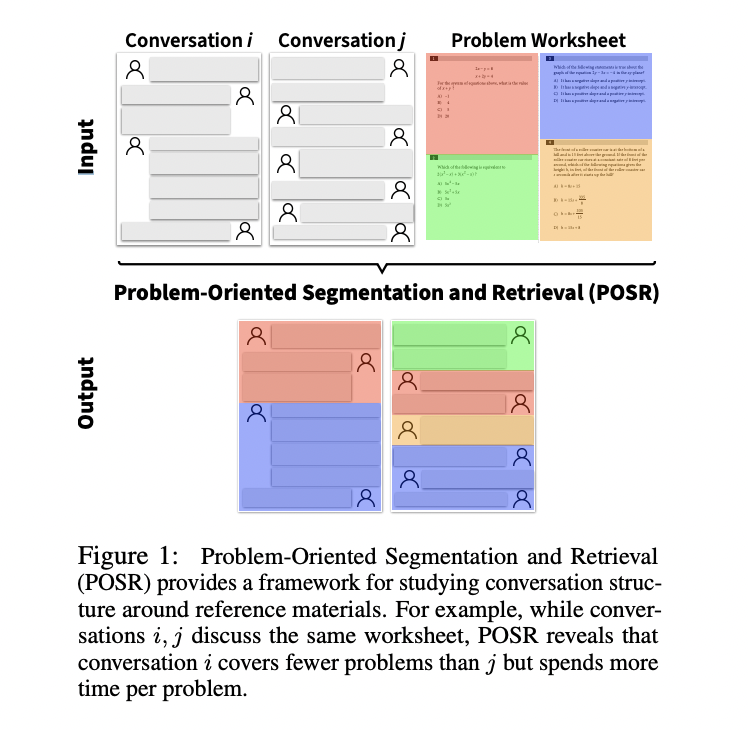
The POSR framework employs an modern algorithmic strategy that integrates segmentation and retrieval processes to investigate conversational transcripts extra successfully. The system operates by way of a dual-phase course of: first, it segments the dialog transcript whereas contemplating the accessible reference supplies (not like conventional strategies that section with out this context), and second, it retrieves related matters or issues for every recognized section. This built-in strategy permits higher segmentation accuracy by way of consciousness of potential retrieval matters whereas concurrently bettering retrieval precision by way of better-defined segments. When utilized to the LessonLink dataset, the framework processes in depth tutoring conversations, dealing with enter from 1,300 distinctive audio system and establishing connections to 116 distinct math issues. The algorithm’s design displays a big development over typical strategies by sustaining contextual consciousness all through each the segmentation and retrieval phases, resulting in extra correct and significant evaluation of academic conversations.

The experimental outcomes display the superior efficiency of POSR strategies in comparison with conventional impartial segmentation and retrieval approaches. POSR Opus and POSR GPT4 achieved larger accuracy in each Line-SRS and Time-SRS metrics in comparison with their impartial counterparts and mixed impartial approaches like Opus+TFIDF. Additionally, POSR Opus confirmed vital enchancment over typical subject and stage segmentation strategies, decreasing error charges by roughly 57% on each Pk and WindowDiff metrics. The framework’s cost-effectiveness is especially noteworthy, with POSR strategies requiring solely $11-$21 per 100 transcripts, in comparison with $54 for mixed impartial strategies like Opus+GPT4. The poor efficiency of word-level segmentation approaches (top-10 and top-20) highlighted the need of extra subtle evaluation strategies. Each time-based and line-based metrics confirmed robust correlation throughout strategies, although time-weighted metrics proved worthwhile in higher dealing with lengthy section errors, with Time-Pk displaying decrease error charges than Line-Pk for over-segmentation circumstances.


The introduction of Drawback-Oriented Segmentation and Retrieval (POSR) marks a big development in analyzing academic conversations, significantly by way of its strong joint strategy to segmentation and retrieval duties. The framework’s effectiveness is validated by way of the LessonLink dataset, which supplies unprecedented insights into real-world tutoring periods. Whereas LLM-based POSR strategies display superior efficiency in accuracy metrics, their larger operational prices spotlight the necessity for less expensive options. The framework’s success in analyzing tutoring methods and dialog constructions establishes POSR as a worthwhile device for understanding and bettering academic conversations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Providers and Actual Property Transactions– From Framework to Manufacturing
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.