{kind=link}

Synthetic intelligence in multi-agent environments has made important strides, significantly in reinforcement studying. One of many core challenges on this area is creating AI brokers able to speaking successfully by way of pure language. That is significantly important in settings the place every agent has solely partial visibility of the surroundings, making knowledge-sharing important for reaching collective targets. Social deduction video games present a perfect framework for testing AI’s means to infer info by way of conversations, as these video games require reasoning, deception detection, and strategic collaboration.
A key concern in AI-driven social deduction is making certain that brokers can conduct significant discussions with out counting on human demonstrations. Many language fashions falter in multi-agent settings resulting from their dependence on huge datasets of human conversations. The problem intensifies as AI brokers battle to evaluate whether or not their contributions meaningfully affect decision-making. With no clear mechanism to judge the usefulness of their messages, they usually generate unstructured and ineffective communication, resulting in suboptimal efficiency in strategic video games that require deduction and persuasion.
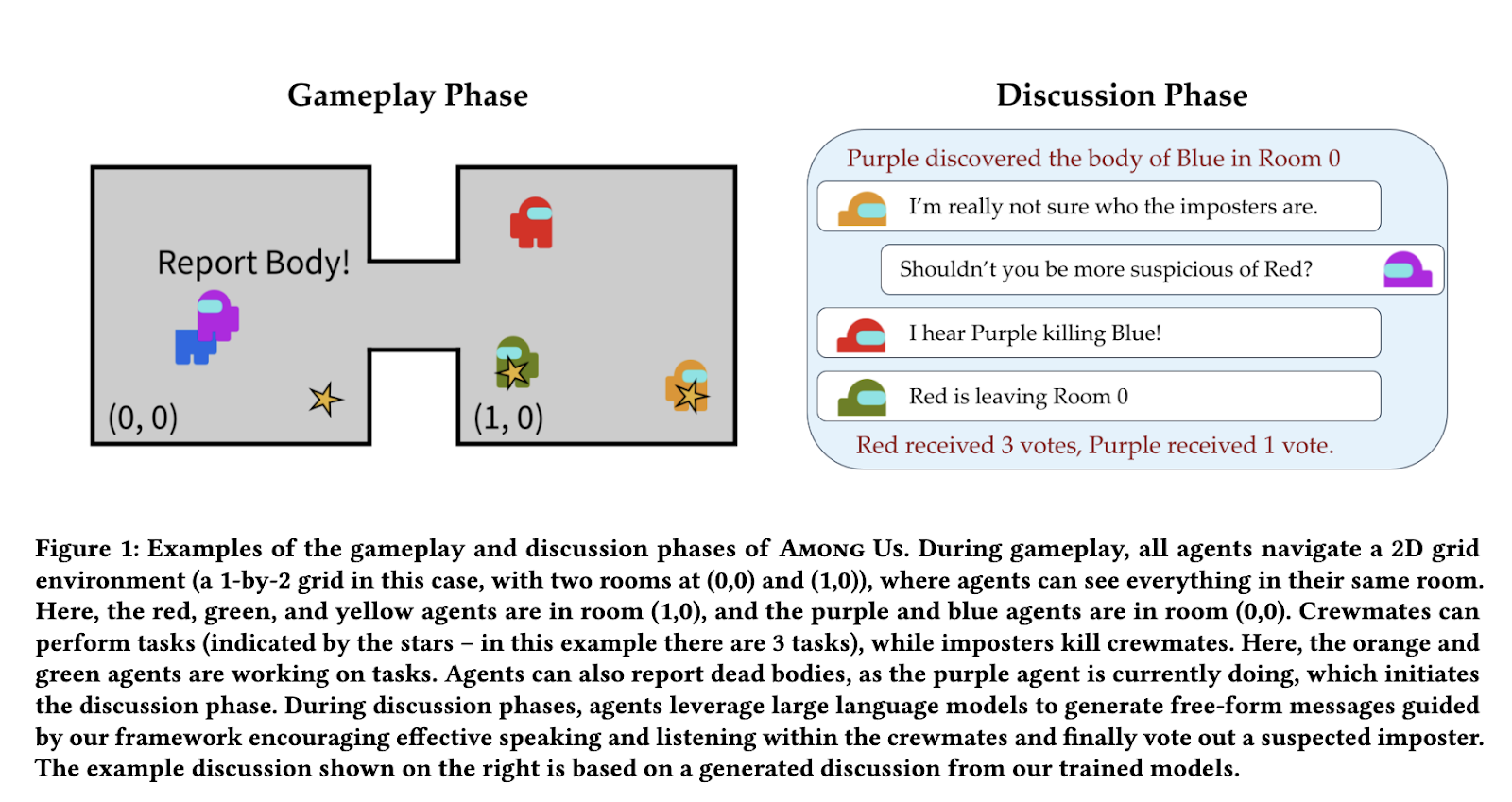
Current reinforcement studying approaches try to deal with this drawback however ceaselessly fall brief. Some methods rely on pre-existing datasets of human interactions, which aren’t at all times out there or adaptable to new situations. Others incorporate language fashions with reinforcement studying however fail resulting from sparse suggestions, which makes it troublesome for AI to refine its dialogue methods. Conventional strategies can not thus systematically enhance communication expertise over time, making AI discussions in multi-agent environments much less efficient.
A analysis workforce from Stanford College launched an modern technique for coaching AI brokers in social deduction settings with out human demonstrations—their strategy leverages multi-agent reinforcement studying to develop AI able to understanding and articulating significant arguments. The analysis focuses on the sport *Amongst Us*, the place crewmates should determine an imposter by way of verbal discussions. The researchers designed a coaching mechanism that divides communication into listening and talking, permitting the AI to optimize each expertise independently. The strategy integrates a structured reward system that progressively allows brokers to refine their dialogue methods.
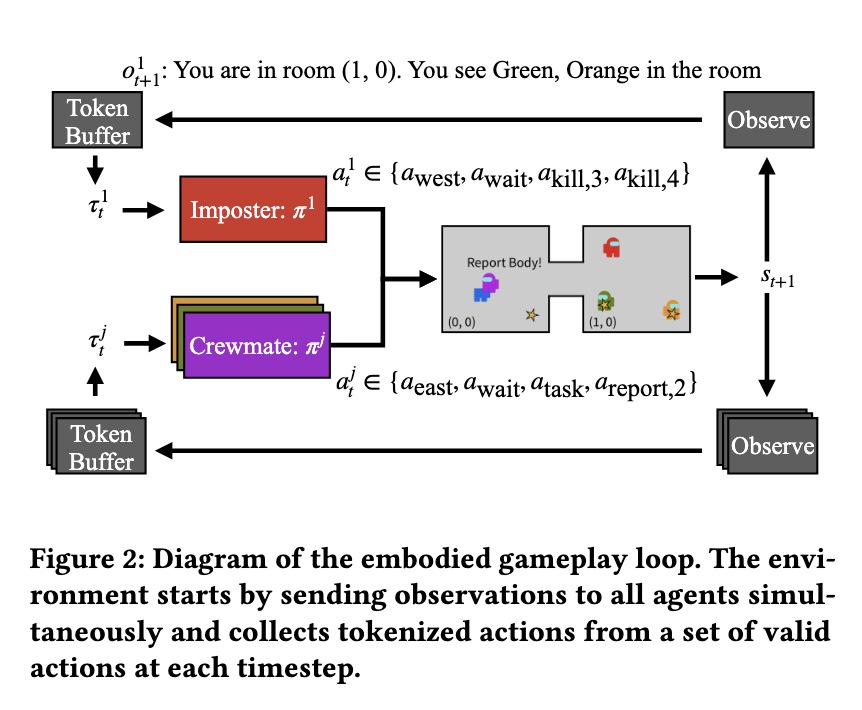
The methodology introduces a dense reward sign that gives exact suggestions to enhance communication. AI brokers improve their listening skills by predicting environmental particulars primarily based on prior discussions. On the similar time, their talking proficiency improves by way of reinforcement studying, the place messages are assessed primarily based on their affect on different brokers’ beliefs. This structured strategy ensures that AI-generated messages are logical, persuasive, and related to the dialog. The analysis workforce employed RWKV, a recurrent neural community mannequin, as the muse for his or her coaching, optimizing it for long-form discussions and dynamic gameplay environments.
Experimental outcomes demonstrated that this coaching strategy considerably improved AI efficiency in comparison with conventional reinforcement studying methods. The educated AI exhibited behaviors akin to human gamers, together with suspect accusation, proof presentation, and reasoning primarily based on noticed actions. The research confirmed that AI fashions using this structured dialogue studying framework achieved a win price of roughly 56%, in comparison with the 28% win price of reinforcement studying fashions with out the structured dialogue framework. Moreover, the AI educated utilizing this technique outperformed fashions 4 instances bigger in dimension, underscoring the effectivity of the proposed coaching technique. When analyzing dialogue behaviors, the analysis workforce noticed that the AI may precisely determine imposters at a hit price twice as excessive as baseline reinforcement studying approaches.
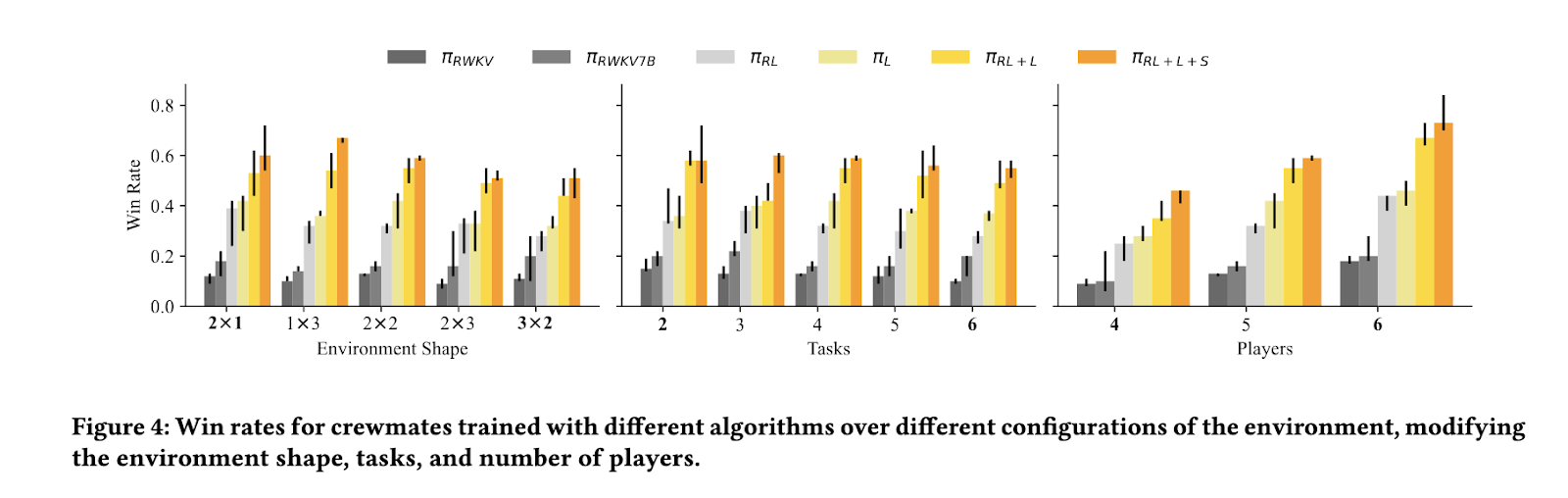
Additional evaluation revealed that AI fashions educated underneath this framework tailored successfully to adversarial methods. Imposters tried to govern discussions by shifting blame, initially complicated AI crewmates. Nonetheless, the AI brokers realized to distinguish between real accusations and deceptive statements by way of iterative coaching. Researchers discovered that AI-generated messages that explicitly named a suspect have been extra prone to affect group selections. This emergent conduct carefully resembled human instinct, indicating that the AI may adapt dialogue methods dynamically.
This analysis marks a major development in AI-driven social deduction. By addressing the communication challenges in multi-agent settings, the research gives a structured and efficient framework for coaching AI brokers to interact in significant discussions with out counting on intensive human demonstrations. The proposed technique enhances AI decision-making, permitting for extra persuasive and logical reasoning in environments that require collaboration and the detection of deception. The analysis opens prospects for broader purposes, together with AI assistants able to analyzing complicated discussions, negotiating, and strategizing in real-world situations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.