
Unlocking the true worth of knowledge typically will get impeded by siloed data. Conventional knowledge administration—whereby every enterprise unit ingests uncooked knowledge in separate knowledge lakes or warehouses—hinders visibility and cross-functional evaluation. An information mesh framework empowers enterprise items with knowledge possession and facilitates seamless sharing.
Nonetheless, integrating datasets from completely different enterprise items can current a number of challenges. Every enterprise unit exposes knowledge belongings with various codecs and granularity ranges, and applies completely different knowledge validation checks. Unifying these necessitates further knowledge processing, requiring every enterprise unit to provision and keep a separate knowledge warehouse. This burdens enterprise items targeted solely on consuming the curated knowledge for evaluation and never involved with knowledge administration duties, cleaning, or complete knowledge processing.
On this publish, we discover a strong structure sample of a knowledge sharing mechanism by bridging the hole between knowledge lake and knowledge warehouse utilizing Amazon DataZone and Amazon Redshift.
Resolution overview
Amazon DataZone is a knowledge administration service that makes it easy for enterprise items to catalog, uncover, share, and govern their knowledge belongings. Enterprise items can curate and expose their available domain-specific knowledge merchandise via Amazon DataZone, offering discoverability and managed entry.
Amazon Redshift is a quick, scalable, and absolutely managed cloud knowledge warehouse that lets you course of and run your advanced SQL analytics workloads on structured and semi-structured knowledge. 1000’s of shoppers use Amazon Redshift knowledge sharing to allow instantaneous, granular, and quick knowledge entry throughout Amazon Redshift provisioned clusters and serverless workgroups. This lets you scale your learn and write workloads to 1000’s of concurrent customers with out having to maneuver or copy the information. Amazon DataZone natively helps knowledge sharing for Amazon Redshift knowledge belongings. With Amazon Redshift Spectrum, you may question the information in your Amazon Easy Storage Service (Amazon S3) knowledge lake utilizing a central AWS Glue metastore out of your Redshift knowledge warehouse. This functionality extends your petabyte-scale Redshift knowledge warehouse to unbounded knowledge storage limits, which lets you scale to exabytes of knowledge cost-effectively.
The next determine exhibits a typical distributed and collaborative architectural sample applied utilizing Amazon DataZone. Enterprise items can merely share knowledge and collaborate by publishing and subscribing to the information belongings.

The Central IT group (Spoke N) subscribes the information from particular person enterprise items and consumes this knowledge utilizing Redshift Spectrum. The Central IT group applies standardization and performs the duties on the subscribed knowledge akin to schema alignment, knowledge validation checks, collating the information, and enrichment by including further context or derived attributes to the ultimate knowledge asset. This processed unified knowledge can then persist as a brand new knowledge asset in Amazon Redshift managed storage to fulfill the SLA necessities of the enterprise items. The brand new processed knowledge asset produced by the Central IT group is then printed again to Amazon DataZone. With Amazon DataZone, particular person enterprise items can uncover and immediately devour these new knowledge belongings, gaining insights to a holistic view of the information (360-degree insights) throughout the group.
The Central IT group manages a unified Redshift knowledge warehouse, dealing with all knowledge integration, processing, and upkeep. Enterprise items entry clear, standardized knowledge. To devour the information, they’ll select between a provisioned Redshift cluster for constant high-volume wants or Amazon Redshift Serverless for variable, on-demand evaluation. This mannequin permits the items to give attention to insights, with prices aligned to precise consumption. This permits the enterprise items to derive worth from knowledge with out the burden of knowledge administration duties.
This streamlined structure method gives a number of benefits:
- Single supply of reality – The Central IT group acts because the custodian of the mixed and curated knowledge from all enterprise items, thereby offering a unified and constant dataset. The Central IT group implements knowledge governance practices, offering knowledge high quality, safety, and compliance with established insurance policies. A centralized knowledge warehouse for processing is commonly extra cost-efficient, and its scalability permits organizations to dynamically alter their storage wants. Equally, particular person enterprise items produce their very own domain-specific knowledge. There aren’t any duplicate knowledge merchandise created by enterprise items or the Central IT group.
- Eliminating dependency on enterprise items – Redshift Spectrum makes use of a metadata layer to immediately question the information residing in S3 knowledge lakes, eliminating the necessity for knowledge copying or counting on particular person enterprise items to provoke the copy jobs. This considerably reduces the danger of errors related to knowledge switch or motion and knowledge copies.
- Eliminating stale knowledge – Avoiding duplication of knowledge additionally eliminates the danger of stale knowledge current in a number of areas.
- Incremental loading – As a result of the Central IT group can immediately question the information on the information lakes utilizing Redshift Spectrum, they’ve the flexibleness to question solely the related columns wanted for the unified evaluation and aggregations. This may be carried out utilizing mechanisms to detect the incremental knowledge from the information lakes and course of solely the brand new or up to date knowledge, additional optimizing useful resource utilization.
- Federated governance – Amazon DataZone facilitates centralized governance insurance policies, offering constant knowledge entry and safety throughout all enterprise items. Sharing and entry controls stay confined inside Amazon DataZone.
- Enhanced value appropriation and effectivity – This methodology confines the associated fee overhead of processing and integrating the information with the Central IT group. Particular person enterprise items can provision the Redshift Serverless knowledge warehouse to solely devour the information. This manner, every unit can clearly demarcate the consumption prices and impose limits. Moreover, the Central IT group can select to use chargeback mechanisms to every of those items.
On this publish, we use a simplified use case, as proven within the following determine, to bridge the hole between knowledge lakes and knowledge warehouses utilizing Redshift Spectrum and Amazon DataZone.

The underwriting enterprise unit curates the information asset utilizing AWS Glue and publishes the information asset Insurance policies in Amazon DataZone. The Central IT group subscribes to the information asset from the underwriting enterprise unit.
We give attention to how the Central IT group consumes the subscribed knowledge lake asset from enterprise items utilizing Redshift Spectrum and creates a brand new unified knowledge asset.
Conditions
The next stipulations have to be in place:
- AWS accounts – It is best to have energetic AWS accounts earlier than you proceed. If you happen to don’t have one, seek advice from How do I create and activate a brand new AWS account? On this publish, we use three AWS accounts. If you happen to’re new to Amazon DataZone, seek advice from Getting began.
- A Redshift knowledge warehouse – You possibly can create a provisioned cluster following the directions in Create a pattern Amazon Redshift cluster, or provision a serverless workgroup following the directions in Get began with Amazon Redshift Serverless knowledge warehouses.
- Amazon Knowledge Zone sources – You want a website for Amazon DataZone, an Amazon DataZone venture, and a new Amazon DataZone surroundings (with a customized AWS service blueprint).
- Knowledge lake asset – The information lake asset
Insurance policiesfrom the enterprise items was already onboarded to Amazon DataZone and subscribed by the Central IT group. To grasp affiliate a number of accounts and devour the subscribed belongings utilizing Amazon Athena, seek advice from Working with related accounts to publish and devour knowledge. - Central IT surroundings – The Central IT group has created an surroundings known as
env_central_teamand makes use of an current AWS Identification and Entry Administration (IAM) function known ascustom_role, which grants Amazon DataZone entry to AWS companies and sources, akin to Athena, AWS Glue, and Amazon Redshift, on this surroundings. So as to add all of the subscribed knowledge belongings to a typical AWS Glue database, the Central IT group configures a subscription goal and makes use ofcentral_dbbecause the AWS Glue database. - IAM function – Make it possible for the IAM function that you simply wish to allow within the Amazon DataZone surroundings has essential permissions to your AWS companies and sources. The next instance coverage gives ample AWS Lake Formation and AWS Glue permissions to entry Redshift Spectrum:
As proven within the following screenshot, the Central IT group has subscribed to the information Insurance policies. The information asset is added to the env_central_team surroundings. Amazon DataZone will assume the custom_role to assist federate the surroundings consumer (central_user) to the motion hyperlink in Athena. The subscribed asset Insurance policies is added to the central_db database. This asset is then queried and consumed utilizing Athena.

The objective of the Central IT group is to devour the subscribed knowledge lake asset Insurance policies with Redshift Spectrum. This knowledge is additional processed and curated into the central knowledge warehouse utilizing the Amazon Redshift Question Editor v2 and saved as a single supply of reality in Amazon Redshift managed storage. Within the following sections, we illustrate devour the subscribed knowledge lake asset Insurance policies from Redshift Spectrum with out copying the information.
Routinely mount entry grants to the Amazon DataZone surroundings function
Amazon Redshift routinely mounts the AWS Glue Knowledge Catalog within the Central IT Staff account as a database and permits it to question the information lake tables with three-part notation. That is out there by default with the Admin function.
To grant the required entry to the mounted Knowledge Catalog tables for the surroundings function (custom_role), full the next steps:
- Log in to the Amazon Redshift Question Editor v2 utilizing the Amazon DataZone deep hyperlink.
- Within the Question Editor v2, select your Redshift Serverless endpoint and select Edit Connection.
- For Authentication, choose Federated consumer.
- For Database, enter the database you wish to hook up with.
- Get the present consumer IAM function as illustrated within the following screenshot.

- Connect with Redshift Question Editor v2 utilizing the database consumer title and password authentication methodology. For instance, hook up with
devdatabase utilizing the admin consumer title and password. Grant utilization on theawsdatacatalogdatabase to the surroundings consumer functioncustom_role(change the worth of current_user with the worth you copied):
{kind=link}
Question utilizing Redshift Spectrum
Utilizing the federated consumer authentication methodology, log in to Amazon Redshift. The Central IT group will be capable to question the subscribed knowledge asset Insurance policies (desk: coverage) that was routinely mounted underneath awsdatacatalog.

Mixture tables and unify merchandise
The Central IT group applies the mandatory checks and standardization to combination and unify the information belongings from all enterprise items, bringing them on the similar granularity. As proven within the following screenshot, each the Insurance policies and Claims knowledge belongings are mixed to type a unified combination knowledge asset known as agg_fraudulent_claims.

These unified knowledge belongings are then printed again to the Amazon DataZone central hub for enterprise items to devour them.
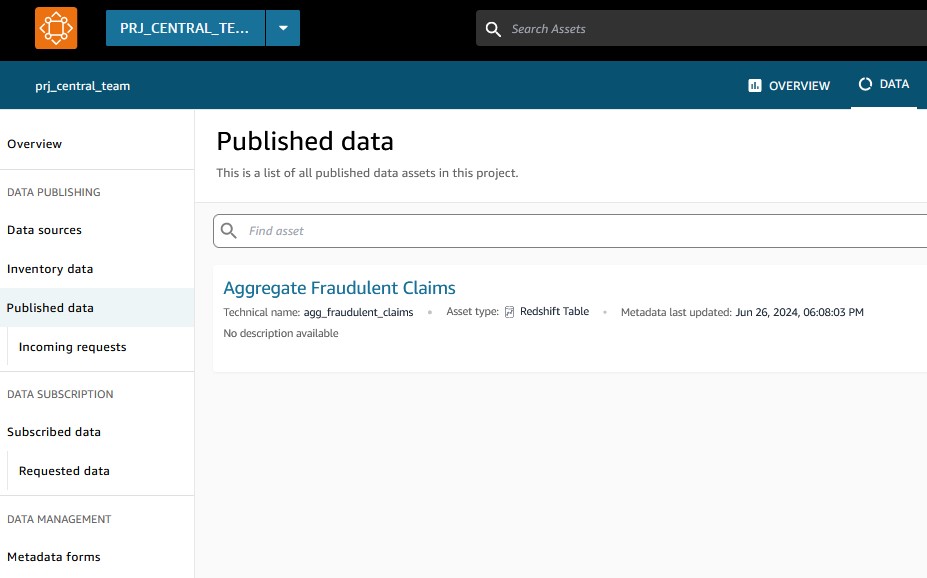
The Central IT group additionally unloads the information belongings to Amazon S3 so that every enterprise unit has the flexibleness to make use of both a Redshift Serverless knowledge warehouse or Athena to devour the information. Every enterprise unit can now isolate and put limits to the consumption prices on their particular person knowledge warehouses.
As a result of the intention of the Central IT group was to devour knowledge lake belongings inside a knowledge warehouse, the really helpful resolution could be to make use of customized AWS service blueprints and deploy them as a part of one surroundings. On this case, we created one surroundings (env_central_team) to devour the asset utilizing Athena or Amazon Redshift. This accelerates the event of the information sharing course of as a result of the identical surroundings function is used to handle the permissions throughout a number of analytical engines.
Clear up
To scrub up your sources, full the next steps:
- Delete any S3 buckets you created.
- On the Amazon DataZone console, delete the tasks used on this publish. It will delete most project-related objects like knowledge belongings and environments.
- Delete the Amazon DataZone area.
- On the Lake Formation console, delete the Lake Formation admins registered by Amazon DataZone together with the tables and databases created by Amazon DataZone.
- If you happen to used a provisioned Redshift cluster, delete the cluster. If you happen to used Redshift Serverless, delete any tables created as a part of this publish.
Conclusion
On this publish, we explored a sample of seamless knowledge sharing with knowledge lakes and knowledge warehouses with Amazon DataZone and Redshift Spectrum. We mentioned the challenges related to conventional knowledge administration approaches, knowledge silos, and the burden of sustaining particular person knowledge warehouses for enterprise items.
With a view to curb working and upkeep prices, we proposed an answer that makes use of Amazon DataZone as a central hub for knowledge discovery and entry management, the place enterprise items can readily share their domain-specific knowledge. To consolidate and unify the information from these enterprise items and supply a 360-degree perception, the Central IT group makes use of Redshift Spectrum to immediately question and analyze the information residing of their respective knowledge lakes. This eliminates the necessity for creating separate knowledge copy jobs and duplication of knowledge residing in a number of locations.
The group additionally takes on the duty of bringing all the information belongings to the identical granularity and course of a unified knowledge asset. These mixed knowledge merchandise can then be shared via Amazon DataZone to those enterprise items. Enterprise items can solely give attention to consuming the unified knowledge belongings that aren’t particular to their area. This manner, the processing prices might be managed and tightly monitored throughout all enterprise items. The Central IT group may also implement chargeback mechanisms based mostly on the consumption of the unified merchandise for every enterprise unit.
To study extra about Amazon DataZone and get began, seek advice from Getting began. Try the YouTube playlist for a few of the newest demos of Amazon DataZone and extra details about the capabilities out there.
Concerning the Authors
 Lakshmi Nair is a Senior Analytics Specialist Options Architect at AWS. She focuses on designing superior analytics programs throughout industries. She focuses on crafting cloud-based knowledge platforms, enabling real-time streaming, large knowledge processing, and strong knowledge governance.
Lakshmi Nair is a Senior Analytics Specialist Options Architect at AWS. She focuses on designing superior analytics programs throughout industries. She focuses on crafting cloud-based knowledge platforms, enabling real-time streaming, large knowledge processing, and strong knowledge governance.
 Srividya Parthasarathy is a Senior Large Knowledge Architect on the AWS Lake Formation group. She enjoys constructing analytics and knowledge mesh options on AWS and sharing them with the group.
Srividya Parthasarathy is a Senior Large Knowledge Architect on the AWS Lake Formation group. She enjoys constructing analytics and knowledge mesh options on AWS and sharing them with the group.