{kind=link}

Language fashions (LMs) have considerably progressed by way of elevated computational energy throughout coaching, primarily by way of large-scale self-supervised pretraining. Whereas this strategy has yielded highly effective fashions, a brand new paradigm known as test-time scaling has emerged, specializing in bettering efficiency by rising computation at inference time. OpenAI’s o1 mannequin has validated this strategy, displaying enhanced reasoning capabilities by way of test-time compute scaling. Nonetheless, replicating these outcomes has confirmed difficult, with varied makes an attempt utilizing methods like Monte Carlo Tree Search (MCTS), multi-agent approaches, and reinforcement studying. Even fashions like DeepSeek R1 have used tens of millions of samples and sophisticated coaching levels, but none have replicated the test-time scaling habits in o1.
Numerous strategies have been developed to deal with the test-time scaling problem. Sequential scaling approaches allow fashions to generate successive answer makes an attempt, with every iteration constructing upon earlier outcomes. Tree-based search strategies mix sequential and parallel scaling, implementing methods like MCTS and guided beam search. REBASE has emerged as a notable strategy, using a course of reward mannequin to optimize tree search by way of balanced exploitation and pruning, displaying superior efficiency in comparison with sampling-based strategies and MCTS. These approaches closely depend on reward fashions, which are available two types: consequence reward fashions for evaluating full options in Greatest-of-N choice, and course of reward fashions for assessing particular person reasoning steps in tree-based search strategies.
Researchers from Stanford College, the College of Washington, the Allen Institute for AI, and Contextual AI have proposed a streamlined strategy to realize test-time scaling and enhanced reasoning capabilities. Their methodology facilities on two key improvements: the rigorously curated s1K dataset comprising 1,000 questions with reasoning traces, chosen primarily based on problem, range, and high quality standards, and a novel approach known as finances forcing. This budget-forcing mechanism controls test-time computation by both chopping quick or extending the mannequin’s considering course of by way of strategic “Wait” insertions, enabling the mannequin to overview and proper its reasoning. The strategy was applied by fine-tuning the Qwen2.5-32B-Instruct language mannequin on the s1K dataset.
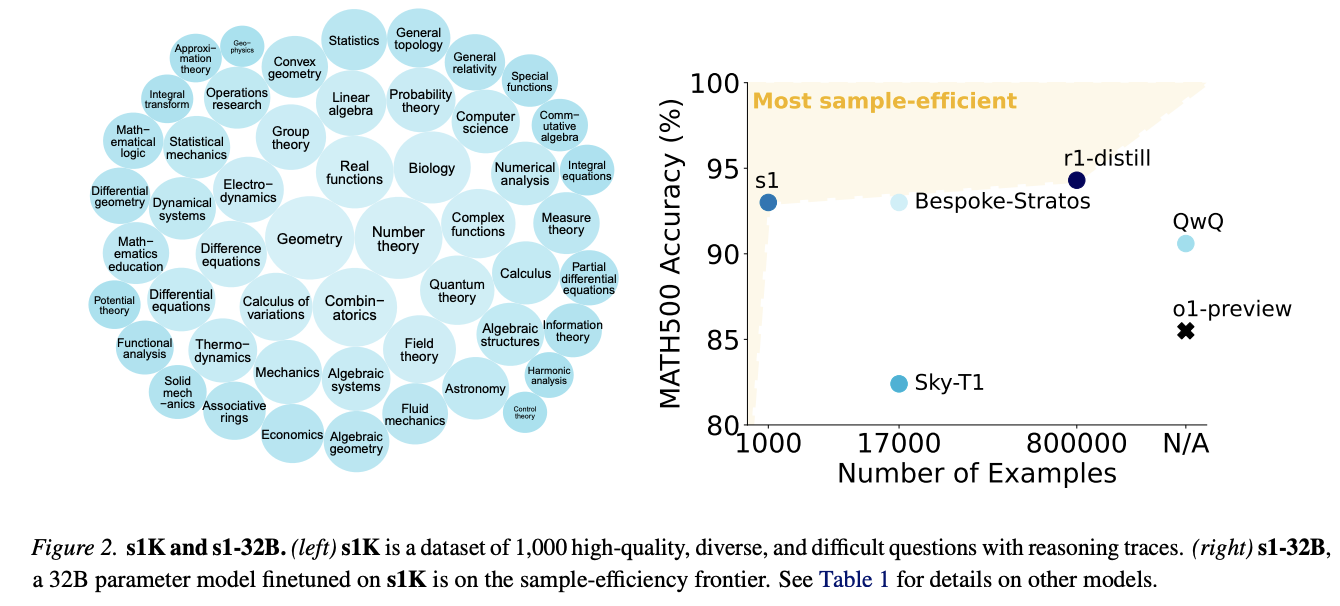
The info choice course of follows a three-stage filtering strategy primarily based on high quality, problem, and variety standards. The standard filtering stage begins by eradicating samples with API errors and formatting points, lowering the preliminary dataset to 51,581 examples, from which 384 high-quality samples are initially chosen. The problem evaluation employs two key metrics: mannequin efficiency analysis utilizing Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct fashions, with correctness verified by Claude 3.5 Sonnet, and reasoning hint size measured by the Qwen2.5 tokenizer. For range, questions are categorized into particular domains utilizing the Arithmetic Topic Classification system by way of Claude 3.5 Sonnet. This complete filtering course of leads to a ultimate dataset of 1,000 samples spanning 50 domains.
The s1-32B mannequin demonstrates important efficiency enhancements by way of test-time compute scaling with finances forcing. s1-32B operates in a superior scaling paradigm in comparison with the bottom Qwen2.5-32B-Instruct mannequin utilizing majority voting, validating the effectiveness of sequential scaling over parallel approaches. Furthermore, s1-32B emerges as essentially the most environment friendly open knowledge reasoning mannequin in pattern effectivity, displaying marked enchancment over the bottom mannequin with simply 1,000 extra coaching samples. Whereas r1-32B achieves higher efficiency it requires 800 occasions extra coaching knowledge. Notably, s1-32B approaches Gemini 2.0 Pondering’s efficiency on AIME24, suggesting profitable data distillation.
This paper exhibits that Supervised Wonderful-Tuning (SFT) with simply 1,000 rigorously chosen examples can create a aggressive reasoning mannequin that matches the o1-preview’s efficiency and achieves optimum effectivity. The launched finances forcing approach, when mixed with the reasoning mannequin, efficiently reproduces OpenAI’s test-time scaling habits. The effectiveness of such minimal coaching knowledge means that the mannequin’s reasoning capabilities are largely current from pretraining on trillions of tokens, with the fine-tuning course of merely activating these latent talents. This aligns with the “Superficial Alignment Speculation” from LIMA analysis, suggesting {that a} comparatively small variety of examples can successfully align a mannequin’s habits with desired outcomes.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.