{kind=link}

Giant language fashions are good at many duties however unhealthy at complicated reasoning, particularly in the case of math issues. Present In-Context Studying (ICL) strategies rely closely on fastidiously chosen examples and human assist, which makes it exhausting to deal with new issues. Conventional strategies additionally use simple reasoning methods that restrict their means to search for totally different options, making them gradual and never nice for numerous conditions. It’s once more vital to confront these challenges to reinforce automated reasoning, adaptability, and correct use of LLMs.
Conventional ICL methods, resembling Chain-of-Thought (CoT) reasoning and 0/few-shot prompting, have proven promise in enhancing reasoning efficiency. CoT permits fashions to consider issues step-by-step, which is nice for fixing structured points. Nevertheless, these strategies have huge issues. Their efficiency depends upon how good the examples are and the way they’re structured, which requires numerous ability to arrange. The fashions can not adapt to issues that deviate from their coaching examples, decreasing the utility in various duties. Furthermore, present approaches depend on sequential reasoning, which restricts the exploration of different problem-solving methods. These limitations have indicated a necessity for modern frameworks that cut back human dependency, improve generalization, and optimize reasoning effectivity.
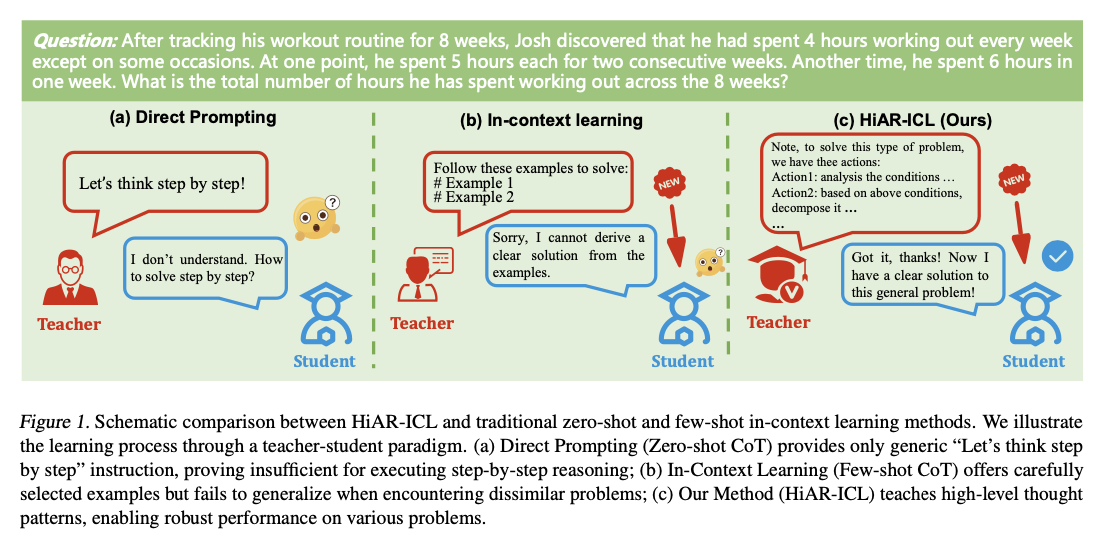
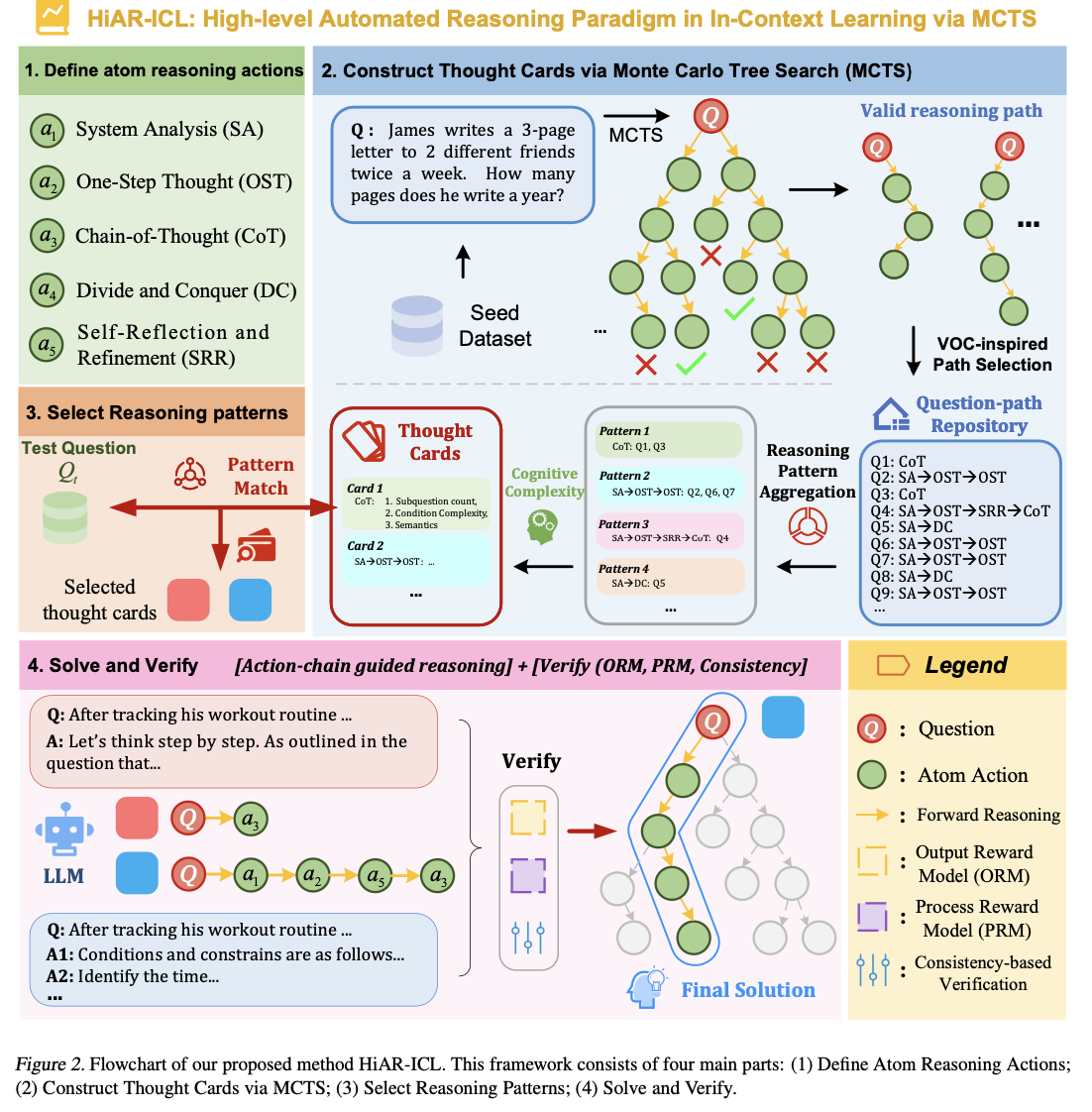
HiAR-ICL (Excessive-level Automated Reasoning in In-Context Studying) addresses these challenges by reimagining “context” as encompassing higher-order reasoning patterns as a substitute of specializing in example-based studying. This paradigm fosters adaptability and robustness in problem-solving by cultivating transferable reasoning capabilities. It aggregates 5 salient thought processes: System Evaluation (SA), One-Step Thought (OST), Chain-of-Thought (CoT), Divide-and-Conquer (DC), and Self-Reflection and Refinement (SRR), for it to operate like human fixing processes. These are the premise on which “thought playing cards,” reusable reasoning templates, come to be constructed utilizing the Monte Carlo Tree Search(MCTS) mechanism. MCTS identifies optimally good reasoning paths from a seed dataset, which then are distilled into summary templates. A cognitive complexity framework evaluates issues alongside dimensions that embrace subquestion rely, situation complexity, and semantic similarity, which dynamically informs the collection of related and exact thought playing cards. This dynamic reasoning course of is additional enhanced by multi-layered validation methods, together with self-consistency and reward-based evaluations, making certain accuracy and reliability.
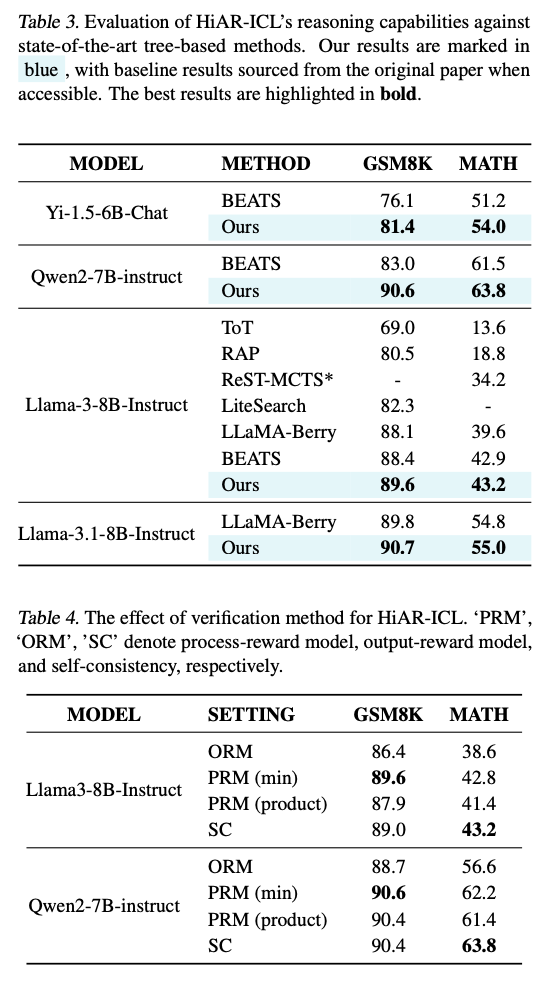
HiAR-ICL demonstrates vital developments in reasoning accuracy and effectivity throughout numerous benchmarks. Its efficiency is greatest on datasets like MATH, GSM8K, and StrategyQA. Accuracy will increase by as a lot as 27% in comparison with conventional ICL strategies. Effectivity can be spectacular with computing time minimize down by as a lot as 27 occasions for simpler duties and as much as 10 occasions for more durable issues. It does effectively with diversified purposes and even small fashions; thus, accuracy improves in lots of checks by greater than 10%. Its functionality of surpassing conventional approaches whereas accommodating a spread of adverse issues guarantees the revolution of this self-discipline.
HiAR-ICL redefines reasoning capabilities in LLMs by transitioning from example-centric paradigms to high-level cognitive frameworks. Monte Carlo Tree Search and the usage of thought playing cards for problem-solving make it a strong device to work adaptively with very minimal want for human assist. It was capable of come up on the prime when its efficiency was examined with exhausting checks, indicating its power in shaping the way forward for automated reasoning, particularly by way of environment friendly dealing with of complicated duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Rework proofs-of-concept into production-ready AI purposes and brokers’ (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.