{kind=link}
 Inference by way of Speculative Decoding")
Massive language fashions (LLMs) have quickly turn out to be a foundational element of as we speak’s client and enterprise functions. Nonetheless, the necessity for a quick era of tokens has remained a persistent problem, usually turning into a bottleneck in rising functions. For instance, the latest development of inference-time scaling makes use of for much longer outputs to carry out search and different complicated algorithms, whereas multi-agent and pipelined LLM techniques goal to reinforce accuracy and reliability, however each usually endure from lengthy response instances as a result of watch for a number of processing levels. Addressing this want for accelerated token era is essential for the continued development and widespread adoption of LLM-powered functions.
Present model-based speculative decoding strategies have limitations that hinder their skill to successfully tackle the problem of accelerating token era in LLMs. First, these strategies rely closely on the dimensions and high quality of the draft mannequin, which can not at all times be accessible, requiring expensive coaching or fine-tuning to create an appropriate mannequin. Second, the combination of draft fashions and LLMs on GPUs can result in problems and inefficiencies, reminiscent of conflicts between the draft mannequin’s reminiscence utilization and the LLM’s key-value cache. To handle these points, latest work has explored incorporating further decoding heads instantly throughout the LLM to carry out speculative decoding. Nonetheless, these approaches nonetheless face related challenges, as the extra heads require fine-tuning for every LLM and eat vital GPU reminiscence. Overcoming these limitations is essential for creating extra strong and environment friendly strategies to speed up LLM inference.
Researchers from Snowflake AI Analysis and Carnegie Mellon College introduce SuffixDecoding, a strong model-free method that avoids the necessity for draft fashions or further decoding heads. As an alternative of counting on separate fashions, SuffixDecoding uitlizes environment friendly suffix tree indices constructed upon earlier output generations and the present ongoing inference request. The method begins by tokenizing every prompt-response pair utilizing the LLM’s vocabulary, extracting all attainable suffixes (subsequences from any place to the tip) to assemble the suffix tree construction. Every node within the tree represents a token, and the trail from the basis to any node corresponds to a subsequence that appeared within the coaching information. This model-free method eliminates the problems and GPU overhead related to integrating draft fashions or further decoding heads, presenting a extra environment friendly various for accelerating LLM inference.
For every new inference request, SuffixDecoding constructs a separate per-request suffix tree from the present immediate tokens. This design is essential for duties the place the LLM output is anticipated to reference or reuse content material from the enter immediate, reminiscent of doc summarization, question-answering, multi-turn chat conversations, and code modifying. The suffix tree maintains frequency counts at every node to trace how usually totally different token sequences happen, enabling environment friendly sample matching. Given any sequence of latest tokens from the present era, SuffixDecoding can rapidly traverse the tree to seek out all attainable continuations that appeared within the immediate or earlier outputs. At every inference step, SuffixDecoding selects one of the best subtree(s) of continuation tokens based mostly on frequency statistics and empirical chance. These speculated tokens are then handed to the LLM for verification, which is carried out in a single ahead go due to a tree consideration operator with a topology-aware causal masks.

Much like prior work like LLMA and Immediate Lookup Decoding, SuffixDecoding is a model-free method that sources candidate sequences from a reference corpus. Nonetheless, in contrast to earlier strategies that solely thought-about small reference texts reminiscent of a handful of snippets or simply the present immediate, SuffixDecoding is designed to make the most of a a lot larger-scale corpus, consisting of lots of and even 1000’s of beforehand generated outputs.
By working on this bigger reference corpus, SuffixDecoding can make the most of frequency statistics in a extra principled trend to pick probably candidate sequences. To allow quick manufacturing of those candidate sequences, SuffixDecoding builds a suffix tree over its reference corpus. The basis node of the tree represents the start of a suffix from any doc within the corpus, the place a doc is an output of a earlier inference or the immediate and output of the present ongoing inference. The trail from the basis to every node represents a subsequence that seems within the reference corpus, and every youngster node represents a attainable token continuation.
SuffixDecoding makes use of this suffix tree construction to carry out environment friendly sample matching. Given the immediate plus generated tokens of the present inference, it identifies a sample sequence and walks the suffix tree to seek out all attainable continuations that appeared within the reference corpus. Whereas this may produce a big set of candidate sequences, SuffixDecoding employs a grasping growth and scoring process to construct a smaller, extra probably hypothesis tree, which is then used within the remaining tree-based speculative decoding step.
The tip-to-end experimental outcomes show the strengths of the SuffixDecoding method. On the AgenticSQL dataset, which represents a fancy, multi-stage LLM pipeline, SuffixDecoding achieves as much as 2.9x larger output throughput and as much as 3x decrease time-per-token (TPOT) latency in comparison with the SpecInfer baseline. For extra open-ended duties like chat and code era, SuffixDecoding nonetheless delivers robust efficiency, with as much as 1.4x larger throughput and 1.1x decrease TPOT latency than SpecInfer.
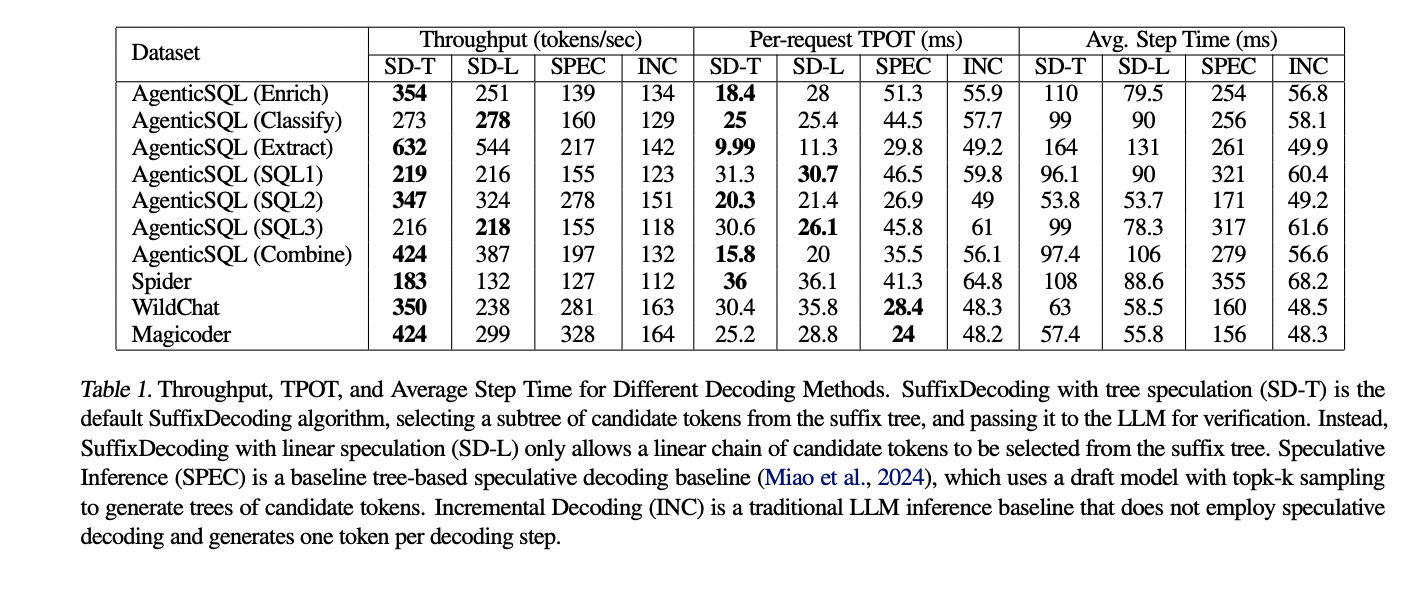
The analysis additionally examines the effectiveness of SuffixDecoding’s speculative decoding capabilities. SuffixDecoding can obtain a considerably larger common variety of accepted speculated tokens per verification step in comparison with the draft-model-based SpecInfer method. This means SuffixDecoding’s model-free suffix tree construction permits extra correct and dependable speculative token era, maximizing the potential speedup from speculative decoding with out the overhead of sustaining a separate draft mannequin.


This work presents SuffixDecoding, a model-free method to accelerating LLM inference by using suffix bushes constructed from earlier outputs. SuffixDecoding achieves aggressive speedups towards present model-based speculative decoding strategies throughout various workloads whereas being significantly well-suited for complicated, multi-stage LLM pipelines. By scaling the reference corpus fairly than counting on draft fashions, SuffixDecoding demonstrates a strong course for bettering speculative decoding effectivity and unlocking the complete potential of enormous language fashions in real-world functions.
Try the Particulars right here. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Providers and Actual Property Transactions
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.