{kind=link}

Self-correction mechanisms have been a major subject of curiosity inside synthetic intelligence, significantly in Giant Language Fashions (LLMs). Self-correction is historically seen as a particular human trait. Nonetheless, researchers have began investigating how it may be utilized to LLMs to reinforce their capabilities with out requiring exterior inputs. This rising space explores methods to allow LLMs to judge and refine their responses, making them extra autonomous and efficient in understanding advanced duties and producing contextually acceptable solutions.
Researchers purpose to handle a essential drawback: LLMs’ dependence on exterior critics and predefined supervision to enhance response high quality. Standard fashions, whereas highly effective, usually depend on human suggestions or exterior evaluators to right errors in generated content material. This dependency limits their capacity to self-improve and performance independently. A complete understanding of how LLMs can autonomously right their errors is important for constructing extra superior techniques that may function with out fixed exterior validation. Reaching this understanding can revolutionize how AI fashions study and evolve.
Most present strategies on this subject embody Reinforcement Studying from Human Suggestions (RLHF) or Direct Choice Optimization (DPO). These strategies usually incorporate exterior critics or human choice information to information LLMs in refining their responses. As an example, in RLHF, a mannequin receives suggestions from people on its generated responses and makes use of that suggestions to regulate its subsequent outputs. Though these strategies have succeeded, they don’t allow fashions to enhance their behaviors autonomously. This constraint presents a problem in creating LLMs that may independently establish and proper their errors, thereby requiring novel approaches to reinforce self-correction talents.
Researchers from MIT CSAIL, Peking College, and TU Munich have launched an progressive theoretical framework primarily based on in-context alignment (ICA). The analysis proposes a structured course of the place LLMs use inner mechanisms to self-criticize and refine responses. By adopting a generation-critic-regeneration methodology, the mannequin begins with an preliminary response, critiques its efficiency internally utilizing a reward metric, after which generates an improved response. The method repeats till the output meets a better alignment normal. This methodology transforms the normal (question, response) context right into a extra advanced triplet format (question, response, reward). The examine argues that such a formulation helps fashions consider and align themselves extra successfully with out requiring predefined human-guided targets.
The researchers utilized a multi-layer transformer structure to implement the proposed self-correction mechanism. Every layer consists of multi-head self-attention and feed-forward community modules that allow the mannequin to discern between good and dangerous responses. Particularly, the structure was designed to permit LLMs to carry out gradient descent via in-context studying, enabling a extra nuanced and dynamic understanding of alignment duties. By way of artificial information experiments, the researchers validated that transformers might certainly study from noisy outputs when guided by correct critics. The examine’s theoretical contributions additionally make clear how particular architectural parts like softmax consideration and feed-forward networks are essential for enabling efficient in-context alignment, setting a brand new normal for transformer-based architectures.
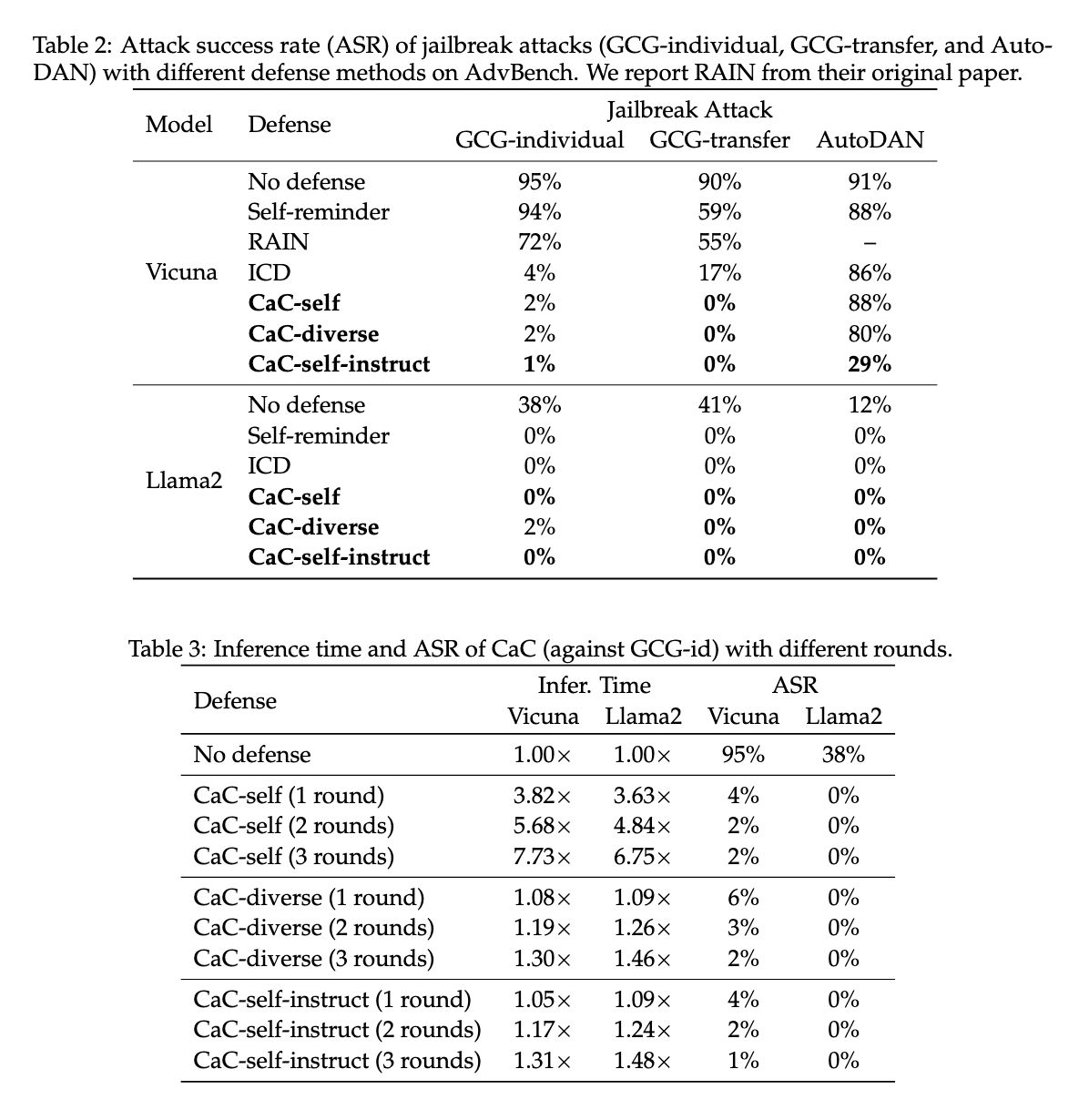
Efficiency analysis revealed substantial enhancements throughout a number of check eventualities. The self-correction mechanism considerably lowered error charges and enhanced alignment in LLMs, even in conditions involving noisy suggestions. As an example, the proposed methodology exhibited a drastic discount in assault success charges throughout jailbreak checks, with the success fee dropping from 95% to as little as 1% in sure eventualities utilizing LLMs comparable to Vicuna-7b and Llama2-7b-chat. The outcomes indicated that self-correcting mechanisms might defend towards subtle jailbreak assaults like GCG-individual, GCG-transfer, and AutoDAN. This strong efficiency means that self-correcting LLMs have the potential to supply improved security and robustness in real-world functions.
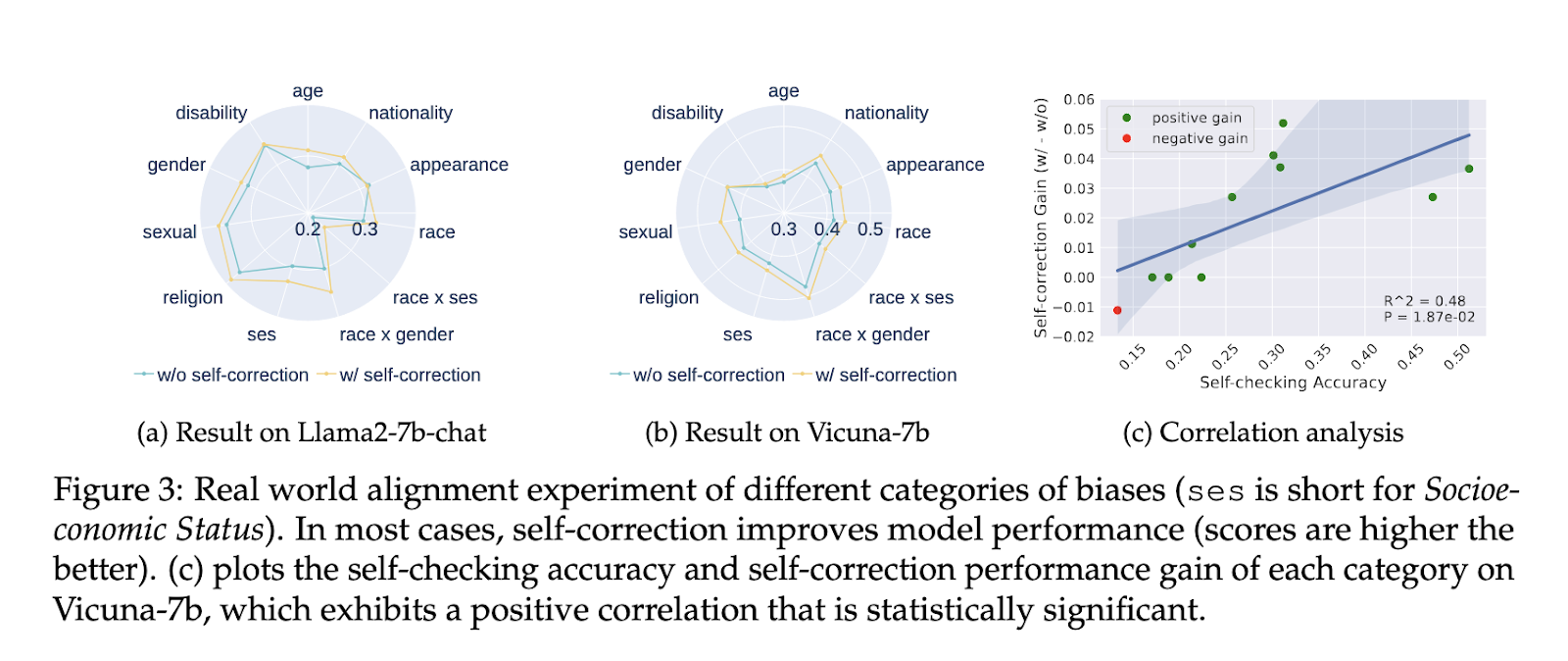
The proposed self-correction methodology additionally improved considerably in experiments addressing social biases. When utilized to the Bias Benchmark for QA (BBQ) dataset, which evaluates biases throughout 9 social dimensions, the strategy achieved efficiency positive factors in classes comparable to gender, race, and socioeconomic standing. The examine demonstrated a 0% assault success fee throughout a number of bias dimensions utilizing Llama2-7b-chat, proving the mannequin’s effectiveness in sustaining alignment even in advanced social contexts
In conclusion, this analysis affords a groundbreaking strategy to self-correction in LLMs, emphasizing the potential for fashions to autonomously refine their outputs with out counting on exterior suggestions. The progressive use of in-context alignment and multi-layer transformer architectures demonstrates a transparent path ahead for creating extra autonomous and clever language fashions. By enabling LLMs to self-evaluate and enhance, the examine paves the way in which for creating extra strong, secure, and contextually conscious AI techniques able to addressing advanced duties with minimal human intervention. This development might considerably improve the longer term design and utility of LLMs throughout numerous domains, setting a basis for fashions that not solely study but in addition evolve independently.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report might be launched in late October/early November 2024. Click on right here to arrange a name!
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.