{kind=link}

Information Graph (KG) synthesis is gaining traction in synthetic intelligence analysis as a result of it could actually assemble structured information representations from expansive, unstructured textual content knowledge. These structured graphs have pivotal purposes in areas requiring data retrieval and reasoning, akin to query answering, advanced knowledge summarization, and retrieval-augmented era (RAG). KGs successfully hyperlink and set up data, enabling fashions to course of and reply intricate queries extra precisely. Regardless of these benefits, creating high-quality KGs from giant datasets stays difficult as a result of want for each protection and effectivity, which change into more and more troublesome to take care of with conventional strategies when dealing with large quantities of information.
One of many central issues in KG synthesis is decreasing the inefficiency in producing complete graphs, particularly for large-scale corpora that require advanced information representations. Current KG extraction methods sometimes make use of giant language fashions (LLMs) able to superior processing however can be computationally prohibitive. These strategies typically use zero-shot or few-shot prompt-based approaches to construction KGs, usually involving in depth API calls and excessive prices. These approaches should be revised in dealing with prolonged paperwork comprehensively, resulting in points akin to incomplete knowledge illustration and important data loss. This creates a spot between the rising demand for efficient knowledge synthesis strategies and the accessible KG development instruments, which want extra specialization for ontology-free KG analysis and benchmarking.
In present follow, conventional strategies of KG development rely closely on LLM prompting to derive information triplets. This single-step, in-context studying strategy presents a number of limitations. For instance, the computational demand will increase because the corpus grows, and every further API name to course of knowledge will increase prices. Additionally, there must be a standardized dataset or analysis metric for assessing document-level, ontology-free KGs, creating additional challenges for researchers aiming to benchmark the effectiveness of their fashions. With large-scale purposes in thoughts, there’s a compelling want for fashions that may handle detailed doc processing effectively with out compromising knowledge high quality.
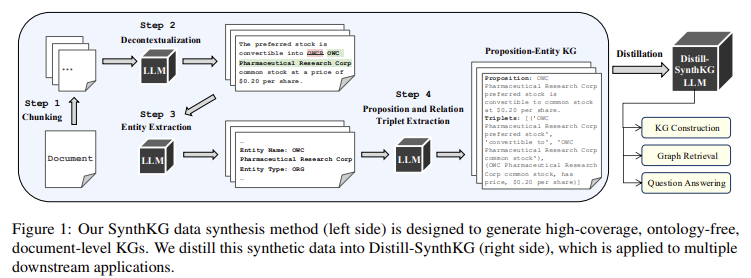
The Salesforce and Intel Labs researchers launched SynthKG, a multi-step KG development workflow that enhances protection and effectivity. SynthKG breaks down doc processing into manageable phases, guaranteeing that data stays intact by chunking paperwork after which processing every section to determine entities, relations, and related propositions. A distilled mannequin, Distill-SynthKG, was additional developed by fine-tuning a smaller LLM utilizing KGs generated from SynthKG. This distillation reduces the multi-step workflow right into a single-step course of, considerably decreasing computational necessities. With Distill-SynthKG, the necessity for repeated LLM prompts is minimized, enabling high-quality KG era with a fraction of the assets required by standard approaches.
The SynthKG workflow includes doc segmentation, which splits every enter doc into impartial, semantically full chunks. Throughout this chunking course of, entity disambiguation is utilized to take care of a constant reference for every entity throughout segments. For instance, if a person is launched by full title in a single chunk, all future mentions are up to date to make sure contextual accuracy. This strategy improves the coherence of every section whereas stopping the lack of necessary relationships between entities. The subsequent stage includes relation extraction, the place entities and their varieties are recognized and linked based mostly on predefined propositions. Every KG section is additional enriched with a quadruplet format, offering an intermediate, indexable unit for higher retrieval accuracy. By structuring every chunk independently, SynthKG avoids redundancy and maintains high-quality knowledge integrity all through the KG development course of.
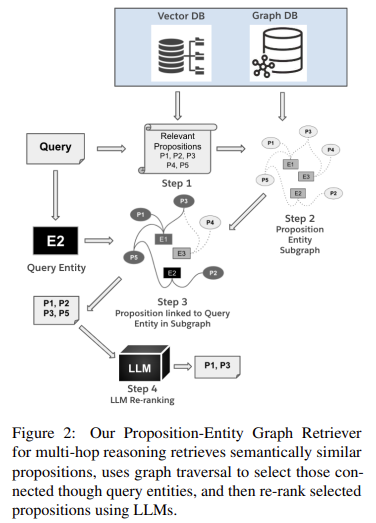
Distill-SynthKG has proven substantial enhancements over baseline fashions in experimental settings. As an illustration, the mannequin generated over 46.9% protection on MuSiQue and 58.2% on 2WikiMultiHopQA by way of triplet protection, outperforming bigger fashions by a margin of as much as 6.26% in absolute phrases throughout varied take a look at datasets. Concerning retrieval and question-answering duties, Distill-SynthKG persistently surpassed the efficiency of even fashions eight occasions bigger by decreasing computational prices whereas enhancing retrieval accuracy. This effectivity is clear within the Graph+LLM retriever, the place the KG mannequin demonstrated a 15.2% absolute enchancment in retrieval duties, notably when answering multi-hop reasoning questions. These outcomes verify the efficacy of a structured multi-step strategy in maximizing KG protection and enhancing accuracy with out counting on outsized LLMs.
The experimental outcomes spotlight the success of Distill-SynthKG in delivering high-performance KG synthesis with decrease computational demand. By coaching smaller fashions on high-quality document-KG pairs from SynthKG, researchers achieved improved semantic accuracy, leading to triplet densities constant throughout paperwork of assorted lengths. Additionally, the SynthKG mannequin produced KGs with better triplet density, remaining regular throughout paperwork as much as 1200 phrases, demonstrating the workflow’s scalability. Evaluated throughout benchmarks akin to MuSiQue and HotpotQA, the mannequin’s enhancements have been validated utilizing new KG protection metrics, which included proxy triplet protection and semantic matching scores. These metrics additional confirmed the mannequin’s suitability for large-scale, ontology-free KG duties, because it efficiently synthesized detailed KGs that supported high-quality retrieval and multi-hop question-answering duties.
Key Takeaways from the analysis:
- Effectivity: Distill-SynthKG reduces the necessity for repeated LLM calls by consolidating KG development right into a single-step mannequin, reducing computational prices.
- Improved Protection: Achieved 46.9% triplet protection on MuSiQue and 58.2% on 2WikiMultiHopQA, outperforming bigger fashions by 6.26% on common throughout datasets.
- Enhanced Retrieval Accuracy: A 15.2% enchancment in multi-hop question-answering retrieval accuracy with Graph+LLM retrieval.
- Scalability: Maintained constant triplet density throughout paperwork of various lengths, demonstrating suitability for giant datasets.
- Broader Purposes: The mannequin helps environment friendly KG era for varied domains, from healthcare to finance, by precisely accommodating ontology-free KGs.

In conclusion, the analysis findings emphasize the impression of an optimized KG synthesis course of that prioritizes protection, accuracy, and computational effectivity. Distill-SynthKG not solely units a brand new benchmark for KG era but in addition presents a scalable resolution that accommodates varied domains, paving the best way for extra environment friendly retrieval and question-answering frameworks. This strategy might have broad implications for advancing AI’s capacity to generate and construction large-scale information representations, in the end enhancing the standard of knowledge-based purposes throughout sectors.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.