{kind=link}
: A Novel AI Method for Enhancing LLM Reasoning with Structured Critique Studying")
Conventional approaches to coaching language fashions closely depend on supervised fine-tuning, the place fashions study by imitating appropriate responses. Whereas efficient for primary duties, this technique limits a mannequin’s means to develop deep reasoning abilities. As synthetic intelligence purposes proceed to evolve, there’s a rising demand for fashions that may generate responses and critically consider their very own outputs to make sure accuracy and logical consistency.
A severe limitation of conventional coaching strategies is that they’re primarily based on imitation of responses and prohibit fashions from essential evaluation of responses. Consequently, imitation-based methods fail to current correct logical depth when coping with intricate reasoning issues, and generated outputs usually resemble correct-sounding responses. Extra importantly, will increase in dataset sizes don’t mechanically result in improved generated response high quality, negatively impacting the coaching of enormous fashions. These challenges draw consideration to a necessity for various strategies that higher enhance reasoning quite than enhance computations.
Current options try to mitigate these points utilizing reinforcement studying and instruction tuning. Reinforcement studying with human suggestions has proven promising outcomes however requires large-scale computational assets. One other strategy entails self-critique, the place fashions assess their outputs for errors, however this usually lacks consistency. Regardless of these developments, most coaching methods nonetheless give attention to optimizing efficiency by means of sheer knowledge quantity quite than enhancing elementary reasoning capabilities, which limits their effectiveness in advanced problem-solving eventualities.
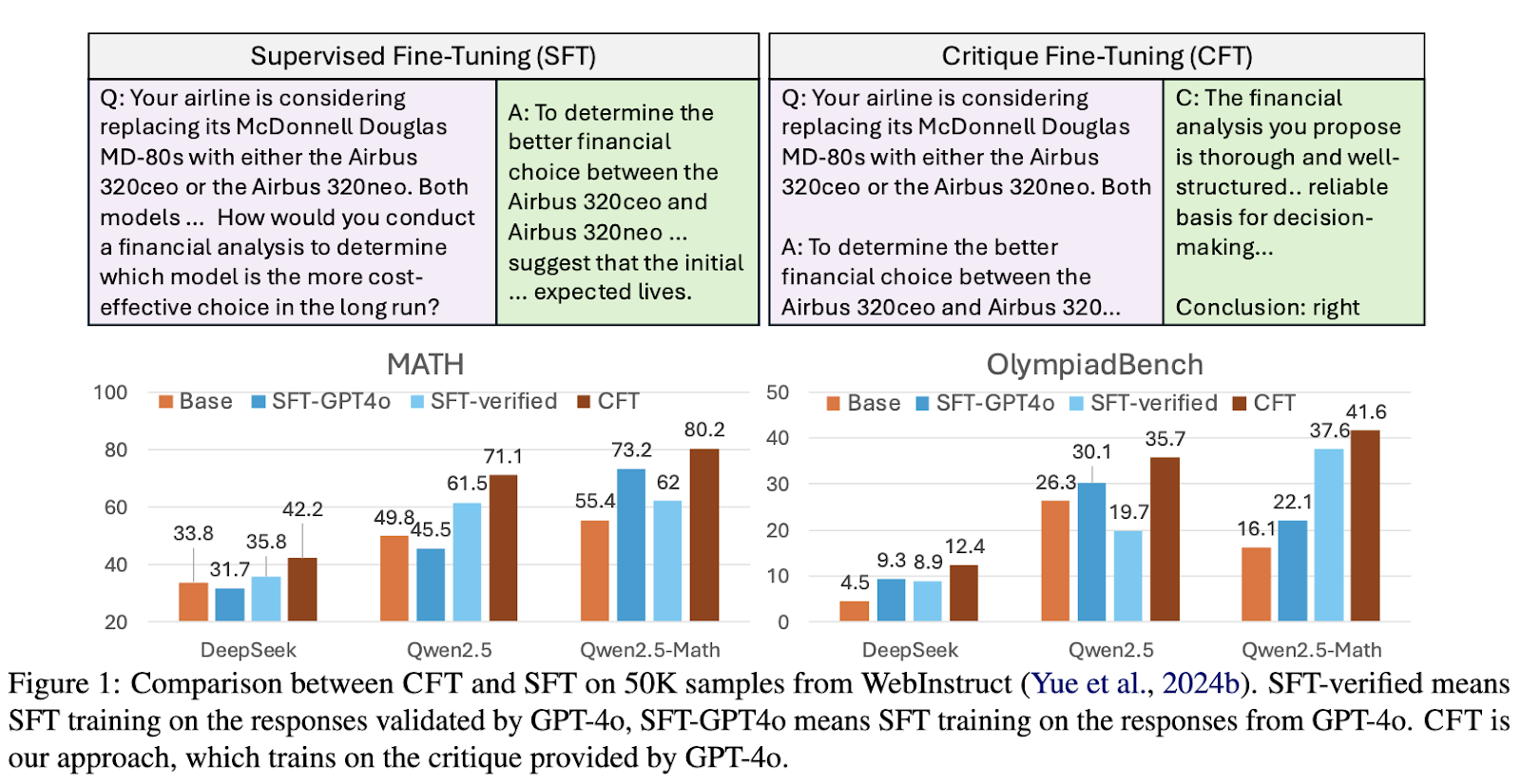
A analysis crew from the College of Waterloo, Carnegie Mellon College, and the Vector Institute proposed Critique Effective-Tuning (CFT) as an alternative choice to standard supervised fine-tuning. This strategy shifts the main target from imitation-based studying to critique-based studying, the place fashions are educated to evaluate and refine responses quite than replicate them. To attain this, researchers constructed a dataset of fifty,000 critique samples utilizing GPT-4o, enabling fashions to determine response flaws and recommend enhancements. This technique is especially efficient for domains requiring structured reasoning, resembling mathematical problem-solving.
The CFT methodology revolves round coaching fashions utilizing structured critique datasets as an alternative of standard question-response pairs. Throughout coaching, fashions are introduced with a question and an preliminary response, adopted by a critique that evaluates the response’s accuracy and logical coherence. By optimizing the mannequin to generate critiques, researchers encourage a deeper analytical course of that enhances reasoning capabilities. In contrast to conventional fine-tuning, the place fashions are rewarded for merely reproducing appropriate solutions, CFT prioritizes figuring out errors and suggesting enhancements, resulting in extra dependable and explainable outputs.
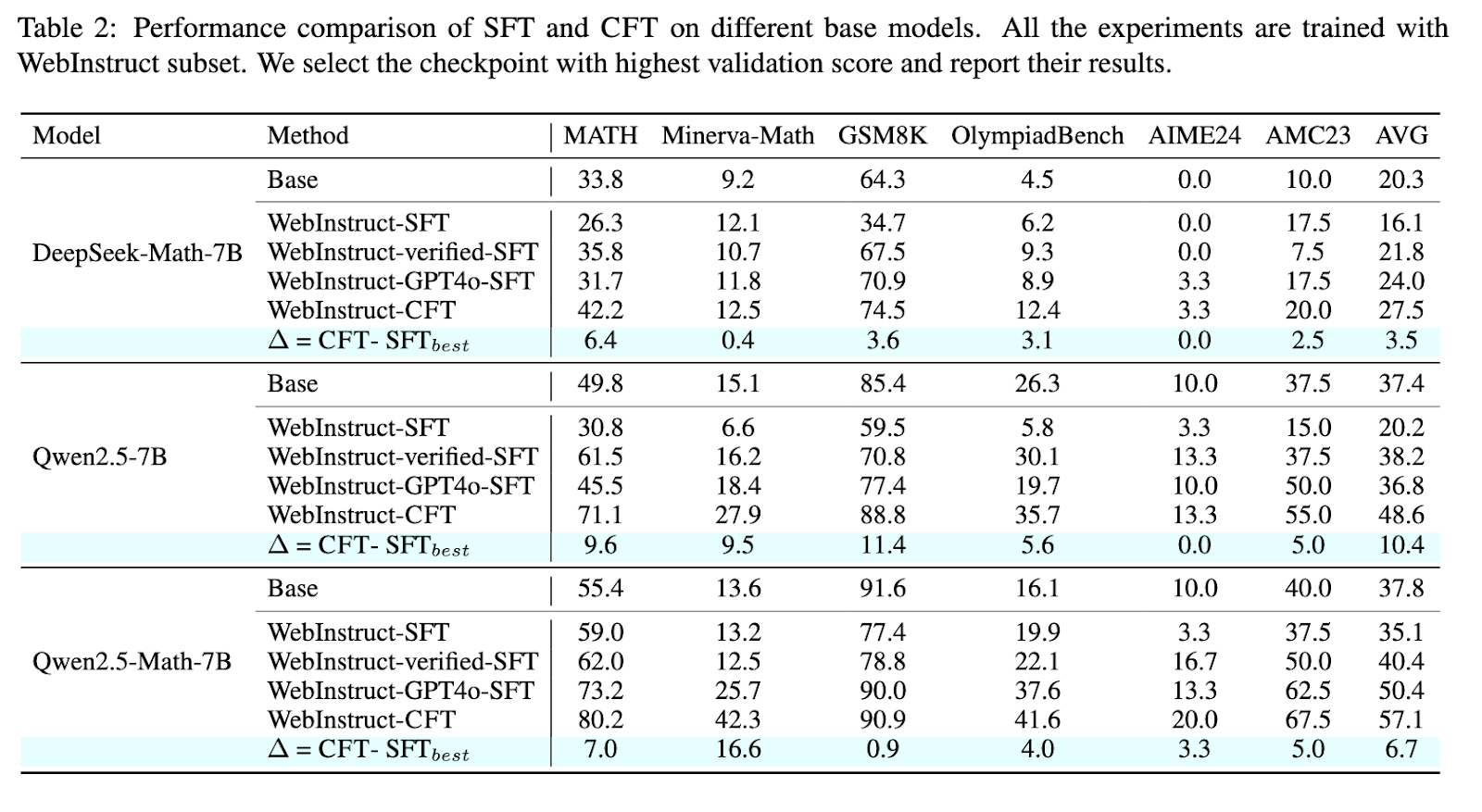
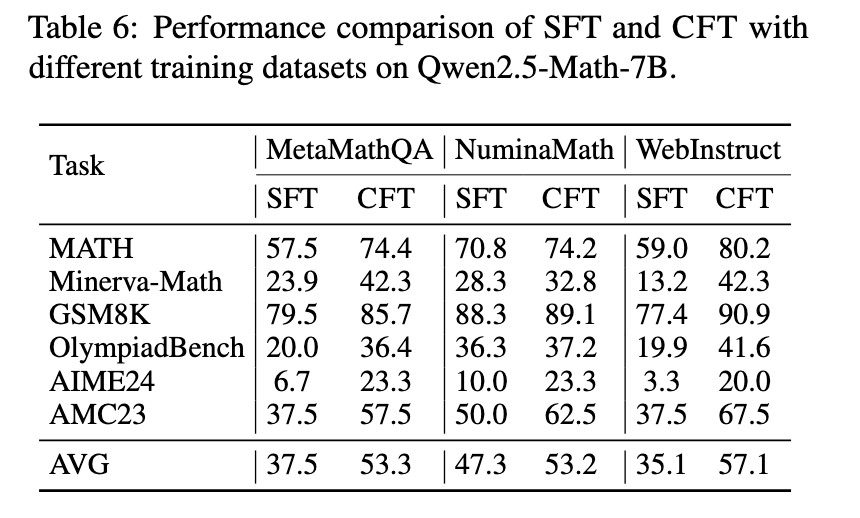
Experimental outcomes display that CFT-trained fashions constantly outperform these educated utilizing standard strategies. The researchers evaluated their strategy throughout a number of mathematical reasoning benchmarks, together with MATH, Minerva-Math, and OlympiadBench. Fashions educated utilizing CFT confirmed a big 4–10% efficiency enchancment over their supervised fine-tuned counterparts. Particularly, Qwen2.5-Math-CFT, which was educated with as few as 50,000 examples, is similar to and typically even superior to fashions competing towards it with over 2 million samples in coaching. As well as, the framework yielded a 7.0% enchancment in accuracy on the MATH benchmark and 16.6% on Minerva-Math in comparison with normal fine-tuning methods. This vital enchancment exhibits the effectivity of critique-based studying, which regularly promotes good outcomes with considerably fewer coaching samples and computational assets.
The findings from this examine emphasize some great benefits of critique-based studying in language mannequin coaching. By shifting from response imitation to critique technology, researchers have launched a way that enhances mannequin accuracy and fosters deeper reasoning abilities. The flexibility to critically assess and refine responses quite than generate them permits fashions to deal with advanced reasoning duties extra successfully. This analysis presents a promising path for enhancing synthetic intelligence coaching methodologies whereas decreasing computational prices. Future work might refine the strategy by integrating further critique mechanisms to boost mannequin reliability and generalization throughout various problem-solving domains.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.