{kind=link}

Giant Language Fashions (LLMs) equivalent to GPT, Gemini, and Claude make the most of huge coaching datasets and complicated architectures to generate high-quality responses. Nonetheless, optimizing their inference-time computation stays difficult, as growing mannequin dimension results in greater computational prices. Researchers proceed to discover methods that maximize effectivity whereas sustaining or bettering mannequin efficiency.
One broadly adopted method for bettering LLM efficiency is ensembling, the place a number of fashions are mixed to generate a last output. Combination-of-Brokers (MoA) is a well-liked ensembling technique that aggregates responses from completely different LLMs to synthesize a high-quality response. Nonetheless, this technique introduces a basic trade-off between variety and high quality. Whereas combining various fashions could supply benefits, it will possibly additionally end in suboptimal efficiency as a result of inclusion of lower-quality responses. Researchers purpose to stability these components to make sure optimum efficiency with out compromising response high quality.
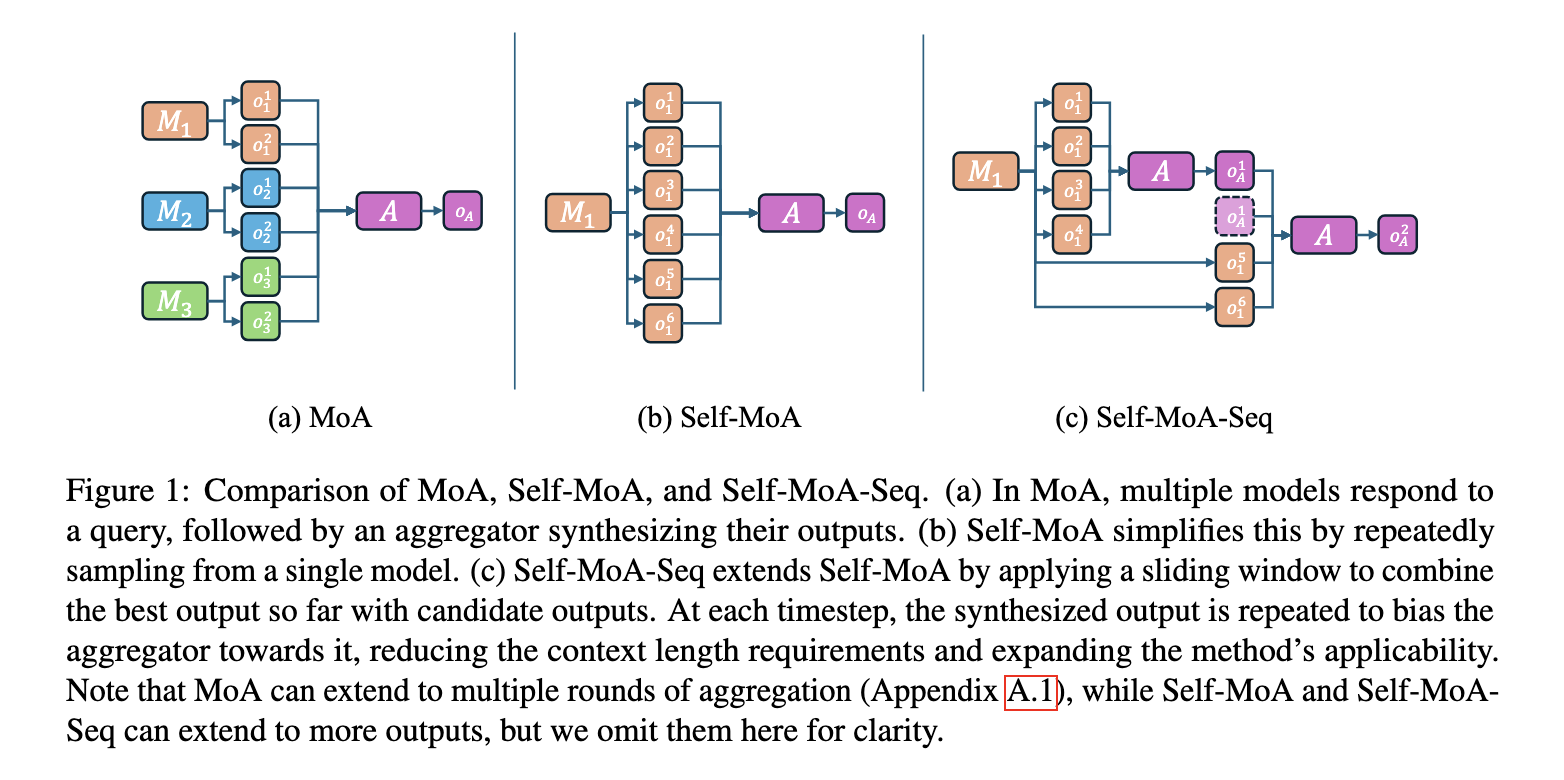
Conventional MoA frameworks function by first querying a number of proposer fashions to generate responses. An aggregator mannequin then synthesizes these responses right into a last reply. The effectiveness of this technique depends on the belief that variety amongst proposer fashions results in higher efficiency. Nonetheless, this assumption doesn’t account for potential high quality degradation attributable to weaker fashions within the combine. Prior analysis has primarily targeted on growing cross-model variety relatively than optimizing proposer fashions’ high quality, resulting in efficiency inconsistencies.
A analysis workforce from Princeton College launched Self-MoA, a novel ensembling technique that eliminates the necessity for a number of fashions by aggregating numerous outputs from a single high-performing mannequin. In contrast to conventional MoA, which mixes completely different LLMs, Self-MoA leverages in-model variety by repeatedly sampling from the identical mannequin. This method ensures that solely high-quality responses contribute to the ultimate output, addressing the quality-diversity trade-off noticed in Combined-MoA configurations.
Self-MoA operates by producing a number of responses from a single top-performing mannequin and synthesizing them right into a last output. Doing so eliminates the necessity to incorporate lower-quality fashions, thereby bettering general response high quality. To additional improve scalability, researchers launched Self-MoA-Seq, a sequential variation that processes a number of responses iteratively. This permits for environment friendly aggregation of outputs even in eventualities the place computational sources are constrained. Self-MoA-Seq processes outputs utilizing a sliding window method, making certain that LLMs with shorter context lengths can nonetheless profit from ensembling with out compromising efficiency.
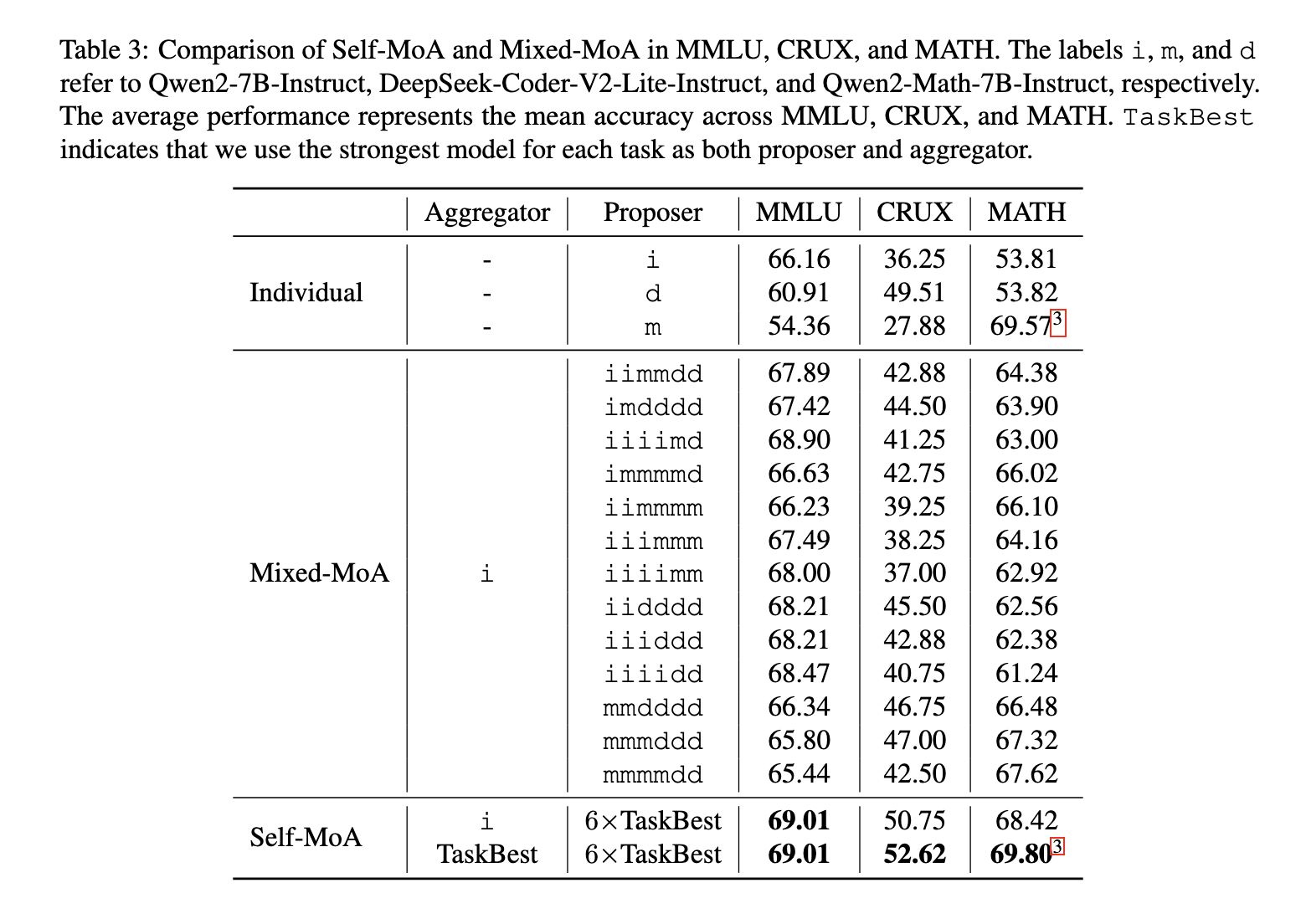
Experiments demonstrated that Self-MoA considerably outperforms Combined-MoA throughout numerous benchmarks. On the AlpacaEval 2.0 benchmark, Self-MoA achieved a 6.6% enchancment over conventional MoA. When examined throughout a number of datasets, together with MMLU, CRUX, and MATH, Self-MoA confirmed a median enchancment of three.8% over Combined-MoA approaches. When utilized to one of many top-ranking fashions in AlpacaEval 2.0, Self-MoA set a brand new state-of-the-art efficiency document, additional validating its effectiveness. Additional, Self-MoA-Seq proved to be as efficient as aggregating all outputs concurrently whereas addressing the constraints imposed by mannequin context size constraints.
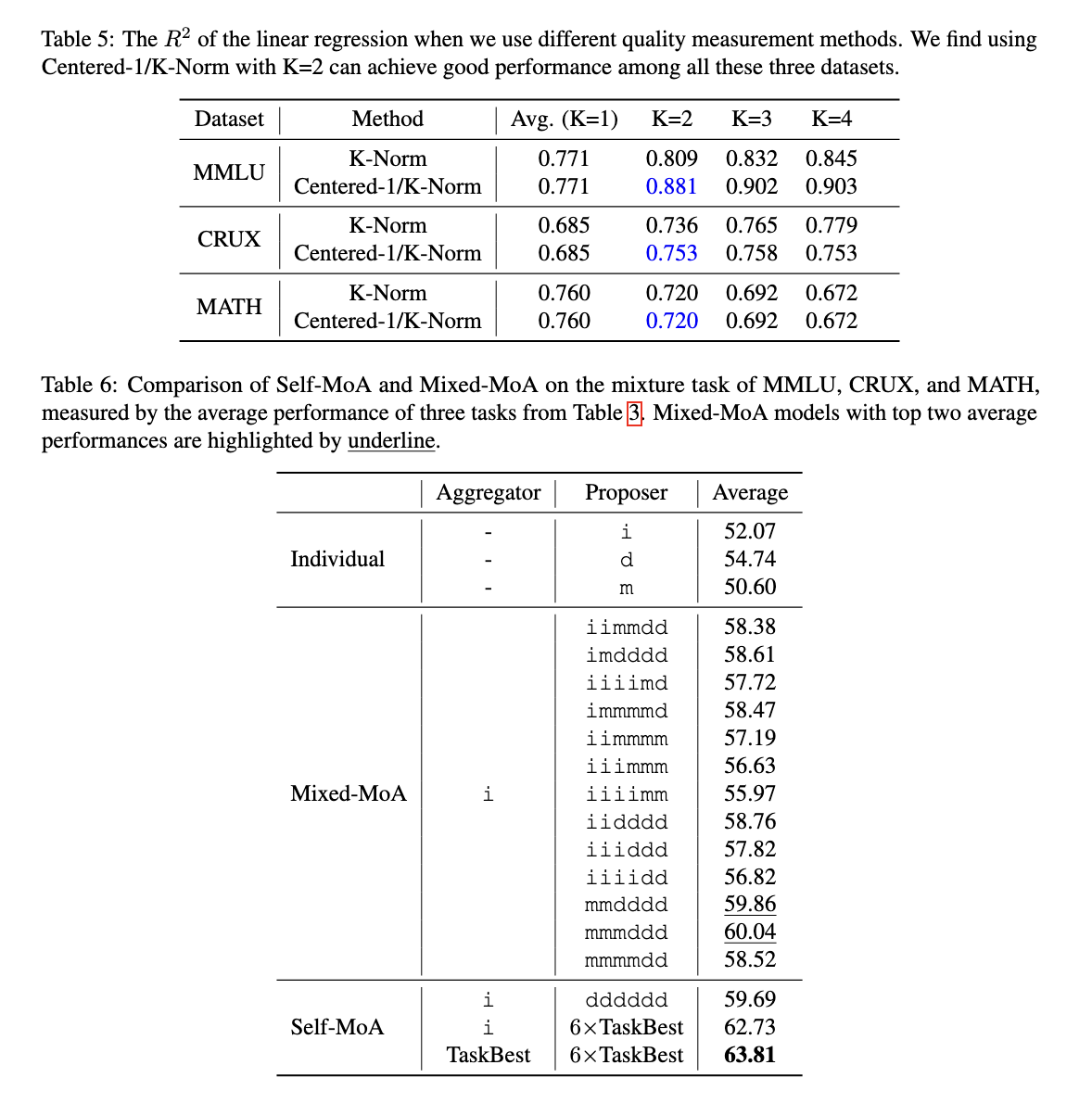
The analysis findings spotlight an important perception into MoA configurations—efficiency is very delicate to proposer high quality. The outcomes verify that incorporating various fashions doesn’t at all times result in superior efficiency. As an alternative, ensembling responses from a single high-quality mannequin yields higher outcomes. Researchers carried out over 200 experiments to research the trade-off between high quality and variety, concluding that Self-MoA persistently outperforms Combined-MoA when the best-performing mannequin is used solely because the proposer.
This examine challenges the prevailing assumption that mixing completely different LLMs results in higher outcomes. By demonstrating the prevalence of Self-MoA, it presents a brand new perspective on optimizing LLM inference-time computation. The findings point out that specializing in high-quality particular person fashions relatively than growing variety can enhance general efficiency. As LLM analysis continues to evolve, Self-MoA offers a promising different to conventional ensembling strategies, providing an environment friendly and scalable method to enhancing mannequin output high quality.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 75k+ ML SubReddit.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.