
Giant Language Fashions (LLMs) face vital scalability limitations in bettering their reasoning capabilities by means of data-driven imitation, as higher efficiency calls for exponentially extra high-quality coaching examples. Exploration-based strategies, notably reinforcement studying (RL), supply a promising different to beat these limitations. The transformation from data-driven to exploration-based approaches presents two key challenges: growing environment friendly strategies to generate exact reward alerts and designing efficient RL algorithms that maximize the utility of those alerts. This shift represents an important step towards enhancing LLM reasoning capabilities.
A group of researchers introduces PRIME (Course of Reinforcement by means of IMplicit Rewards), a novel strategy to boost language mannequin reasoning by means of on-line RL with course of rewards. The system employs implicit course of reward modeling (PRM), which features with out requiring course of labels and operates as an final result reward mannequin. This strategy allows the event of Eurus-2-7B-PRIME, a robust reasoning mannequin that demonstrates vital enhancements by means of each on-line RL coaching and inference-time scaling. The innovation of implicit PRM lies in its twin functionality to boost efficiency and facilitate efficient RL coaching.
The analysis group chosen Qwen2.5-Math-7B-Base as their basis mannequin and evaluated efficiency utilizing high-level arithmetic and programming benchmarks. The preliminary section entails supervised fine-tuning (SFT) utilizing an action-centric chain-of-thought framework the place fashions select from seven predefined actions. The group constructed a 230K dataset from varied open-source supplies, intentionally excluding high-quality datasets with ground-truth solutions to order them for RL. Regardless of these efforts, the SFT mannequin’s efficiency fell wanting Qwen2.5-Math-7B-Instruct throughout arithmetic benchmarks.
The analysis makes use of a complete strategy to dataset curation for RL, combining 457K math issues from NuminaMath-CoT and 27K coding issues from varied sources, together with APPS, CodeContests, TACO, and Codeforces. The group implements an progressive on-line immediate filtering technique that dynamically selects prompts primarily based on issue ranges. By sampling a number of trajectories and sustaining prompts with accuracy scores between 0.2 and 0.8, they successfully balanced the coaching knowledge distribution, eliminating each overly easy and excessively difficult issues. Right here is the circulate of the algorithm for the proposed technique PRIME:

{kind=link}
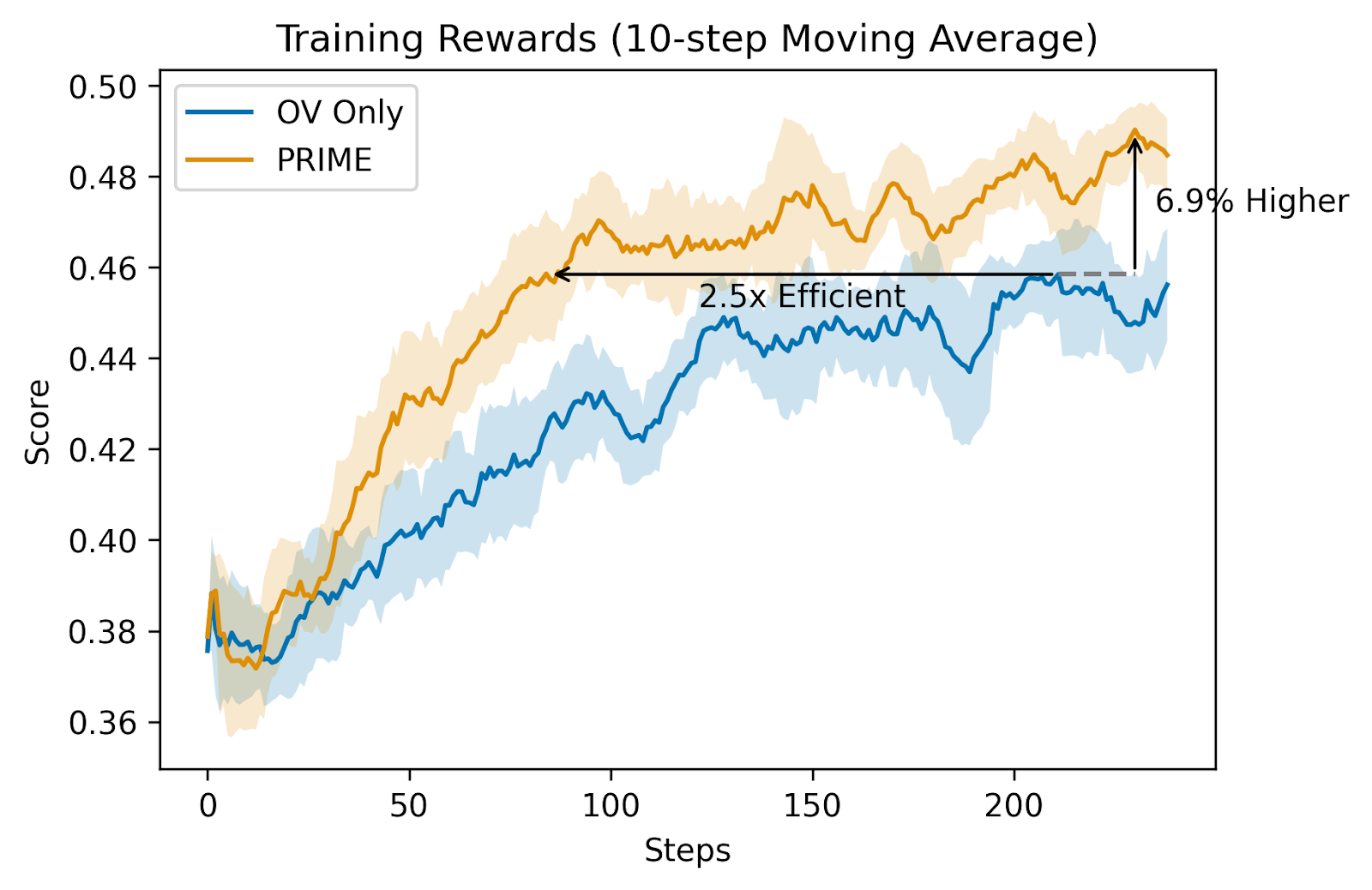
PRIME’s implementation follows a scientific course of the place the coverage mannequin and PRM initialize from the SFT mannequin. The algorithm operates by means of sequential steps of producing rollouts, scoring them, and updating each fashions utilizing mixed final result and course of rewards. With PRIME, ranging from Qwen2.5-Math-7B-Base, the educated mannequin Eurus-2-7B-PRIME achieves 26.7% move@1, surpassing GPT-4o and Qwen2.5-Math-7B-Instruct. That is achieved utilizing only one/10 knowledge of Qwen Math (230K SFT + 150K RL). Furthermore, PRIME achieves vital enhancements over sparse reward approaches utilizing particular hyperparameters and the outcomes present 2.5 occasions quicker coaching, 6.9% increased last rewards, and notably, Eurus-2-7B-PRIME demonstrated a 16.7% common enchancment throughout benchmarks, with over 20% enhancement in AMC&AIME competitions.
Lastly, the validation course of for PRIME makes use of superior mathematical reasoning fashions (QwQ-32B-Preview and Qwen2.5-Math-72B-Instruct) to guage drawback solvability and answer correctness. Utilizing insights from analyzing pattern issues and artificial unsolvable circumstances, the group developed specialised prompts to boost validation accuracy. Every drawback undergoes 5 complete validation makes an attempt, containing step-by-step LaTeX options, unsolvability checks, reasoning traces, standardized reply formatting, and documentation of answer impediments. This rigorous validation framework ensures the standard and reliability of the question-answer pairs.
Try the Hugging Face Web page, Technical Particulars, and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Information and Analysis Intelligence–Be a part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding knowledge privateness.

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.