{kind=link}

We not too long ago introduced the Common Availability of our serverless compute choices for Notebooks, Jobs, and Pipelines. Serverless compute gives speedy workload startup, computerized infrastructure scaling and seamless model upgrades of the Databricks runtime. We’re dedicated to maintain innovating with our serverless providing and constantly bettering worth/efficiency to your workloads. At the moment we’re excited to make just a few bulletins that can assist enhance your serverless value expertise:
- Effectivity enhancements that lead to a higher than 25% discount in prices for many clients, particularly these with short-duration workloads.
- Enhanced value observability that helps monitor and monitor spending at a person Pocket book, Job, and Pipeline degree.
- Easy controls (out there sooner or later) for Jobs and Pipelines that can will let you point out a desire to optimize workload execution for value over efficiency.
- Continued availability of the 50% introductory low cost on our new serverless compute choices for jobs and pipelines, and 30% for notebooks.
Effectivity Enhancements
Based mostly on insights gained from operating buyer workloads, we have applied effectivity enhancements that can allow most clients to realize a 25% or higher discount of their serverless compute spend. These enhancements primarily scale back the price of quick workloads. These adjustments will likely be rolled out routinely over the approaching weeks, guaranteeing that your Notebooks, Jobs, and Pipelines profit from these updates with no need to take any actions.
Enhanced value observability
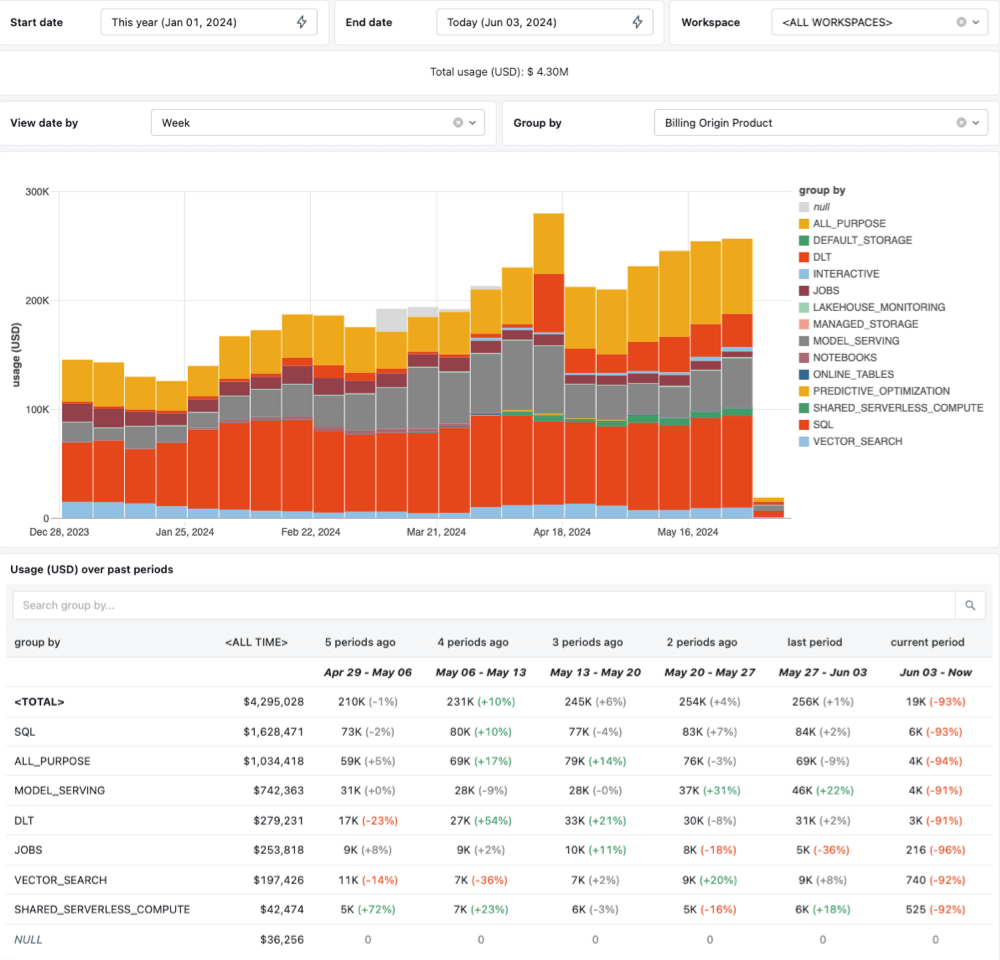
To make value administration extra clear, we have improved our cost-tracking capabilities. All compute prices related to serverless will now be absolutely trackable all the way down to the person Pocket book, Job, or Pipeline run. This implies you’ll not see shared serverless compute prices unattributed to any specific workload. This granular attribution gives visibility into the total value of every workload, making it simpler to observe and govern bills. As well as, we have added new fields to the billable utilization system desk, together with Job title, Pocket book path, and person identification for Pipelines to simplify value reporting. We have created a dashboard template that makes visualizing value developments in your workspaces simple. You may study extra and obtain the template right here.
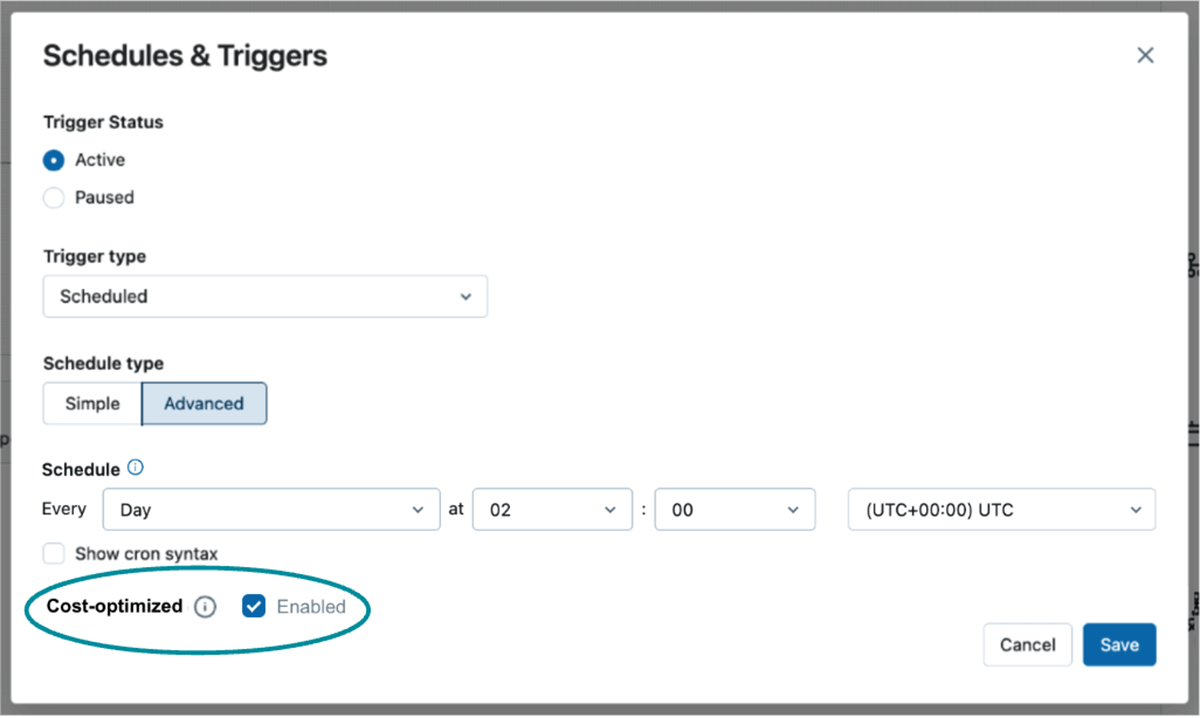
Future controls that will let you point out a desire for value optimization
For every of your information platform workloads, you must decide the proper steadiness between efficiency and price. With serverless compute, we’re dedicated to simplifying the way you meet your particular workloads’ worth/efficiency objectives. At present, our serverless providing focuses on efficiency – we optimize infrastructure and handle our compute fleet in order that your workloads expertise quick startup and quick runtimes. That is nice for workloads with low latency wants and when you do not need to handle or pay as an example swimming pools.
Nevertheless, we have now additionally heard your suggestions relating to the necessity for less expensive choices for sure Jobs and Pipelines. For some workloads, you might be keen to sacrifice some startup time or execution pace for decrease prices. In response, we’re thrilled to introduce a set of straightforward, easy controls that will let you prioritize value financial savings over efficiency. This new flexibility will will let you customise your compute technique to raised meet the precise worth and efficiency necessities of your workloads. Keep tuned for extra updates on this thrilling improvement within the coming months and sign-up to the preview waitlist right here.
Unlock 50% Financial savings on Serverless Compute – Restricted-Time Introductory Provide!
Reap the benefits of our introductory reductions: get 50% off serverless compute for Jobs and Pipelines and 30% off for Notebooks, out there till October 31, 2024. This limited-time supply is the right alternative to discover serverless compute at a diminished value—don’t miss out!
Begin utilizing serverless compute at the moment:
- Allow serverless compute in your account on AWS or Azure
- Ensure that your workspace is enabled to make use of Unity Catalog and in a supported area in AWS or Azure
- For present PySpark workloads, guarantee they’re suitable with shared entry mode and DBR 14.3+
- Observe the precise directions for connecting your Notebooks, Jobs, Pipelines to serverless compute
- Leverage serverless compute from any third-party system utilizing Databricks Join. Develop regionally out of your IDE, or seamlessly combine your purposes with Databricks in Python for a clean, environment friendly workflow.