{kind=link}

A current paper from LG AI Analysis means that supposedly ‘open’ datasets used for coaching AI fashions could also be providing a false sense of safety – discovering that just about 4 out of 5 AI datasets labeled as ‘commercially usable’ really include hidden authorized dangers.
Such dangers vary from the inclusion of undisclosed copyrighted materials to restrictive licensing phrases buried deep in a dataset’s dependencies. If the paper’s findings are correct, corporations counting on public datasets might have to rethink their present AI pipelines, or danger authorized publicity downstream.
The researchers suggest a radical and probably controversial answer: AI-based compliance brokers able to scanning and auditing dataset histories quicker and extra precisely than human attorneys.
The paper states:
‘This paper advocates that the authorized danger of AI coaching datasets can’t be decided solely by reviewing surface-level license phrases; a radical, end-to-end evaluation of dataset redistribution is important for guaranteeing compliance.
‘Since such evaluation is past human capabilities as a consequence of its complexity and scale, AI brokers can bridge this hole by conducting it with larger velocity and accuracy. With out automation, important authorized dangers stay largely unexamined, jeopardizing moral AI improvement and regulatory adherence.
‘We urge the AI analysis group to acknowledge end-to-end authorized evaluation as a elementary requirement and to undertake AI-driven approaches because the viable path to scalable dataset compliance.’
Analyzing 2,852 well-liked datasets that appeared commercially usable based mostly on their particular person licenses, the researchers’ automated system discovered that solely 605 (round 21%) had been really legally secure for commercialization as soon as all their parts and dependencies had been traced
The new paper is titled Do Not Belief Licenses You See — Dataset Compliance Requires Large-Scale AI-Powered Lifecycle Tracing, and comes from eight researchers at LG AI Analysis.
Rights and Wrongs
The authors spotlight the challenges confronted by corporations pushing ahead with AI improvement in an more and more unsure authorized panorama – as the previous educational ‘honest use’ mindset round dataset coaching offers method to a fractured setting the place authorized protections are unclear and secure harbor is now not assured.
As one publication identified lately, corporations have gotten more and more defensive in regards to the sources of their coaching information. Writer Adam Buick feedback*:
‘[While] OpenAI disclosed the primary sources of knowledge for GPT-3, the paper introducing GPT-4 revealed solely that the information on which the mannequin had been skilled was a combination of ‘publicly accessible information (similar to web information) and information licensed from third-party suppliers’.
‘The motivations behind this transfer away from transparency haven’t been articulated in any explicit element by AI builders, who in lots of circumstances have given no clarification in any respect.
‘For its half, OpenAI justified its determination to not launch additional particulars relating to GPT-4 on the idea of considerations relating to ‘the aggressive panorama and the security implications of large-scale fashions’, with no additional clarification inside the report.’
Transparency generally is a disingenuous time period – or just a mistaken one; for example, Adobe’s flagship Firefly generative mannequin, skilled on inventory information that Adobe had the rights to take advantage of, supposedly supplied prospects reassurances in regards to the legality of their use of the system. Later, some proof emerged that the Firefly information pot had change into ‘enriched’ with probably copyrighted information from different platforms.
As we mentioned earlier this week, there are rising initiatives designed to guarantee license compliance in datasets, together with one that may solely scrape YouTube movies with versatile Inventive Commons licenses.
The issue is that the licenses in themselves could also be inaccurate, or granted in error, as the brand new analysis appears to point.
Analyzing Open Supply Datasets
It’s troublesome to develop an analysis system such because the authors’ Nexus when the context is consistently shifting. Due to this fact the paper states that the NEXUS Information Compliance framework system relies on ‘ numerous precedents and authorized grounds at this cut-off date’.
NEXUS makes use of an AI-driven agent known as AutoCompliance for automated information compliance. AutoCompliance is comprised of three key modules: a navigation module for internet exploration; a question-answering (QA) module for info extraction; and a scoring module for authorized danger evaluation.
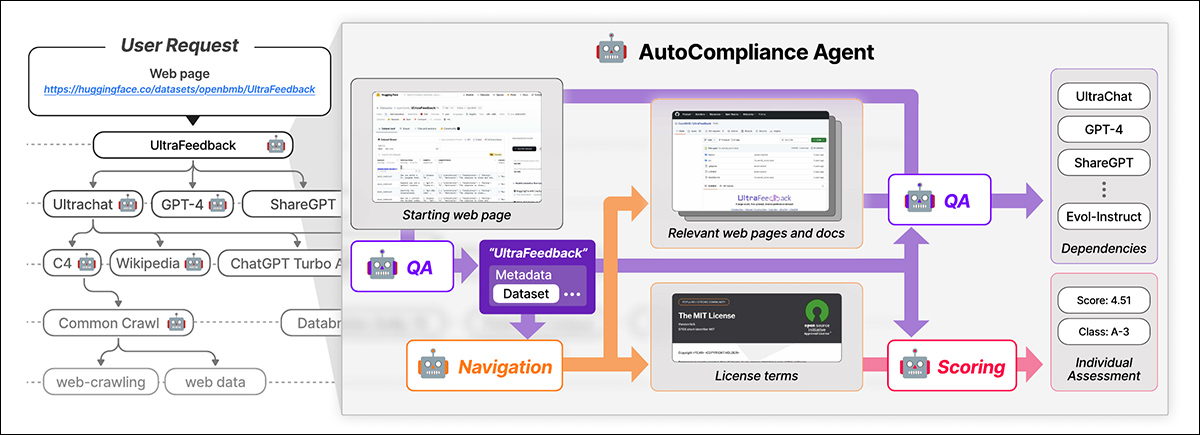
AutoCompliance begins with a user-provided webpage. The AI extracts key particulars, searches for associated sources, identifies license phrases and dependencies, and assigns a authorized danger rating. Supply: https://arxiv.org/pdf/2503.02784
These modules are powered by fine-tuned AI fashions, together with the EXAONE-3.5-32B-Instruct mannequin, skilled on artificial and human-labeled information. AutoCompliance additionally makes use of a database for caching outcomes to reinforce effectivity.
AutoCompliance begins with a user-provided dataset URL and treats it as the basis entity, looking for its license phrases and dependencies, and recursively tracing linked datasets to construct a license dependency graph. As soon as all connections are mapped, it calculates compliance scores and assigns danger classifications.
The Information Compliance framework outlined within the new work identifies numerous† entity sorts concerned within the information lifecycle, together with datasets, which kind the core enter for AI coaching; information processing software program and AI fashions, that are used to remodel and make the most of the information; and Platform Service Suppliers, which facilitate information dealing with.
The system holistically assesses authorized dangers by contemplating these numerous entities and their interdependencies, transferring past rote analysis of the datasets’ licenses to incorporate a broader ecosystem of the parts concerned in AI improvement.
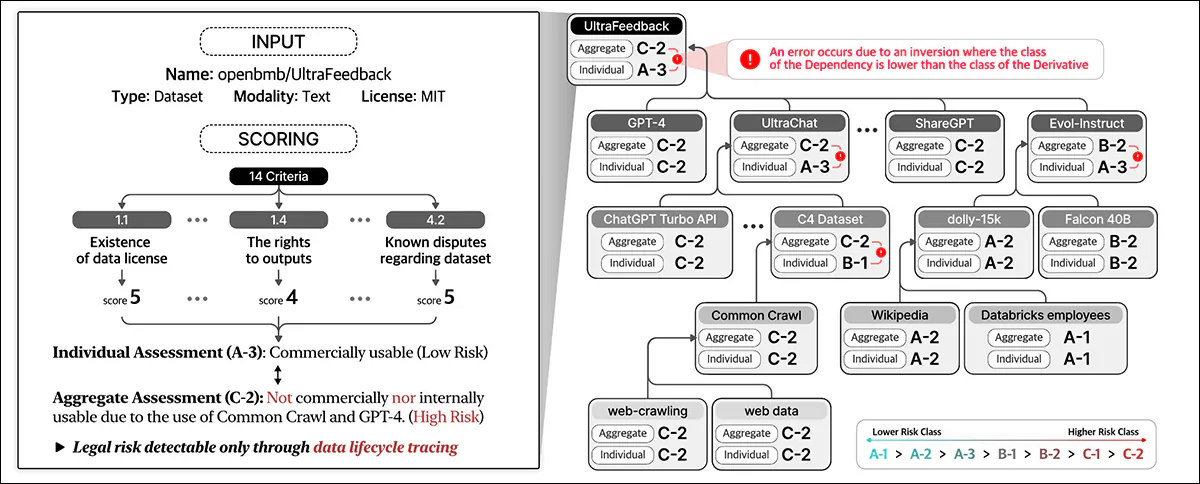
Information Compliance assesses authorized danger throughout the total information lifecycle. It assigns scores based mostly on dataset particulars and on 14 standards, classifying particular person entities and aggregating danger throughout dependencies.
Coaching and Metrics
The authors extracted the URLs of the highest 1,000 most-downloaded datasets at Hugging Face, randomly sub-sampling 216 objects to represent a check set.
The EXAONE mannequin was fine-tuned on the authors’ customized dataset, with the navigation module and question-answering module utilizing artificial information, and the scoring module utilizing human-labeled information.
Floor-truth labels had been created by 5 authorized specialists skilled for a minimum of 31 hours in related duties. These human specialists manually recognized dependencies and license phrases for 216 check circumstances, then aggregated and refined their findings by means of dialogue.
With the skilled, human-calibrated AutoCompliance system examined in opposition to ChatGPT-4o and Perplexity Professional, notably extra dependencies had been found inside the license phrases:
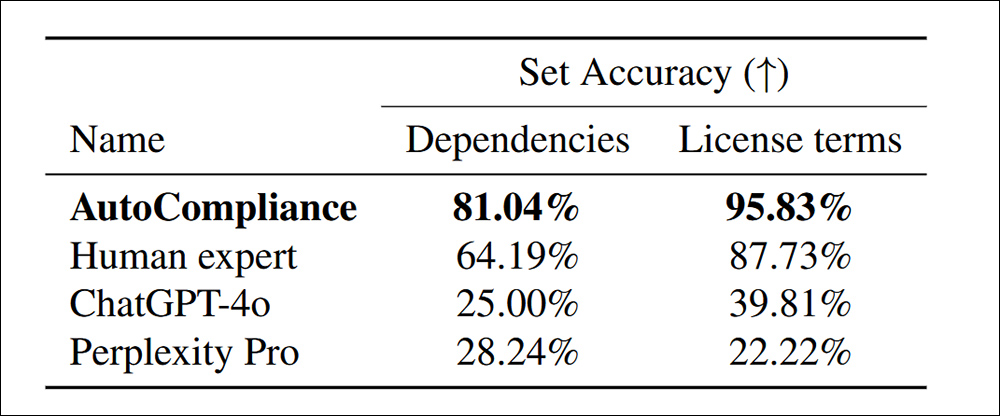
Accuracy in figuring out dependencies and license phrases for 216 analysis datasets.
The paper states:
‘The AutoCompliance considerably outperforms all different brokers and Human knowledgeable, reaching an accuracy of 81.04% and 95.83% in every job. In distinction, each ChatGPT-4o and Perplexity Professional present comparatively low accuracy for Supply and License duties, respectively.
‘These outcomes spotlight the superior efficiency of the AutoCompliance, demonstrating its efficacy in dealing with each duties with outstanding accuracy, whereas additionally indicating a considerable efficiency hole between AI-based fashions and Human knowledgeable in these domains.’
When it comes to effectivity, the AutoCompliance strategy took simply 53.1 seconds to run, in distinction to 2,418 seconds for equal human analysis on the identical duties.
Additional, the analysis run value $0.29 USD, in comparison with $207 USD for the human specialists. It needs to be famous, nonetheless, that that is based mostly on renting a GCP a2-megagpu-16gpu node month-to-month at a charge of $14,225 per thirty days – signifying that this sort of cost-efficiency is said primarily to a large-scale operation.
Dataset Investigation
For the evaluation, the researchers chosen 3,612 datasets combining the three,000 most-downloaded datasets from Hugging Face with 612 datasets from the 2023 Information Provenance Initiative.
The paper states:
‘Ranging from the three,612 goal entities, we recognized a complete of 17,429 distinctive entities, the place 13,817 entities appeared because the goal entities’ direct or oblique dependencies.
‘For our empirical evaluation, we think about an entity and its license dependency graph to have a single-layered construction if the entity doesn’t have any dependencies and a multi-layered construction if it has a number of dependencies.
‘Out of the three,612 goal datasets, 2,086 (57.8%) had multi-layered buildings, whereas the opposite 1,526 (42.2%) had single-layered buildings with no dependencies.’
Copyrighted datasets can solely be redistributed with authorized authority, which can come from a license, copyright legislation exceptions, or contract phrases. Unauthorized redistribution can result in authorized penalties, together with copyright infringement or contract violations. Due to this fact clear identification of non-compliance is important.
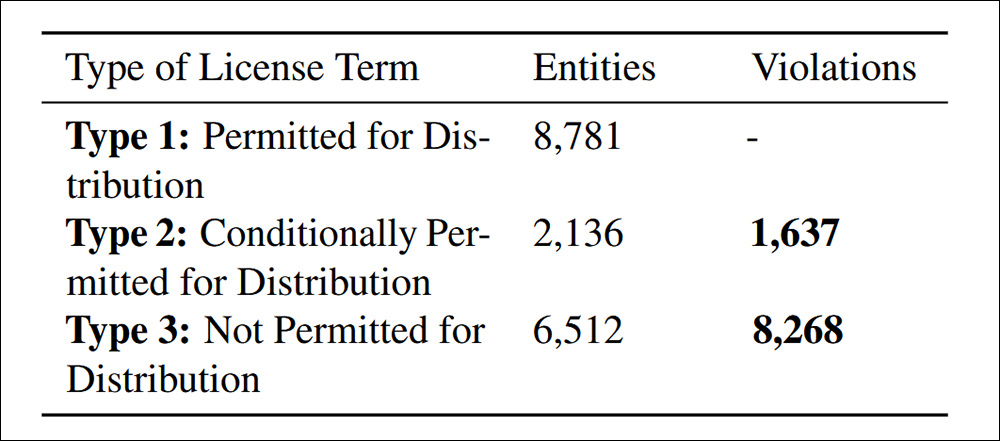
Distribution violations discovered below the paper’s cited Criterion 4.4. of Information Compliance.
The examine discovered 9,905 circumstances of non-compliant dataset redistribution, cut up into two classes: 83.5% had been explicitly prohibited below licensing phrases, making redistribution a transparent authorized violation; and 16.5% concerned datasets with conflicting license circumstances, the place redistribution was allowed in concept however which didn’t meet required phrases, creating downstream authorized danger.
The authors concede that the chance standards proposed in NEXUS should not common and should fluctuate by jurisdiction and AI software, and that future enhancements ought to concentrate on adapting to altering international laws whereas refining AI-driven authorized overview.
Conclusion
This can be a prolix and largely unfriendly paper, however addresses maybe the most important retarding think about present business adoption of AI – the likelihood that apparently ‘open’ information will later be claimed by numerous entities, people and organizations.
Beneath DMCA, violations can legally entail huge fines on a per-case foundation. The place violations can run into the hundreds of thousands, as within the circumstances found by the researchers, the potential authorized legal responsibility is really important.
Moreover, corporations that may be confirmed to have benefited from upstream information can not (as regular) declare ignorance as an excuse, a minimum of within the influential US market. Neither do they presently have any reasonable instruments with which to penetrate the labyrinthine implications buried in supposedly open-source dataset license agreements.
The issue in formulating a system similar to NEXUS is that it might be difficult sufficient to calibrate it on a per-state foundation contained in the US, or a per-nation foundation contained in the EU; the prospect of making a very international framework (a sort of ‘Interpol for dataset provenance’) is undermined not solely by the conflicting motives of the varied governments concerned, however the truth that each these governments and the state of their present legal guidelines on this regard are continually altering.
* My substitution of hyperlinks for the authors’ citations.
† Six sorts are prescribed within the paper, however the remaining two should not outlined.
First revealed Friday, March 7, 2025