(TAW4/Shutterstock)
Firms will waste $135 billion price of cloud sources in 2024, or about 30% of the worldwide public cloud spending of $675 billion, in keeping with Gartner. That’s the dangerous information. The excellent news is that an array of FinOps service suppliers are lining as much as assist clients reclaim these cloud {dollars}.
Within the early days of the general public cloud, value financial savings and agility have been the large drivers. The thought was that corporations would transfer their information and functions to the cloud to get out of the enterprise of shopping for and managing infrastructure, which diminished their total IT spending and freed them to give attention to their core enterprise.
Through the years, the general public cloud mantra has morphed a bit, and immediately’s cloud pillars are velocity and comfort. The general public cloud is great for startups and fast-growing corporations that don’t need to commit massive sums to compute and storage infrastructure that they might or might not want. They’re prepared to pay a premium for the aptitude to quickly scale their wants on-demand.
Nevertheless, immediately’s public cloud isn’t as nice for corporations which might be bigger or slowly rising. Firms which might be paying on-demand costs however aren’t making the most of on-demand scalability are overpaying, whereas corporations that miscalculated how a lot compute and storage they would wish are discovering that the general public cloud isn’t practically as elastic as they have been led to imagine. That’s notably true in the case of storage.
Prospects’ cloud payments have elevated dramatically lately. A latest Flexera report found a 21% enhance yr over yr in organizations which might be spending $1 million or extra per thirty days on cloud.
In its latest Funds Planning Information for 2025, Forrester suggested expertise executives to “ruthlessly automate handbook duties” to scale back cloud sprawl.
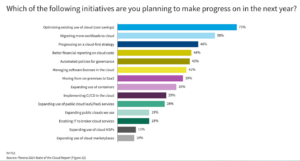
Value financial savings within the cloud is the highest precedence this yr, in keeping with Flexera’s 2024 State of the Cloud Report
“Cease unbiased cloud spending by establishing a transparent FinOps observe,” the analyst group wrote. “This consists of organising a centralized group liable for managing cloud prices and optimizing useful resource utilization. Subsequent, implement a cloud value waste, and make data-driven choices to optimize prices. These instruments may also help automate the method of figuring out unused sources, right-sizing situations, and imposing value governance insurance policies.
One of many FinOps distributors serving to clients to remain on high of their cloud storage and compute spending is Zesty. Omer Hamerman, Principal Engineer at Zesty, says Zesty Disk permits clients to shrink and develop their AWS EBS storage on the fly based mostly on utilization, and reduce as much as 60% of their storage prices.
“The primary query I ask clients [is] how do you resolve how a lot storage you must provision for a typical utility?” he tells Datanami. “And no person is aware of the reply.”
If a buyer thinks they’ll want 10GB of block storage for his or her machine studying utility, for instance, they’ll provision a single block of 10GB from AWS and use it. In the event that they want extra storage, they’ll merely provision extra capability as they go. But when it seems they want much less storage, that’s the place issues get fascinating.

Zesty Disk breaks up Amazon EBS into smaller, extra simply managed blocks (Picture courtesy Zesty)
Zesty’s trick is to interrupt that preliminary 10GB order up into a number of blocks, similar to one 5GB block, two 2GB blocks, and one 1GB block, and unfold the purchasers’ information throughout all of them. If Zesty’s monitoring detects that the shopper utility solely wants 3GB, they’ll flip off the 5GB and 1GB blocks, and transfer the info below the covers to the 2 2GB blocks, for 4GB complete. Zesty Disk does this mechanically via API connections to AWS, and there’s no interruption to the movement of information or the applying, Hamerman says.
“We permit you to nonetheless hold your block storage along with your efficiency and the whole lot that comes with having block storage hooked up, however nonetheless achieve elasticity,” he says. “We’re like a DevOps engineer you put in in your server.”
This downside is pretty frequent amongst newer functions constructed atop trendy databases, the place clients don’t need to ever delete information, and with machine studying and AI functions, which might have unpredictable information storage wants, he says. Properly established functions, similar to CRM or ERP programs, are much less more likely to have this downside.
“That’s simply the character of functions. They develop over time. A few of them in a short time, a few of them fairly sluggish,” Hamerman says. “How do you forecast this stuff? Folks really can’t. It’s actually arduous to give attention to forecasts.”
Zesty, which is a member of the FinOps Basis, additionally gives Dedication Supervisor, which helps clients handle their EC2 and compute spending on AWS. The providing works by mechanically shifting workloads to the optimum mixture of AWS Reserved Occasion and Financial savings Plan situations, which include one- and three-year commitments.
If Zesty detects the shopper isn’t making good use of RI, for instance, it should shift workload to a different plan, or the Convertible Reserved Situations (CRIs). “The whole lot which you can reserve for both a yr or three years, we may also help you care for the reservations,” Hamerman says. The corporate is working to roll out an answer for AWS Spot situations, he says.
One other FinOps buyer to maintain in your radar is nOps. The San Francisco firm says it offers “full visibility” into clients’ AWS prices, together with reserved situations and the AWS Spot market.
“With consciousness of all of your AWS commitments and the AWS Spot market, nOps mechanically fulfills your commitments and provisions extra compute to Spot,” the corporate says.
nOps, which is also a FinOps Basis member, says it has saved its clients greater than $1.5 billion in AWS spending, and grown its buyer base by 450% over the previous 18 months.
The rise of generative AI has introduced cloud compute optimization to a tipping level, says nOps CEO and Founder JT Giri.
“Whereas numerous level options tackle particular cloud optimization wants, engineering groups should not have the time to manually handle and optimize the ever-growing complexity of cloud sources,” he says in a press launch. “As a substitute, they want one resolution that gives full visibility into cloud spend, to automated optimization and single-click cloud waste clear up to allow them to give attention to innovation to drive firm progress. Because of this we based nOps and why now we have been so profitable.
Associated Objects:
Flexera 2024 State of the Cloud Reveals Spending because the High Problem of Cloud Computing
Waste Not, Need Not
The Cloud Is Nice for Knowledge, Apart from These Tremendous Excessive Prices