An Introduction to Time Sequence Forecasting with Generative AI
Time collection forecasting has been a cornerstone of enterprise useful resource planning for many years. Predictions about future demand information important selections such because the variety of models to inventory, labor to rent, capital investments into manufacturing and success infrastructure, and the pricing of products and companies. Correct demand forecasts are important for these and lots of different enterprise selections.
Nonetheless, forecasts are not often if ever excellent. Within the mid-2010s, many organizations coping with computational limitations and restricted entry to superior forecasting capabilities reported forecast accuracies of solely 50-60%. However with the broader adoption of the cloud, the introduction of much more accessible applied sciences and the improved accessibility of exterior information sources comparable to climate and occasion information, organizations are starting to see enhancements.
As we enter the period of generative AI, a brand new class of fashions known as time collection transformers seems able to serving to organizations ship much more enchancment. Just like massive language fashions (like ChatGPT) that excel at predicting the following phrase in a sentence, time collection transformers predict the following worth in a numerical sequence. With publicity to massive volumes of time collection information, these fashions change into consultants at choosing up on refined patterns of relationships between the values in these collection with demonstrated success throughout a wide range of domains.
On this weblog, we’ll present a high-level introduction to this class of forecasting fashions, meant to assist managers, analysts and information scientists develop a primary understanding of how they work. We’ll then present entry to a collection of notebooks constructed round publicly out there datasets demonstrating how organizations housing their information in Databricks could simply faucet into a number of of the most well-liked of those fashions for his or her forecasting wants. We hope that this helps organizations faucet into the potential of generative AI for driving higher forecast accuracies.
Understanding Time Sequence Transformers
Generative AI fashions are a type of a deep neural community, a posh machine studying mannequin inside which numerous inputs are mixed in a wide range of methods to reach at a predicted worth. The mechanics of how the mannequin learns to mix inputs to reach at an correct prediction is known as a mannequin’s structure.
The breakthrough in deep neural networks which have given rise to generative AI has been the design of a specialised mannequin structure referred to as a transformer. Whereas the precise particulars of how transformers differ from different deep neural community architectures are fairly complicated, the easy matter is that the transformer is excellent at choosing up on the complicated relationships between values in lengthy sequences.
To coach a time collection transformer, an appropriately architected deep neural community is uncovered to a big quantity of time collection information. After it has had the chance to coach on hundreds of thousands if not billions of time collection values, it learns the complicated patterns of relationships present in these datasets. When it’s then uncovered to a beforehand unseen time collection, it might probably use this foundational data to determine the place comparable patterns of relationships throughout the time collection exist and predict new values within the sequence.
This means of studying relationships from massive volumes of information is known as pre-training. As a result of the data gained by the mannequin throughout pre-training is extremely generalizable, pre-trained fashions known as basis fashions could be employed towards beforehand unseen time collection with out extra coaching. That stated, extra coaching on a company’s proprietary information, a course of known as fine-tuning, could in some cases assist the group obtain even higher forecast accuracy. Both means, as soon as the mannequin is deemed to be in a passable state, the group merely must current it with a time collection and ask, what comes subsequent?
Addressing Widespread Time Sequence Challenges
Whereas this high-level understanding of a time collection transformer could make sense, most forecast practitioners will probably have three instant questions. First, whereas two time collection could comply with the same sample, they might function at fully totally different scales, how does a transformer overcome that downside? Second, inside most time collection fashions there are day by day, weekly and annual patterns of seasonality that should be thought-about, how do fashions know to search for these patterns? Third, many time collection are influenced by exterior elements, how can this information be integrated into the forecast era course of?
The primary of those challenges is addressed by mathematically standardizing all time collection information utilizing a set of methods known as scaling. The mechanics of this are inside to every mannequin’s structure however basically incoming time collection values are transformed to a regular scale that permits the mannequin to acknowledge patterns within the information primarily based on its foundational data. Predictions are made and people predictions are then returned to the unique scale of the unique information.
Relating to the seasonal patterns, on the coronary heart of the transformer structure is a course of referred to as self-attention. Whereas this course of is kind of complicated, essentially this mechanism permits the mannequin to be taught the diploma to which particular prior values affect a given future worth.
Whereas that seems like the answer for seasonality, it is essential to grasp that fashions differ of their capacity to choose up on low-level patterns of seasonality primarily based on how they divide time collection inputs. By a course of referred to as tokenization, values in a time collection are divided into models referred to as tokens. A token could also be a single time collection worth or it might be a brief sequence of values (sometimes called a patch).
The scale of the token determines the bottom degree of granularity at which seasonal patterns could be detected. (Tokenization additionally defines logic for coping with lacking values.) When exploring a specific mannequin, it is essential to learn the generally technical data round tokenization to grasp whether or not the mannequin is suitable to your information.
Lastly, concerning exterior variables, time collection transformers make use of a wide range of approaches. In some, fashions are skilled on each time collection information and associated exterior variables. In others, fashions are architected to grasp {that a} single time collection could also be composed of a number of, parallel, associated sequences. Whatever the exact method employed, some restricted help for exterior variables could be discovered with these fashions.
A Temporary Have a look at 4 In style Time Sequence Transformers
With a high-level understanding of time collection transformers beneath our belt, let’s take a second to have a look at 4 fashionable basis time collection transformer fashions:
Chronos
Chronos is a household of open-source, pretrained time collection forecasting fashions from Amazon. These fashions take a comparatively naive strategy to forecasting by decoding a time collection as only a specialised language with its personal patterns of relationships between tokens. Regardless of this comparatively simplistic strategy which incorporates help for lacking values however not exterior variables, the Chronos household of fashions has demonstrated some spectacular outcomes as a general-purpose forecasting resolution (Determine 1).
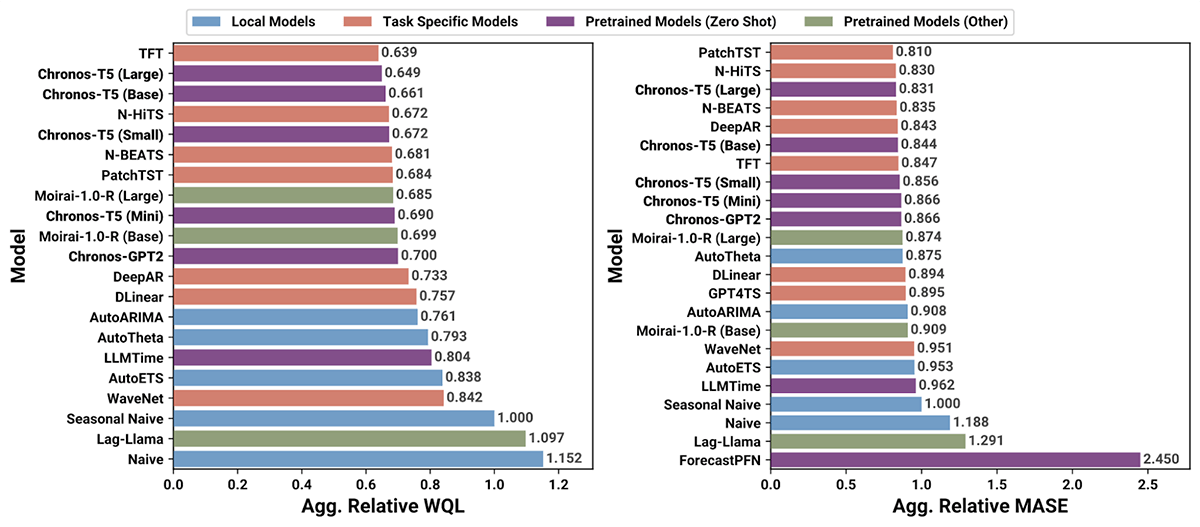
Determine 1. Analysis metrics for Chronos and varied different forecasting fashions utilized to 27 benchmarking information units (from https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM is an open-source basis mannequin developed by Google Analysis, pre-trained on over 100 billion real-world time collection factors. Not like Chronos, TimesFM contains a while series-specific mechanisms in its structure that allow the consumer to exert fine-grained management over how inputs and outputs are organized. This has an affect on how seasonal patterns are detected but additionally the computation occasions related to the mannequin. TimesFM has confirmed itself to be a really highly effective and versatile time collection forecasting software (Determine 2).
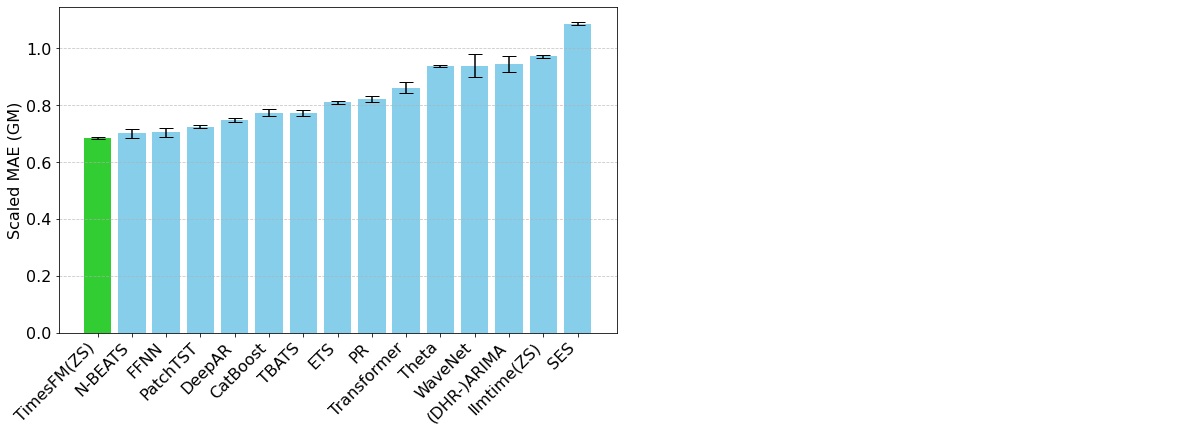
Determine 2. Analysis metrics for TimesFM and varied different fashions towards the Monash Forecasting Archive dataset (from https://analysis.google/weblog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, developed by Salesforce AI Analysis, is one other open-source basis mannequin for time collection forecasting. Skilled on “27 billion observations spanning 9 distinct domains”, Moirai is introduced as a common forecaster able to supporting each lacking values and exterior variables. Variable patch sizes enable organizations to tune the mannequin to the seasonal patterns of their datasets and when utilized correctly have been demonstrated to carry out fairly nicely towards different fashions (Determine 3).
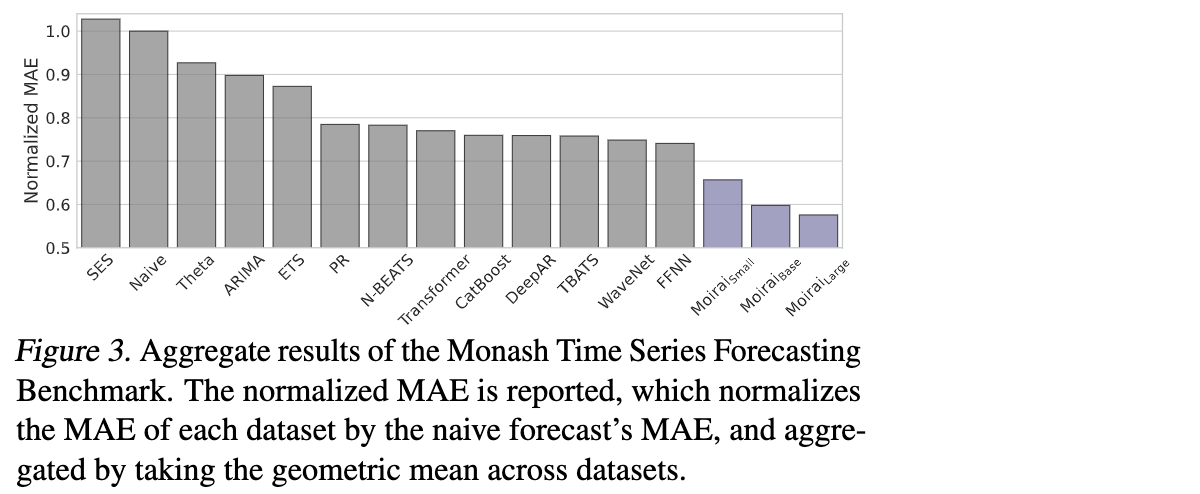
Determine 3. Analysis metrics for Moirai and varied different fashions towards the Monash Time Sequence Forecasting Benchmark (from https://weblog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT is a proprietary mannequin with help for exterior (exogenous) variables however not lacking values. Targeted on ease of use, TimeGPT is hosted by a public API that permits organizations to generate forecasts with as little as a single line of code. In benchmarking the mannequin towards 300,000 distinctive collection at totally different ranges of temporal granularity, the mannequin was proven to provide some spectacular outcomes with little or no forecasting latency (Determine 4).
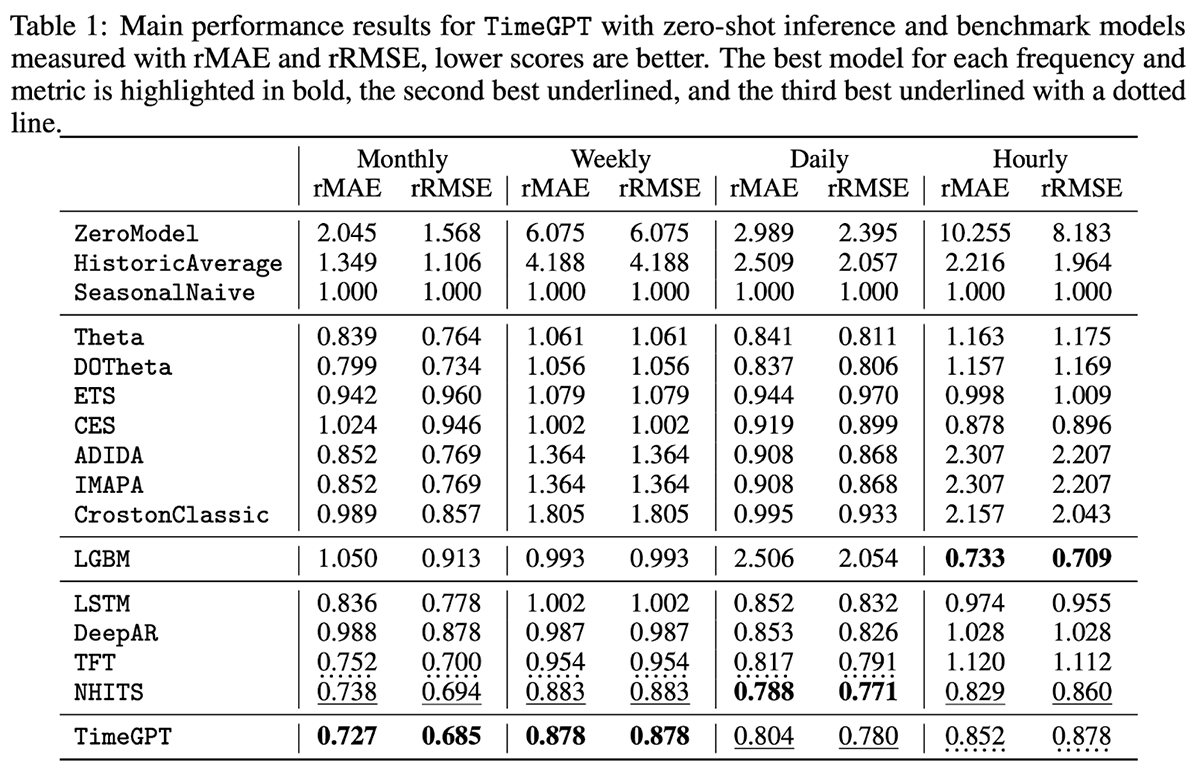
Determine 4. Analysis metrics for TimeGPT and varied different fashions towards 300,000 distinctive collection (from https://arxiv.org/pdf/2310.03589)
Getting Began with Transformer Forecasting on Databricks
With so many mannequin choices and extra nonetheless on the best way, the important thing query for many organizations is, the way to get began in evaluating these fashions utilizing their very own proprietary information? As with all different forecasting strategy, organizations utilizing time collection forecasting fashions should current their historic information to the mannequin to create predictions, and people predictions have to be rigorously evaluated and finally deployed to downstream programs to make them actionable.
Due to Databricks’ scalability and environment friendly use of cloud sources, many organizations have lengthy used it as the premise for his or her forecasting work, producing tens of hundreds of thousands of forecasts on a day by day and even larger frequency to run their enterprise operations. The introduction of a brand new class of forecasting fashions does not change the character of this work, it merely supplies these organizations extra choices for doing it inside this surroundings.
That is to not say that there usually are not some new wrinkles that include these fashions. Constructed on a deep neural community structure, many of those fashions carry out greatest when employed towards a GPU, and within the case of TimeGPT, they might require API calls to an exterior infrastructure as a part of the forecast era course of. However essentially, the sample of housing a company’s historic time collection information, presenting that information to a mannequin and capturing the output to a queriable desk stays unchanged.
To assist organizations perceive how they might use these fashions inside a Databricks surroundings, we have assembled a collection of notebooks demonstrating how forecasts could be generated with every of the 4 fashions described above. Practitioners could freely obtain these notebooks and make use of them inside their Databricks surroundings to achieve familiarity with their use. The code introduced could then be tailored to different, comparable fashions, offering organizations utilizing Databricks as the premise for his or her forecasting efforts extra choices for utilizing generative AI of their useful resource planning processes.
Get began with Databricks for forecasting modeling right now with this collection of notebooks.