Pluralsight, the expertise workforce improvement firm, at present introduced the discharge of its expert-led course path targeted on understanding, detecting, and defending towards the extremely expert Volt Hurricane hacker group.
Volt Hurricane is a state-sponsored cyber group looking for to pre-position themselves on IT and OT networks to hold out cyberattacks towards U.S. important infrastructure, notably in communications, vitality, transportation, and water sectors. As an APT, Volt Hurricane has been referred to as “the defining risk of our technology” by FBI Director Christopher Wray.
“State-sponsored cybersecurity teams like Volt Hurricane are growing in quantity, but in addition in sophistication and persistence,” mentioned Bri Frost, Director of Curriculum, Cybersecurity and IT Ops at Pluralsight. “Menace actors and teams of this kind leverage superior methods by way of present instruments in a corporation’s surroundings to go undetected for prolonged durations of time, tailoring their assaults to persistently goal important infrastructure.”
The Volt Hurricane course sequence consists of seven expert-led programs and 6 hands-on lab experiences designed to equip learners with the techniques, expertise, and procedures to defend towards all these assaults. Learners will acquire data to implement controls to scale back the danger of those assaults happening in their very own environments.
“For cybersecurity professionals, there’s elevated urgency to develop the talents wanted to guard towards risk actors concentrating on important infrastructure,” mentioned Chris Herbert, Chief Content material Officer at Pluralsight “Given the elevated ranges of threats with main geopolitical implications, cybersecurity professionals should take a proactive method to enhance their safety expertise earlier than an assault occurs.”
The Volt Hurricane programs are the primary in a studying path created to handle detection and protection towards APTs. Programs embody Volt Hurricane: Command and Scripting Interpreter Emulation, Volt Hurricane: Credential Dumping Emulation, and Volt Hurricane: Indicator Removing Emulation.
Join a free trial of the Volt Hurricane programs and Pluralsight’s complete library of cybersecurity programs and certifications.
A lot has been written in regards to the whys and wherefores of the latest Crowdstrike incident. With out dwelling an excessive amount of on the previous (you may get the background right here), the query is, what can we do to plan for the long run? We requested our knowledgeable analysts what concrete steps organizations can take.
Don’t Belief Your Distributors
Does that sound harsh? It ought to. We now have zero belief in networks or infrastructure and entry administration, however then we enable ourselves to imagine software program and repair suppliers are 100% watertight. Safety is in regards to the permeability of the general assault floor—simply as water will discover a approach via, so will danger.
Crowdstrike was beforehand the darling of the trade, and its model carried appreciable weight. Organizations are inclined to suppose, “It’s a safety vendor, so we are able to belief it.” However you realize what they are saying about assumptions…. No vendor, particularly a safety vendor, needs to be given particular therapy.
By the way, for Crowdstrike to declare that this occasion wasn’t a safety incident utterly missed the purpose. Regardless of the trigger, the impression was denial of service and each enterprise and reputational injury.
Deal with Each Replace as Suspicious
Safety patches aren’t all the time handled the identical as different patches. They could be triggered or requested by safety groups moderately than ops, they usually could also be (perceived as) extra pressing. Nevertheless, there’s no such factor as a minor replace in safety or operations, as anybody who has skilled a nasty patch will know.
Each replace needs to be vetted, examined, and rolled out in a approach that manages the chance. Finest apply could also be to check on a smaller pattern of machines first, then to do the broader rollout, for instance, by a sandbox or a restricted set up. Should you can’t do this for no matter purpose (maybe contractual), think about your self working in danger till enough time has handed.
For instance, the Crowdstrike patch was an compulsory set up, nevertheless some organizations we converse to managed to dam the replace utilizing firewall settings. One group used its SSE platform to dam the replace servers as soon as it recognized the unhealthy patch. Because it had good alerting, this took about half-hour for the SecOps group to acknowledge and deploy.
One other throttled the Crowdstrike updates to 100Mb per minute – it was solely hit with six hosts and 25 endpoints earlier than it set this to zero.
Decrease Single Factors of Failure
Again within the day, resilience got here via duplication of particular techniques––the so-called “2N+1” the place N is the variety of parts. With the arrival of cloud, nevertheless, we’ve moved to the concept that all sources are ephemeral, so we don’t have to fret about that type of factor. Not true.
Ask the query: “What occurs if it fails?” the place “it” can imply any aspect of the IT structure. For instance, should you select to work with a single cloud supplier, take a look at particular dependencies––is it a couple of single digital machine or a area? On this case, the Microsoft Azure situation was confined to storage within the Central area, for instance. For the file, it could possibly and also needs to discuss with the detection and response agent itself.
In all circumstances, do you’ve one other place to failover to ought to “it” not perform? Complete duplication is (largely) unattainable for multi-cloud environments. A greater strategy is to outline which techniques and providers are enterprise vital based mostly on the price of an outage, then to spend cash on easy methods to mitigate the dangers. See it as insurance coverage; a obligatory spend.
Deal with Backups as Vital Infrastructure
Every layer of backup and restoration infrastructure counts as a vital enterprise perform and needs to be hardened as a lot as potential. Until knowledge exists in three locations, it’s unprotected as a result of should you solely have one backup, you received’t know which knowledge is appropriate; plus, failure is usually between the host and on-line backup, so that you additionally want offline backup.
The Crowdstrike incident solid a light-weight on enterprises that lacked a baseline of failover and restoration functionality for vital server-based techniques. As well as, that you must trust that the surroundings you’re spinning up is “clear” and resilient in its personal proper.
On this incident, a standard situation was that Bitlocker encryption keys had been saved in a database on a server that was “protected” by Crowdstrike. To mitigate this, think about using a very totally different set of safety instruments for backup and restoration to keep away from related assault vectors.
Plan, Take a look at, and Revise Failure Processes
Catastrophe restoration (and this was a catastrophe!) isn’t a one-shot operation. It might really feel burdensome to continually take into consideration what might go incorrect, so don’t––however maybe fear quarterly. Conduct an intensive evaluation of factors of weak point in your digital infrastructure and operations, and look to mitigate any dangers.
As per one dialogue, all danger is enterprise danger, and the board is in place as the last word arbiter of danger administration. It’s everybody’s job to speak dangers and their enterprise ramifications––in monetary phrases––to the board. If the board chooses to disregard these, then they’ve made a enterprise choice like every other.
The chance areas highlighted on this case are dangers related to unhealthy patches, the incorrect sorts of automation, an excessive amount of vendor belief, lack of resilience in secrets and techniques administration (i.e., Bitlocker keys), and failure to check restoration plans for each servers and edge units.
Look to Resilient Automation
The Crowdstrike state of affairs illustrated a dilemma: We will’t 100% belief automated processes. The one approach we are able to take care of expertise complexity is thru automation. The shortage of an automatic repair was a significant aspect of the incident, because it required corporations to “hand contact” every gadget, globally.
The reply is to insert people and different applied sciences into processes on the proper factors. Crowdstrike has already acknowledged the inadequacy of its high quality testing processes; this was not a fancy patch, and it will seemingly have been discovered to be buggy had it been examined correctly. Equally, all organizations have to have testing processes as much as scratch.
Rising applied sciences like AI and machine studying might assist predict and stop related points by figuring out potential vulnerabilities earlier than they turn into issues. They will also be used to create check knowledge, harnesses, scripts, and so forth, to maximise check protection. Nevertheless, if left to run with out scrutiny, they might additionally turn into a part of the issue.
Revise Vendor Due Diligence
This incident has illustrated the necessity to evaluate and “check” vendor relationships. Not simply when it comes to providers supplied but in addition contractual preparations (and redress clauses to allow you to hunt damages) for sudden incidents and, certainly, how distributors reply. Maybe Crowdstrike might be remembered extra for a way the corporate, and CEO George Kurtz, responded than for the problems brought about.
Little doubt classes will proceed to be realized. Maybe we should always have impartial our bodies audit and certify the practices of expertise corporations. Maybe it needs to be obligatory for service suppliers and software program distributors to make it simpler to modify or duplicate performance, moderately than the walled backyard approaches which are prevalent as we speak.
Total, although, the outdated adage applies: “Idiot me as soon as, disgrace on you; idiot me twice, disgrace on me.” We all know for a proven fact that expertise is fallible, but we hope with each new wave that it has turn into in a roundabout way proof against its personal dangers and the entropy of the universe. With technological nirvana postponed indefinitely, we should take the results on ourselves.
Contributors: Chris Ray, Paul Stringfellow, Jon Collins, Andrew Inexperienced, Chet Conforte, Darrel Kent, Howard Holton
A risk actor with seemingly connections to North Korea’s infamous Kimsuky group is distributing a brand new model of the open supply XenoRAT information-stealing malware, utilizing a fancy infrastructure of command-and-control (C2) servers, staging techniques, and take a look at machines.
The variant, that researchers at Cisco Talos are monitoring as MoonPeak after discovering it lately, is underneath energetic growth and has been continuously evolving in little increments over the previous few months — making detection and identification more difficult.
MoonPeak: A XenoRAT Variant
“Whereas MoonPeak accommodates many of the functionalities of the unique XenoRAT, our evaluation noticed constant adjustments all through the variants,” Cisco Talos researchers Asheer Malhotra, Guilherme Venere, and Vitor Venturs stated in a weblog publish this week. “That reveals the risk actors are modifying and evolving the code independently from the open-source model,” they famous.
XenoRAT is open supply malware coded in C# that turned out there without cost on GitHub final October. The Trojan packs a number of potent capabilities, together with keylogging, options for Person Entry Management (UAC) bypass, and a Hidden Digital Community Computing function that permits a risk actors to surreptitiously use a compromised system similtaneously the sufferer.
Cisco Talos noticed what it described as a “state-sponsored North Korean nexus of risk actors” tracked as UAT-5394, deploying MoonPeak in assaults earlier this 12 months. The attacker’s ways, methods, and procedures (TTPs) and its infrastructure have appreciable overlap with the Kimsuky group, lengthy identified for its espionage exercise concentrating on organizations in a number of sectors, particularly nuclear weapons analysis and coverage.
The overlaps led Cisco Talos to surmise that both the UAT-5394 exercise cluster it noticed was actually Kimsuky itself, or one other North Korean APT that used Kimsuky’s infrastructure. Within the absence of onerous proof, the safety vendor has determined in the intervening time at the very least to trace UAT-5394 as an impartial North Korean superior persistent risk (APT) group.
Fixed MoonPeak Modifications
In line with the Cisco Talos researchers, their evaluation of MoonPeak confirmed the attackers making a number of modifications to the XenoRAT code whereas additionally retaining a lot of its core features. Among the many first modifications was to vary the shopper namespace from “xeno rat shopper” to “cmdline” to make sure different XenoRAT variants wouldn’t work when linked to a MoonPeak server, Cisco Talos stated.
“The namespace change prevents rogue implants from connecting to their infrastructure and moreover prevents their very own implants from connecting to out-of-box XenoRAT C2 servers,” in response to the weblog publish.
Different modifications seem to have been made to obfuscate the malware and make evaluation tougher. Amongst them was the usage of a computation mannequin referred to as State Machines to carry out malware execution asynchronously, making this system circulation much less linear and subsequently tougher to comply with. Thus, the duty of reverse engineering the malware turns into more difficult and time-consuming.
Along with adjustments to the malware itself, Cisco Talos additionally noticed the risk actor making steady tweaks to its infrastructure. One of the vital notable was in early June, quickly after researchers at AhLabs reported on an earlier XenoRAT variant that UAT-5394 was utilizing. The disclosure prompted the risk actor to cease utilizing public cloud providers for internet hosting its payloads, and as a substitute transfer them to privately owned and managed techniques for C2, staging and testing its malware.
No less than two of the servers that Cisco Talos noticed UAT-5394 utilizing seemed to be related to different malware. In a single occasion, the safety vendor noticed a MoonPeak server connecting with a identified C2 server for Quasar RAT, a malware software related to the Kimsuky group.
“An evaluation of MoonPeak samples reveals an evolution within the malware and its corresponding C2 elements that warranted the risk actors deploy their implant variants a number of instances on their take a look at machines,” Cisco Talos researchers stated. The objective, they added, seems to be to introduce simply sufficient adjustments to make detection and identification tougher whereas additionally guaranteeing that particular MoonPeak variants work solely with particular C2 servers.
We’ve been having conversations for hundreds of years. Whether or not to convey info, conduct transactions, or just to test in on each other, individuals have yammered away, chattering and gesticulating, by means of spoken dialog for numerous generations. Solely in the previous few millennia have we begun to commit our conversations to writing, and solely in the previous few a long time have we begun to outsource them to the pc, a machine that reveals way more affinity for written correspondence than for the slangy vagaries of spoken language.
Article Continues Under
Computer systems have hassle as a result of between spoken and written language, speech is extra primordial. To have profitable conversations with us, machines should grapple with the messiness of human speech: the disfluencies and pauses, the gestures and physique language, and the variations in phrase alternative and spoken dialect that may stymie even probably the most fastidiously crafted human-computer interplay. Within the human-to-human state of affairs, spoken language additionally has the privilege of face-to-face contact, the place we are able to readily interpret nonverbal social cues.
In distinction, written language instantly concretizes as we commit it to file and retains usages lengthy after they develop into out of date in spoken communication (the salutation “To whom it could concern,” for instance), producing its personal fossil file of outdated phrases and phrases. As a result of it tends to be extra constant, polished, and formal, written textual content is essentially a lot simpler for machines to parse and perceive.
Spoken language has no such luxurious. Moreover the nonverbal cues that embellish conversations with emphasis and emotional context, there are additionally verbal cues and vocal behaviors that modulate dialog in nuanced methods: how one thing is claimed, not what. Whether or not rapid-fire, low-pitched, or high-decibel, whether or not sarcastic, stilted, or sighing, our spoken language conveys way more than the written phrase may ever muster. So in relation to voice interfaces—the machines we conduct spoken conversations with—we face thrilling challenges as designers and content material strategists.
We work together with voice interfaces for a wide range of causes, however in accordance with Michael McTear, Zoraida Callejas, and David Griol in The Conversational Interface, these motivations by and huge mirror the explanations we provoke conversations with different individuals, too (http://bkaprt.com/vcu36/01-01). Usually, we begin up a dialog as a result of:
we’d like one thing finished (corresponding to a transaction),
we wish to know one thing (info of some type), or
we’re social beings and wish somebody to speak to (dialog for dialog’s sake).
These three classes—which I name transactional, informational, and prosocial—additionally characterize basically each voice interplay: a single dialog from starting to finish that realizes some final result for the person, beginning with the voice interface’s first greeting and ending with the person exiting the interface. Be aware right here {that a} dialog in our human sense—a chat between those who results in some outcome and lasts an arbitrary size of time—may embody a number of transactional, informational, and prosocial voice interactions in succession. In different phrases, a voice interplay is a dialog, however a dialog is just not essentially a single voice interplay.
Purely prosocial conversations are extra gimmicky than charming in most voice interfaces, as a result of machines don’t but have the capability to actually wish to understand how we’re doing and to do the form of glad-handing people crave. There’s additionally ongoing debate as as to whether customers truly choose the form of natural human dialog that begins with a prosocial voice interplay and shifts seamlessly into different varieties. In actual fact, in Voice Person Interface Design, Michael Cohen, James Giangola, and Jennifer Balogh advocate sticking to customers’ expectations by mimicking how they work together with different voice interfaces fairly than making an attempt too onerous to be human—probably alienating them within the course of (http://bkaprt.com/vcu36/01-01).
That leaves two genres of conversations we are able to have with each other {that a} voice interface can simply have with us, too: a transactional voice interplay realizing some final result (“purchase iced tea”) and an informational voice interplay instructing us one thing new (“talk about a musical”).
Until you’re tapping buttons on a meals supply app, you’re typically having a dialog—and due to this fact a voice interplay—once you order a Hawaiian pizza with further pineapple. Even once we stroll as much as the counter and place an order, the dialog rapidly pivots from an preliminary smattering of neighborly small discuss to the true mission at hand: ordering a pizza (generously topped with pineapple, correctly).
Alison: Hey, how’s it going?
Burhan: Hello, welcome to Crust Deluxe! It’s chilly on the market. How can I provide help to?
Alison: Can I get a Hawaiian pizza with further pineapple?
Burhan: Certain, what dimension?
Alison: Giant.
Burhan: Anything?
Alison: No thanks, that’s it.
Burhan: One thing to drink?
Alison: I’ll have a bottle of Coke.
Burhan: You bought it. That’ll be $13.55 and about fifteen minutes.
Every progressive disclosure on this transactional dialog reveals increasingly of the specified final result of the transaction: a service rendered or a product delivered. Transactional conversations have sure key traits: they’re direct, to the purpose, and economical. They rapidly dispense with pleasantries.
In the meantime, some conversations are primarily about acquiring info. Although Alison may go to Crust Deluxe with the only goal of putting an order, she won’t truly wish to stroll out with a pizza in any respect. She could be simply as fascinated by whether or not they serve halal or kosher dishes, gluten-free choices, or one thing else. Right here, although we once more have a prosocial mini-conversation firstly to determine politeness, we’re after way more.
Alison: Hey, how’s it going?
Burhan: Hello, welcome to Crust Deluxe! It’s chilly on the market. How can I provide help to?
Alison: Can I ask just a few questions?
Burhan: In fact! Go proper forward.
Alison: Do you might have any halal choices on the menu?
Burhan: Completely! We will make any pie halal by request. We even have a lot of vegetarian, ovo-lacto, and vegan choices. Are you excited about some other dietary restrictions?
Alison: What about gluten-free pizzas?
Burhan: We will undoubtedly do a gluten-free crust for you, no drawback, for each our deep-dish and thin-crust pizzas. Anything I can reply for you?
Alison: That’s it for now. Good to know. Thanks!
Burhan: Anytime, come again quickly!
It is a very totally different dialogue. Right here, the purpose is to get a sure set of information. Informational conversations are investigative quests for the reality—analysis expeditions to collect information, information, or information. Voice interactions which can be informational could be extra long-winded than transactional conversations by necessity. Responses are usually lengthier, extra informative, and thoroughly communicated so the client understands the important thing takeaways.
At their core, voice interfaces make use of speech to assist customers in reaching their targets. However just because an interface has a voice part doesn’t imply that each person interplay with it’s mediated by means of voice. As a result of multimodal voice interfaces can lean on visible elements like screens as crutches, we’re most involved on this e book with pure voice interfaces, which rely fully on spoken dialog, lack any visible part in anyway, and are due to this fact way more nuanced and difficult to sort out.
Although voice interfaces have lengthy been integral to the imagined way forward for humanity in science fiction, solely lately have these lofty visions develop into absolutely realized in real voice interfaces.
Although written conversational interfaces have been fixtures of computing for a lot of a long time, voice interfaces first emerged within the early Nineties with text-to-speech (TTS) dictation applications that recited written textual content aloud, in addition to speech-enabled in-car programs that gave instructions to a user-provided deal with. With the appearance of interactive voice response (IVR) programs, meant as an alternative choice to overburdened customer support representatives, we grew to become acquainted with the primary true voice interfaces that engaged in genuine dialog.
IVR programs allowed organizations to cut back their reliance on name facilities however quickly grew to become infamous for his or her clunkiness. Commonplace within the company world, these programs have been primarily designed as metaphorical switchboards to information prospects to an actual telephone agent (“Say Reservations to e book a flight or test an itinerary”); chances are high you’ll enter a dialog with one once you name an airline or resort conglomerate. Regardless of their purposeful points and customers’ frustration with their incapacity to talk to an precise human instantly, IVR programs proliferated within the early Nineties throughout a wide range of industries (http://bkaprt.com/vcu36/01-02, PDF).
Whereas IVR programs are nice for extremely repetitive, monotonous conversations that typically don’t veer from a single format, they’ve a popularity for much less scintillating dialog than we’re used to in actual life (and even in science fiction).
Parallel to the evolution of IVR programs was the invention of the display reader, a device that transcribes visible content material into synthesized speech. For Blind or visually impaired web site customers, it’s the predominant technique of interacting with textual content, multimedia, or type components. Display screen readers symbolize maybe the closest equal we’ve got in the present day to an out-of-the-box implementation of content material delivered by means of voice.
Among the many first display readers recognized by that moniker was the Display screen Reader for the BBC Micro and NEEC Transportable developed by the Analysis Centre for the Schooling of the Visually Handicapped (RCEVH) on the College of Birmingham in 1986 (http://bkaprt.com/vcu36/01-03). That very same yr, Jim Thatcher created the primary IBM Display screen Reader for text-based computer systems, later recreated for computer systems with graphical person interfaces (GUIs) (http://bkaprt.com/vcu36/01-04).
With the speedy development of the net within the Nineties, the demand for accessible instruments for web sites exploded. Because of the introduction of semantic HTML and particularly ARIA roles starting in 2008, display readers began facilitating speedy interactions with net pages that ostensibly permit disabled customers to traverse the web page as an aural and temporal area fairly than a visible and bodily one. In different phrases, display readers for the net “present mechanisms that translate visible design constructs—proximity, proportion, and many others.—into helpful info,” writes Aaron Gustafson in A Listing Aside. “A minimum of they do when paperwork are authored thoughtfully” (http://bkaprt.com/vcu36/01-05).
Although deeply instructive for voice interface designers, there’s one important drawback with display readers: they’re troublesome to make use of and unremittingly verbose. The visible constructions of internet sites and net navigation don’t translate properly to display readers, generally leading to unwieldy pronouncements that identify each manipulable HTML factor and announce each formatting change. For a lot of display reader customers, working with web-based interfaces exacts a cognitive toll.
In Wired, accessibility advocate and voice engineer Chris Maury considers why the display reader expertise is ill-suited to customers counting on voice:
From the start, I hated the best way that Display screen Readers work. Why are they designed the best way they’re? It is senseless to current info visually after which, and solely then, translate that into audio. All the time and power that goes into creating the right person expertise for an app is wasted, and even worse, adversely impacting the expertise for blind customers. (http://bkaprt.com/vcu36/01-06)
In lots of circumstances, well-designed voice interfaces can velocity customers to their vacation spot higher than long-winded display reader monologues. In any case, visible interface customers take pleasure in darting across the viewport freely to seek out info, ignoring areas irrelevant to them. Blind customers, in the meantime, are obligated to pay attention to each utterance synthesized into speech and due to this fact prize brevity and effectivity. Disabled customers who’ve lengthy had no alternative however to make use of clunky display readers could discover that voice interfaces, significantly extra trendy voice assistants, provide a extra streamlined expertise.
Once we consider voice assistants (the subset of voice interfaces now commonplace in dwelling rooms, good houses, and workplaces), many people instantly image HAL from 2001: A Area Odyssey or hear Majel Barrett’s voice because the omniscient pc in Star Trek. Voice assistants are akin to non-public concierges that may reply questions, schedule appointments, conduct searches, and carry out different frequent day-to-day duties. They usually’re quickly gaining extra consideration from accessibility advocates for his or her assistive potential.
Earlier than the earliest IVR programs discovered success within the enterprise, Apple printed an illustration video in 1987 depicting the Data Navigator, a voice assistant that would transcribe spoken phrases and acknowledge human speech to an amazing diploma of accuracy. Then, in 2001, Tim Berners-Lee and others formulated their imaginative and prescient for a Semantic Net “agent” that will carry out typical errands like “checking calendars, making appointments, and discovering areas” (http://bkaprt.com/vcu36/01-07, behind paywall). It wasn’t till 2011 that Apple’s Siri lastly entered the image, making voice assistants a tangible actuality for customers.
Because of the plethora of voice assistants accessible in the present day, there’s appreciable variation in how programmable and customizable sure voice assistants are over others (Fig 1.1). At one excessive, every little thing besides vendor-provided options is locked down; for instance, on the time of their launch, the core performance of Apple’s Siri and Microsoft’s Cortana couldn’t be prolonged past their present capabilities. Even in the present day, it isn’t attainable to program Siri to carry out arbitrary features, as a result of there’s no means by which builders can work together with Siri at a low degree, other than predefined classes of duties like sending messages, hailing rideshares, making restaurant reservations, and sure others.
On the reverse finish of the spectrum, voice assistants like Amazon Alexa and Google House provide a core basis on which builders can construct {custom} voice interfaces. Because of this, programmable voice assistants that lend themselves to customization and extensibility have gotten more and more well-liked for builders who really feel stifled by the constraints of Siri and Cortana. Amazon presents the Alexa Abilities Package, a developer framework for constructing {custom} voice interfaces for Amazon Alexa, whereas Google House presents the flexibility to program arbitrary Google Assistant expertise. As we speak, customers can select from amongst hundreds of custom-built expertise inside each the Amazon Alexa and Google Assistant ecosystems.
Fig 1.1: Voice assistants like Amazon Alexa and Google House are usually extra programmable, and thus extra versatile, than their counterpart Apple Siri.
As companies like Amazon, Apple, Microsoft, and Google proceed to stake their territory, they’re additionally promoting and open-sourcing an unprecedented array of instruments and frameworks for designers and builders that intention to make constructing voice interfaces as simple as attainable, even with out code.
Typically by necessity, voice assistants like Amazon Alexa are usually monochannel—they’re tightly coupled to a tool and might’t be accessed on a pc or smartphone as a substitute. Against this, many improvement platforms like Google’s Dialogflow have launched omnichannel capabilities so customers can construct a single conversational interface that then manifests as a voice interface, textual chatbot, and IVR system upon deployment. I don’t prescribe any particular implementation approaches on this design-focused e book, however in Chapter 4 we’ll get into a few of the implications these variables might need on the best way you construct out your design artifacts.
Merely put, voice content material is content material delivered by means of voice. To protect what makes human dialog so compelling within the first place, voice content material must be free-flowing and natural, contextless and concise—every little thing written content material isn’t.
Our world is replete with voice content material in varied types: display readers reciting web site content material, voice assistants rattling off a climate forecast, and automatic telephone hotline responses ruled by IVR programs. On this e book, we’re most involved with content material delivered auditorily—not as an possibility, however as a necessity.
For many people, our first foray into informational voice interfaces shall be to ship content material to customers. There’s just one drawback: any content material we have already got isn’t in any approach prepared for this new habitat. So how will we make the content material trapped on our web sites extra conversational? And the way will we write new copy that lends itself to voice interactions?
Recently, we’ve begun slicing and dicing our content material in unprecedented methods. Web sites are, in lots of respects, colossal vaults of what I name macrocontent: prolonged prose that may lengthen for infinitely scrollable miles in a browser window, like microfilm viewers of newspaper archives. Again in 2002, properly earlier than the present-day ubiquity of voice assistants, technologist Anil Sprint outlined microcontent as permalinked items of content material that keep legible no matter setting, corresponding to e mail or textual content messages:
A day’s climate forcast [sic], the arrival and departure occasions for an airplane flight, an summary from an extended publication, or a single prompt message can all be examples of microcontent. (http://bkaprt.com/vcu36/01-08)
I’d replace Sprint’s definition of microcontent to incorporate all examples of bite-sized content material that go properly past written communiqués. In any case, in the present day we encounter microcontent in interfaces the place a small snippet of copy is displayed alone, unmoored from the browser, like a textbot affirmation of a restaurant reservation. Microcontent presents one of the best alternative to gauge how your content material will be stretched to the very edges of its capabilities, informing supply channels each established and novel.
As microcontent, voice content material is exclusive as a result of it’s an instance of how content material is skilled in time fairly than in area. We will look at a digital signal underground for an prompt and know when the subsequent practice is arriving, however voice interfaces maintain our consideration captive for durations of time that we are able to’t simply escape or skip, one thing display reader customers are all too accustomed to.
As a result of microcontent is essentially made up of remoted blobs with no relation to the channels the place they’ll ultimately find yourself, we have to be certain that our microcontent really performs properly as voice content material—and which means specializing in the 2 most vital traits of strong voice content material: voice content material legibility and voice content material discoverability.
Basically, the legibility and discoverability of our voice content material each should do with how voice content material manifests in perceived time and area.
Information annotation is the method of labeling information accessible in video, textual content, or pictures. Labeled datasets are required for supervised machine studying in order that machines can clearly perceive the enter patterns. In autonomous mobility, annotated datasets are important for coaching self-driving automobiles to acknowledge and reply to street situations, site visitors indicators, and potential hazards. Within the medical discipline, it helps enhance diagnostic accuracy, with labeled medical imaging information enabling AI methods to determine potential well being points extra successfully.
This rising demand underscores the significance of high-quality information annotation in advancing AI and ML functions throughout numerous sectors.
On this complete information, we’ll focus on all the things you might want to find out about information annotation. We’ll begin by inspecting the several types of information annotation, from textual content and picture to video and audio, and even cutting-edge methods like LiDAR annotation. Subsequent, we’ll examine handbook vs. automated annotation and make it easier to navigate the construct vs. purchase determination for annotation instruments.
Moreover, we’ll delve into information annotation for giant language fashions (LLMs) and its function in enterprise AI adoption. We’ll additionally stroll you thru the crucial steps within the annotation course of and share professional ideas and greatest practices that can assist you keep away from frequent pitfalls.
What’s information annotation?
Information annotation is the method of labeling and categorizing information to make it usable for machine studying fashions. It includes including significant metadata, tags, or labels to uncooked information, equivalent to textual content, pictures, movies, or audio, to assist machines perceive and interpret the knowledge precisely.
The first objective of knowledge annotation is to create high-quality, labeled datasets that can be utilized to coach and validate machine studying algorithms. By offering machines with annotated information, information scientists and builders can construct extra correct and environment friendly AI fashions that may be taught from patterns and examples within the information.
With out correctly annotated information, machines would battle to grasp and make sense of the huge quantities of unstructured information generated each day.
Forms of information annotation
Information annotation is a flexible course of that may be utilized to varied information varieties, every with its personal methods and functions. The info annotation market is primarily segmented into two fundamental classes: Pc Imaginative and prescient Sort and Pure Language Processing Sort.
Pc Imaginative and prescient annotation focuses on labeling visible information, whereas Pure Language Processing annotation offers with textual and audio information.
On this part, we’ll discover the commonest forms of information annotation and their particular use instances.
1. Textual content annotation: It includes labeling and categorizing textual information to assist machines perceive and interpret human language. On a regular basis textual content annotation duties embody:
Sentiment annotation: Figuring out and categorizing the feelings and opinions expressed in a textual content.
Intent annotation: Figuring out the aim or objective behind a person’s message or question.
Semantic annotation: Linking phrases or phrases to their corresponding meanings or ideas.
Named entity annotation: Figuring out and classifying named entities equivalent to individuals, organizations, and areas inside a textual content.
Relation annotation: Establishing the relationships between completely different entities or ideas talked about in a textual content.
2. Picture annotation: It includes including significant labels, tags, or bounding containers to digital pictures to assist machines interpret and perceive visible content material. This annotation kind is essential for creating laptop imaginative and prescient functions like facial recognition, object detection, and picture classification.
3. Video annotation: It extends the ideas of picture annotation to video information, permitting machines to grasp and analyze shifting visible content material. This annotation kind is crucial for autonomous automobiles, video surveillance, and gesture recognition functions.
4. Audio annotation: It focuses on labeling and transcribing audio information, equivalent to speech, music, and environmental sounds. This annotation kind is significant for creating speech recognition methods, voice assistants, and audio classification fashions.
5. LiDAR annotation: Gentle Detection and Ranging annotation includes labeling and categorizing 3D level cloud information generated by LiDAR sensors. This annotation kind is more and more important for autonomous driving, robotics, and 3D mapping functions.
When evaluating the several types of information annotation, it is clear that every has its personal distinctive challenges and necessities. Textual content annotation depends on linguistic experience and context understanding, whereas picture and video annotation requires visible notion expertise. Audio annotation is determined by correct transcription and sound recognition, and LiDAR annotation calls for spatial reasoning and 3D understanding.
The speedy development of the Information Annotation and Labeling Market displays the growing significance of knowledge annotation in AI and ML growth. In keeping with latest market analysis, the worldwide market is projected to develop from USD 0.8 billion in 2022 to USD 3.6 billion by 2027 at a compound annual development fee (CAGR) of 33.2%. This substantial development underscores information annotation’s crucial function in coaching and bettering AI and ML fashions throughout numerous industries.
Information annotation methods could be broadly categorized into handbook and automatic approaches. Every has its strengths and weaknesses, and the selection typically is determined by the mission’s particular necessities.
Guide annotation: Guide annotation includes human annotators reviewing and labeling information by hand. This strategy is usually extra correct and might deal with advanced or ambiguous instances, however it is usually time-consuming and costly. Guide annotation is especially helpful for duties that require human judgment, equivalent to sentiment evaluation or figuring out refined nuances in pictures or textual content.
Automated annotation: Automated annotation depends on machine studying algorithms to routinely label information based mostly on predefined guidelines or patterns. This technique is quicker and cheaper than handbook annotation, however it is probably not as correct, notably for edge instances or subjective duties. Automated annotation is well-suited for large-scale initiatives with comparatively easy labeling necessities.
Guide Information Annotation
Automated Information Annotation
Includes actual people tagging and categorizing several types of information.
It makes use of machine studying and AI algorithms to determine, tag, and categorize information.
It is extremely time-consuming and fewer environment friendly.
Very environment friendly and works sooner than handbook information annotation.
Vulnerable to human error
Fewer errors.
Excellent for small-scale initiatives that require subjectivity.
Excellent for large-scale initiatives that require extra objectivity.
This technique makes use of an individual’s functionality to finish duties.
This technique takes into consideration earlier information annotation duties to finish the duty.
Costly in comparison with automated information annotation.
Cheaper as in comparison with handbook information annotation
Human-in-the-Loop (HITL) strategy combines the effectivity of automated methods with human experience and judgment. This strategy is essential for creating dependable, correct, moral AI and ML methods.
HITL methods embody:
Iterative annotation: People annotate a small subset of knowledge, which is then used to coach an automatic system. The system’s output is reviewed and corrected by people, and the method repeats, progressively bettering the mannequin’s accuracy.
Lively studying: An clever system selects probably the most informative or difficult information samples for human annotation, optimizing using human effort.
Professional steerage: Area specialists present clarifications and guarantee annotations meet business requirements.
High quality management and suggestions: Common human overview and suggestions assist refine the automated annotation course of and deal with rising challenges.
Information annotation instruments
There are many information annotation instruments accessible out there. When deciding on one, be certain that you contemplate options intuitive person interface, multi-format help, collaborative annotation, high quality management mechanisms, AI-assisted annotation, scalability and efficiency, information safety and privateness, and integration and API help.
Prioritizing these options permits for the choice of an information annotation instrument that meets present wants and scales with future AI and ML initiatives.
A few of the main business instruments embody:
Amazon SageMaker Floor Reality: A totally managed information labeling service that makes use of machine studying to label information routinely.
Google Cloud Information Labeling Service: Affords a variety of annotation instruments for picture, video, and textual content information.
Labelbox: A collaborative platform supporting numerous information varieties and annotation duties.
Appen: Offers each handbook and automatic annotation providers throughout a number of information varieties.
SuperAnnotate: A complete platform providing AI-assisted annotation, collaboration options, and high quality management for numerous information varieties.
Encord: Finish-to-end answer for creating AI methods with superior annotation instruments and mannequin coaching capabilities.
Dataloop: AI-powered platform streamlining information administration, annotation, and mannequin coaching with customizable workflows.
Kili: Versatile labeling instrument with customizable interfaces, highly effective workflows, and high quality management options for numerous information varieties.
Nanonets: AI-based doc processing platform specializing in automating information extraction with customized OCR fashions and pre-built options.
Open-source options are additionally accessible, equivalent to:
CVAT (Pc Imaginative and prescient Annotation Software): An online-based instrument for annotating pictures and movies.
Doccano: A textual content annotation instrument supporting classification, sequence labeling, and named entity recognition.
LabelMe: A picture annotation instrument permitting customers to stipulate and label objects in pictures.
When selecting an information annotation instrument, contemplate elements equivalent to the kind of information you are working with, the size of your mission, your price range, and any particular necessities for integration along with your current methods.
Construct vs. purchase determination
Organizations should additionally resolve whether or not to construct their very own annotation instruments or buy current options. Constructing customized instruments affords full management over options and workflow however requires important time and assets. Shopping for current instruments is usually cheaper and permits for faster implementation however could require compromises on customization.
Information annotation for giant language fashions (LLMs)
Massive Language Fashions (LLMs) have revolutionized pure language processing, enabling extra refined and human-like interactions with AI methods. Creating and fine-tuning these fashions require huge quantities of high-quality, annotated information. On this part, we’ll discover the distinctive challenges and methods concerned in information annotation for LLMs.
Position of RLHF (Reinforcement Studying from Human Suggestions)
RLHF has emerged as a vital approach in bettering LLMs. This strategy goals to align the mannequin’s outputs with human preferences and values, making the AI system extra helpful and ethically aligned.
The RLHF course of includes:
Pre-training a language mannequin on a big corpus of textual content information.
Coaching a reward mannequin based mostly on human preferences.
Nice-tuning the language mannequin utilizing reinforcement studying with the reward mannequin.
Information annotation performs an important function within the second step, the place human annotators rank the language mannequin’s outcomes, offering suggestions within the type of sure/no approval or extra nuanced scores. This course of helps quantify human preferences, permitting the mannequin to be taught and align with human values and expectations.
Methods and greatest practices for annotating LLM information
If the info just isn’t annotated appropriately or persistently, it might trigger important points in mannequin efficiency and reliability. To make sure high-quality annotations for LLMs, contemplate the next greatest practices:
Various annotation groups: Guarantee annotators come from different backgrounds to cut back bias and enhance the mannequin’s skill to grasp completely different views and cultural contexts.
Clear pointers: Develop complete annotation pointers that cowl a variety of eventualities and edge instances to make sure consistency throughout annotators.
Iterative refinement: Usually overview and replace annotation pointers based mostly on rising patterns and challenges recognized through the annotation course of.
High quality management: Implement rigorous high quality assurance processes, together with cross-checking annotations and common efficiency evaluations of annotators.
Moral concerns: Be conscious of the potential biases and moral implications of annotated information, and try to create datasets that promote equity and inclusivity.
Contextual understanding: Encourage annotators to contemplate the broader context when evaluating responses, guaranteeing that annotations replicate nuanced understanding quite than surface-level judgments. This strategy helps LLMs develop a extra refined grasp of language and context.
These practices are serving to LLMs present important enhancements. These fashions at the moment are being utilized throughout numerous fields, together with chatbots, digital assistants, content material technology, sentiment evaluation, and language translation. As LLMs progress, it turns into more and more essential to make sure high-quality information annotation, which presents a problem in balancing large-scale annotation with nuanced, context-aware human judgment.
Information annotation in an enterprise context
For big organizations, information annotation is not only a process however a strategic crucial that underpins AI and machine studying initiatives. Enterprises face distinctive challenges and necessities when implementing information annotation at scale, necessitating a considerate strategy to instrument choice and course of implementation.
Scale and complexity: Enterprises face distinctive challenges with information annotation on account of their huge, numerous datasets. They want sturdy instruments that may deal with excessive volumes throughout numerous information varieties with out compromising efficiency. Options like lively studying, model-assisted labeling, and AI mannequin integration have gotten essential for managing advanced enterprise information successfully.
Customization and workflow integration: One-size-fits-all options not often meet enterprise wants. Organizations require extremely customizable annotation instruments that may adapt to particular workflows, ontologies, and information buildings. Seamless integration with current methods by means of well-documented APIs is essential, permitting enterprises to include annotation processes into their broader information and AI pipelines.
High quality management and consistency: To satisfy enterpise-level wants, you want superior high quality assurance options, together with automated checks, inter-annotator settlement metrics, and customizable overview workflows. These options guarantee consistency and reliability within the annotated information, which is crucial for coaching high-performance AI fashions.
Safety and compliance: Information safety is paramount for enterprises, particularly these in regulated industries. Annotation instruments should provide enterprise-grade safety features, together with encryption, entry controls, and audit trails. Compliance with laws like GDPR and HIPAA is non-negotiable, making instruments with built-in compliance options extremely engaging.
Implementing these methods can assist enterprises harness the ability of knowledge annotation to drive AI innovation and achieve a aggressive edge of their respective industries. Because the AI panorama evolves, corporations that excel in information annotation shall be higher positioned to leverage new applied sciences and reply to altering market calls for.
How one can do information annotation?
The objective of the info annotation course of ought to be not simply to label information, however to create precious, correct coaching units that allow AI methods to carry out at their greatest. Now every enterprise may have distinctive necessities for information annotation, however there are some basic steps that may information the method:
Step 1: Information assortment
Earlier than annotation begins, you might want to collect all related information, together with pictures, movies, audio recordings, or textual content information, in a single place. This step is essential as the standard and variety of your preliminary dataset will considerably impression the efficiency of your AI fashions.
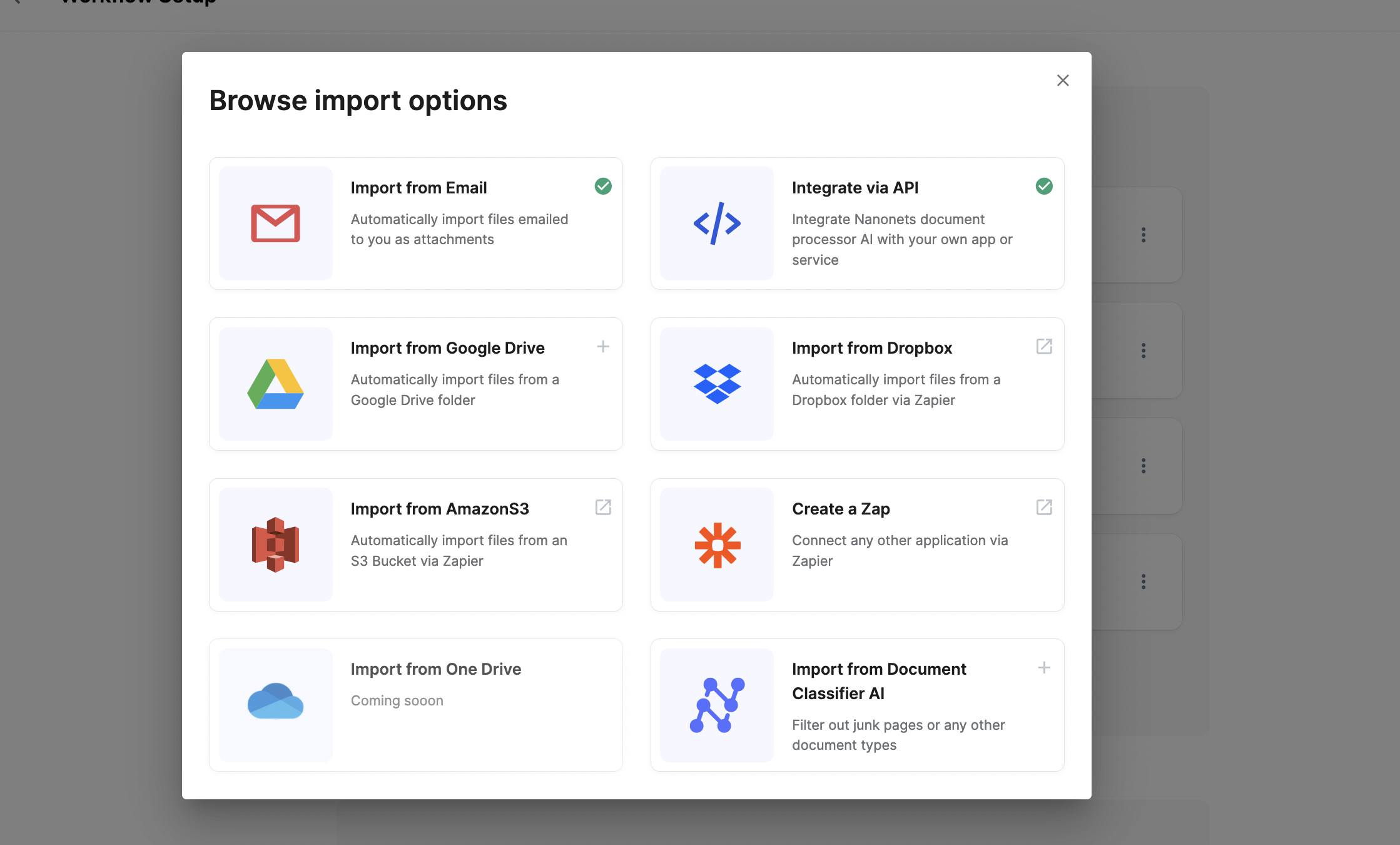
A platform like Nanonets can automate information assortment with information import choices.
Step 2: Information preprocessing
Preprocessing includes standardizing and enhancing the collected information. This step could embody:
Deskewing pictures
Enhancing information high quality
Formatting textual content
Transcribing video or audio content material
Eradicating duplicates or irrelevant information
Nanonets can automate information pre-processing with no-code workflows
Nanonets can automate information pre-processing with no-code workflows. You possibly can select from quite a lot of choices, equivalent to date formatting, information matching, and information verification.
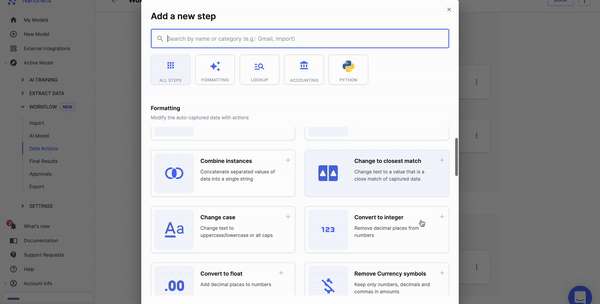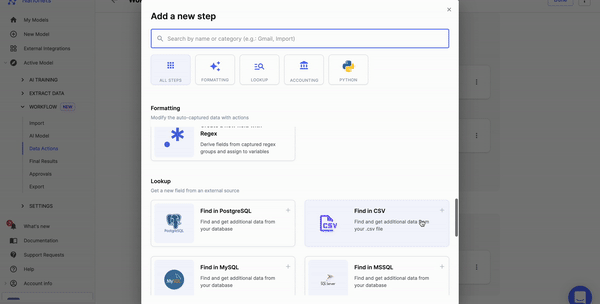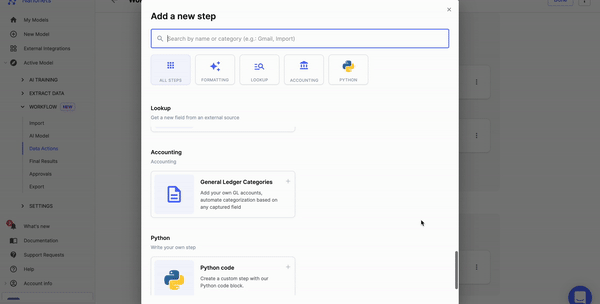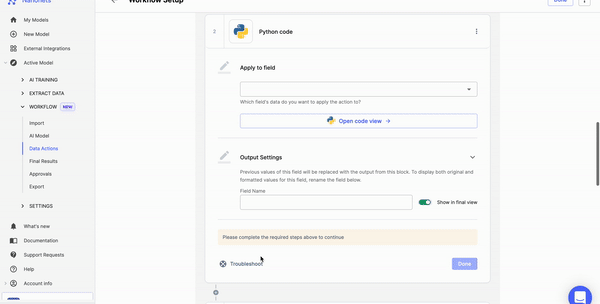
Step 3: Choose the info annotation instrument
Select an applicable annotation instrument based mostly in your particular necessities. Think about elements equivalent to the kind of information you are working with, the size of your mission, and any particular annotation options you want.
Listed here are some choices:
Information Annotation – Nanonets
Picture Annotation – V7
Video Annotation – Appen
Doc Annotation – Nanonets
Step 4: Set up annotation pointers
Develop clear, complete pointers for annotators or annotation instruments. These pointers ought to cowl:
Definitions of labels or classes
Examples of appropriate and incorrect annotations
Directions for dealing with edge instances or ambiguous information
Moral concerns, particularly when coping with doubtlessly delicate content material
Step 5: Annotation
After establishing pointers, the info could be labeled and tagged by human annotators or utilizing information annotation software program. Think about implementing a Human-in-the-Loop (HITL) strategy, which mixes the effectivity of automated methods with human experience and judgment.
Step 6: High quality management
High quality assurance is essential for sustaining excessive requirements. Implement a strong high quality management course of, which can embody:
A number of annotators reviewing the identical information
Professional overview of a pattern of annotations
Automated checks for frequent errors or inconsistencies
Common updates to annotation pointers based mostly on high quality management findings
You possibly can carry out a number of blind annotations to make sure that outcomes are correct.
Step 7: Information export
As soon as information annotation is full and has handed high quality checks, export it within the required format. You should utilize platforms like Nanonets to seamlessly export information within the format of your option to 5000+ enterprise software program.
Export information within the format of your option to 5000+ enterprise software program with Nanonets
The complete information annotation course of can take wherever from just a few days to a number of weeks, relying on the scale and complexity of the info and the assets accessible. It is essential to notice that information annotation is usually an iterative course of, with steady refinement based mostly on mannequin efficiency and evolving mission wants.
Actual-world examples and use instances
Current stories point out that GPT-4, developed by OpenAI, can precisely determine and label cell varieties. This was achieved by analyzing marker gene information in single-cell RNA sequencing. It simply goes to point out how highly effective AI fashions can turn out to be when educated on precisely annotated information.
In different industries, we see comparable developments of AI augmenting human annotation efforts:
Autonomous Automobiles: Firms are utilizing annotated video information to coach self-driving automobiles to acknowledge street components. Annotators label objects like pedestrians, site visitors indicators, and different automobiles in video frames. This course of trains AI methods to acknowledge and reply to street components.
Healthcare: Medical imaging annotation is rising in recognition for bettering diagnostic accuracy. Annotated datasets are used to coach AI fashions that may detect abnormalities in X-rays, MRIs, and CT scans. This software has the potential to reinforce early illness detection and enhance affected person outcomes.
Pure Language Processing: Annotators label textual content information to assist AI perceive context, intent, and sentiment. This course of enhances the power of chatbots and digital assistants to interact in additional pure and useful conversations.
Monetary providers: The monetary business makes use of information annotation to reinforce fraud detection capabilities. Specialists label transaction information to determine patterns related to fraudulent exercise. This helps practice AI fashions to detect and stop monetary fraud extra successfully.
These examples underscore the rising significance of high-quality annotated information throughout numerous industries. Nonetheless, as we embrace these technological developments, it is essential to deal with the moral challenges in information annotation practices, guaranteeing honest compensation for annotators and sustaining information privateness and safety.
Ultimate ideas
In the identical means information continues to evolve, information annotation procedures have gotten extra superior. Just some years in the past, merely labeling just a few factors on a face was sufficient to construct an AI prototype. Now, as many as twenty dots could be positioned on the lips alone.
As we glance to the longer term, we are able to count on much more exact and detailed annotation methods to emerge. These developments will possible result in AI fashions with unprecedented accuracy and capabilities. Nonetheless, this progress additionally brings new challenges, equivalent to the necessity for extra expert annotators and elevated computational assets.
In case you are looking out for a easy and dependable information annotation answer, contemplate exploring Nanonets. Schedule a demo to see how Nanonets can streamline your information annotation course of. Learn the way the platform automates information extraction from paperwork and annotates paperwork simply to automate any doc duties.