
In August, a hacker dumped 2.7 billion information information, together with Social Safety numbers, on a darkish internet discussion board, in one of many greatest breaches in historical past. Nationwide Public Knowledge, the proprietor of the information, has now acknowledged the incident, blaming a “third-party dangerous actor” that hacked the corporate in December 2023.
The background-checking service acknowledged the breach in a assertion posted on Aug. 12. It defined the way it has utilized “further safety measures” to guard itself towards future incidents; nevertheless, it recommends that these affected “take preventative measures” quite than providing any remediation.
Troy Hunt, safety professional and creator of the Have I Been Pwned breach checking service, investigated the leaked dataset and located it solely contained 134 million distinctive electronic mail addresses in addition to 70 million rows from a database of U.S. felony information. The e-mail addresses weren’t related to the SSNs.
Different information within the dataset embrace an individual’s title, mailing handle, and SSN, however some additionally comprise different delicate info, reminiscent of names of relations, in line with Bloomberg.
How the information was stolen
This breach is expounded to an incident from April 8, when a identified cybercriminal group named USDoD claimed to have entry to the non-public information of two.9 billion folks from the U.S., U.Okay., and Canada and was promoting the data for $3.5 million, in line with a class motion grievance. USDoD is assumed to have obtained the database from one other menace actor utilizing the alias “SXUL.”
This information was supposedly stolen from Nationwide Public Knowledge, often known as Jerico Footage, and the felony claimed it contained information for each individual within the three nations. On the time, the malware web site VX-Underground stated this information dump doesn’t comprise info on individuals who use information opt-out providers.
“Each one who used some type of information opt-out service was not current,” it posted on X.
SEE: Practically 10 Billion Passwords Leaked in Largest Compilation of All Time
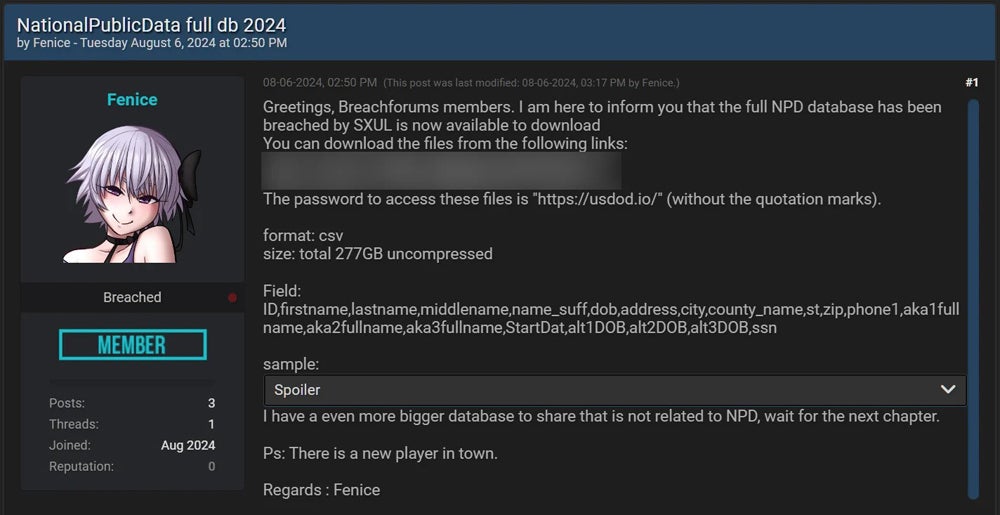
Numerous cybercriminals then posted completely different samples of this information, usually with completely different entries and containing telephone numbers and electronic mail addresses. Nevertheless it wasn’t till earlier this month {that a} person named “Fenice” leaked 2.7 billion unencrypted information on the darkish web page generally known as “Breached,” within the type of two csv information totaling 277 GB. These didn’t comprise telephone numbers and electronic mail addresses, and Fenice stated that the information originated from SXUL.
Nationwide Public Knowledge’s sister property might need supplied an entry level
In response to analysis by Krebs on Safety, hackers might need gained preliminary entry to the Nationwide Public Knowledge information through its sister property, RecordsCheck, one other background-checking service.
Up till August 19, “recordscheck.web” hosted an archive known as “members.zip” that included the supply code and plain textual content usernames and passwords for various elements of its web site, together with its administrator. The archive indicated that the entire web site’s customers got the identical six-character password by default, however many by no means bought round to altering it.
Moreover, recordscheck.web is “visually much like nationalpublicdata.com and options an identical login pages,” Krebs wrote. Nationwide Public Knowledge’s founder, Salvatore “Sal” Verini, later instructed Krebs that “members.zip” was “an outdated model of the location with non-working code and passwords” and that RecordsCheck will stop operations “within the subsequent week or so.”
In addition to the plaintext passwords, there’s different proof that RecordsCheck would have supplied a degree of entry into Verini’s properties. In response to Krebs, RecordsCheck pulled background checks on folks by querying the Nationwide Public Knowledge database and information at an information dealer known as USInfoSearch.com. In November, it was revealed that many USInfoSearch accounts have been hacked and are being exploited by cybercriminals.
Not all 2.7 billion leaked information are correct or distinctive, however a few of them are
As people will every have a number of information related to them, one for every of their earlier house addresses, the breach doesn’t expose details about 2.7 billion completely different folks. Moreover, in line with BleepingComputer, some impacted people have confirmed that the SSN related to their information within the information dump will not be right.
BleepingComputer additionally discovered that among the information don’t comprise the related particular person’s present handle, suggesting that no less than a portion of the data is old-fashioned. Nonetheless, others have confirmed that the information contained their and their relations’ reliable info, together with those that are deceased.
The category motion grievance added that Nationwide Public Knowledge scrapes the personally figuring out info of billions of people from personal sources to create their profiles. Which means these impacted could not have knowingly supplied their information. These dwelling within the U.S. are notably more likely to be impacted by this breach indirectly.
A number of web sites have been set as much as assist people examine if their info has been uncovered within the Nationwide Public Knowledge breach, together with npdpentester.com and npdbreach.com.
Specialists who TechRepublic spoke to recommend that people impacted by the breach ought to think about monitoring or freezing their credit score stories and stay on excessive alert for phishing campaigns concentrating on their electronic mail or telephone quantity.
Companies ought to guarantee any private information they maintain is encrypted and safely saved. They need to additionally implement different safety measures reminiscent of multi-factor authentication, password managers, safety audits, worker coaching, and threat-detection instruments.
SEE: Easy methods to Keep away from a Knowledge Breach
TechRepublic has reached out to Florida-based Nationwide Public Knowledge for a response. The corporate is at the moment underneath investigation by Schubert Jonckheer & Kolbe LLP.
Named plaintiff Christopher Hofmann stated he acquired a notification from his identity-theft safety service supplier on July 24 notifying him that his private info had been compromised as a direct results of the “nationalpublicdata.com” breach and had been printed on the darkish internet.
What safety specialists are saying in regards to the breach
Why are the Nationwide Public Knowledge information so useful to cybercriminals?
Jon Miller, CEO and co-founder of anti-ransomware platform Halcyon, stated that the worth of the Nationwide Public Knowledge information from a felony’s perspective comes from the truth that they’ve been collected and arranged.
He instructed TechRepublic in an electronic mail, “Whereas the data is essentially already obtainable to attackers, they might have needed to go to nice lengths at nice expense to place collectively the same assortment of information, so basically NPD simply did them a favor by making it simpler.”
SEE: How organizations ought to deal with information breaches
Oren Koren, CPO and co-founder at safety platform Veriti, added that details about deceased people might be reused for nefarious functions. He instructed TechRepublic in an electronic mail, “With this ‘place to begin,’ a person can attempt to create delivery certificates, voting certificates, and so on., that will probably be legitimate because of the truth they’ve among the information they want, with crucial one being the social safety quantity.”
How can information aggregator breaches be stopped?
Paul Bischoff, shopper privateness advocate at tech analysis agency Comparitech, instructed TechRepublic in an electronic mail, “Background examine firms like Nationwide Public Knowledge are basically information brokers who gather as a lot identifiable info as potential about everybody they’ll, then promote it to whomever pays for it. It collects a lot of the information with out the information or consent of information topics, most of whom don’t know what Nationwide Public Knowledge is or does.
“We want stronger rules and extra transparency for information brokers that require them to tell information topics when their information is added to a database, restrict internet scraping, and permit information topics to see, modify, and delete information.
“Nationwide Public Knowledge and different information brokers ought to be required to indicate information topics the place their information initially got here from so that individuals can take proactive steps to safe their privateness on the supply. Moreover, there is no such thing as a cause the compromised information shouldn’t have been encrypted.”
Miller added, “The monetization of our private info — together with the data we select to show about ourselves publicly — is way forward of authorized protections that govern who can gather what, how it may be used, and most significantly, what their duty is in defending it.”
Can companies and people forestall themselves from changing into victims of an information breach?
Chris Deibler, VP of safety at safety options supplier DataGrail, stated lots of the cyber hygiene ideas obtainable for companies and people wouldn’t have helped a lot on this occasion.
He instructed TechRepublic in an electronic mail, “We’re reaching the bounds of what people can moderately do to guard themselves on this atmosphere, and the true options want to return on the company and regulatory stage, up by means of and together with a normalization of information privateness regulation through worldwide treaty.
“The steadiness of energy proper now will not be within the particular person’s favor. GDPR and the varied state and nationwide rules coming on-line are good steps, however the prevention and consequence fashions in place right this moment clearly don’t disincentivize mass aggregation of information.”























