
In a latest undertaking, we had been tasked with designing how we’d exchange a
Mainframe system with a cloud native utility, constructing a roadmap and a
enterprise case to safe funding for the multi-year modernisation effort
required. We had been cautious of the dangers and potential pitfalls of a Large Design
Up Entrance, so we suggested our consumer to work on a ‘simply sufficient, and simply in
time’ upfront design, with engineering through the first part. Our consumer
appreciated our strategy and chosen us as their accomplice.
The system was constructed for a UK-based consumer’s Knowledge Platform and
customer-facing merchandise. This was a really complicated and difficult process given
the scale of the Mainframe, which had been constructed over 40 years, with a
number of applied sciences which have considerably modified since they had been
first launched.
Our strategy relies on incrementally transferring capabilities from the
mainframe to the cloud, permitting a gradual legacy displacement fairly than a
“Large Bang” cutover. With a purpose to do that we wanted to establish locations within the
mainframe design the place we may create seams: locations the place we will insert new
habits with the smallest potential adjustments to the mainframe’s code. We will
then use these seams to create duplicate capabilities on the cloud, twin run
them with the mainframe to confirm their habits, after which retire the
mainframe functionality.
Thoughtworks had been concerned for the primary 12 months of the programme, after which we handed over our work to our consumer
to take it ahead. In that timeframe, we didn’t put our work into manufacturing, however, we trialled a number of
approaches that may assist you get began extra rapidly and ease your personal Mainframe modernisation journeys. This
article supplies an outline of the context wherein we labored, and descriptions the strategy we adopted for
incrementally transferring capabilities off the Mainframe.
Contextual Background
The Mainframe hosted a various vary of
companies essential to the consumer’s enterprise operations. Our programme
particularly targeted on the info platform designed for insights on Customers
in UK&I (United Kingdom & Eire). This explicit subsystem on the
Mainframe comprised roughly 7 million traces of code, developed over a
span of 40 years. It offered roughly ~50% of the capabilities of the UK&I
property, however accounted for ~80% of MIPS (Million directions per second)
from a runtime perspective. The system was considerably complicated, the
complexity was additional exacerbated by area tasks and issues
unfold throughout a number of layers of the legacy setting.
A number of causes drove the consumer’s resolution to transition away from the
Mainframe setting, these are the next:
- Modifications to the system had been sluggish and costly. The enterprise due to this fact had
challenges preserving tempo with the quickly evolving market, stopping
innovation. - Operational prices related to operating the Mainframe system had been excessive;
the consumer confronted a industrial threat with an imminent value improve from a core
software program vendor. - While our consumer had the required ability units for operating the Mainframe,
it had confirmed to be onerous to seek out new professionals with experience on this tech
stack, because the pool of expert engineers on this area is restricted. Moreover,
the job market doesn’t provide as many alternatives for Mainframes, thus folks
usually are not incentivised to discover ways to develop and function them.
Excessive-level view of Shopper Subsystem
The next diagram reveals, from a high-level perspective, the assorted
parts and actors within the Shopper subsystem.

The Mainframe supported two distinct sorts of workloads: batch
processing and, for the product API layers, on-line transactions. The batch
workloads resembled what is usually known as a knowledge pipeline. They
concerned the ingestion of semi-structured information from exterior
suppliers/sources, or different inner Mainframe methods, adopted by information
cleaning and modelling to align with the necessities of the Shopper
Subsystem. These pipelines integrated numerous complexities, together with
the implementation of the Identification looking out logic: in the UK,
not like the US with its social safety quantity, there is no such thing as a
universally distinctive identifier for residents. Consequently, firms
working within the UK&I have to make use of customised algorithms to precisely
decide the person identities related to that information.
The net workload additionally introduced important complexities. The
orchestration of API requests was managed by a number of internally developed
frameworks, which decided this system execution circulation by lookups in
datastores, alongside dealing with conditional branches by analysing the
output of the code. We must always not overlook the extent of customisation this
framework utilized for every buyer. For instance, some flows had been
orchestrated with ad-hoc configuration, catering for implementation
particulars or particular wants of the methods interacting with our consumer’s
on-line merchandise. These configurations had been distinctive at first, however they
seemingly grew to become the norm over time, as our consumer augmented their on-line
choices.
This was applied by way of an Entitlements engine which operated
throughout layers to make sure that clients accessing merchandise and underlying
information had been authenticated and authorised to retrieve both uncooked or
aggregated information, which might then be uncovered to them by way of an API
response.
Incremental Legacy Displacement: Rules, Advantages, and
Concerns
Contemplating the scope, dangers, and complexity of the Shopper Subsystem,
we believed the next rules can be tightly linked with us
succeeding with the programme:
- Early Threat Discount: With engineering ranging from the
starting, the implementation of a “Fail-Quick” strategy would assist us
establish potential pitfalls and uncertainties early, thus stopping
delays from a programme supply standpoint. These had been: - Final result Parity: The consumer emphasised the significance of
upholding final result parity between the present legacy system and the
new system (You will need to word that this idea differs from
Function Parity). Within the consumer’s Legacy system, numerous
attributes had been generated for every shopper, and given the strict
business rules, sustaining continuity was important to make sure
contractual compliance. We would have liked to proactively establish
discrepancies in information early on, promptly handle or clarify them, and
set up belief and confidence with each our consumer and their
respective clients at an early stage. - Cross-functional necessities: The Mainframe is a extremely
performant machine, and there have been uncertainties {that a} answer on
the Cloud would fulfill the Cross-functional necessities. - Ship Worth Early: Collaboration with the consumer would
guarantee we may establish a subset of essentially the most crucial Enterprise
Capabilities we may ship early, guaranteeing we may break the system
aside into smaller increments. These represented thin-slices of the
general system. Our purpose was to construct upon these slices iteratively and
often, serving to us speed up our general studying within the area.
Moreover, working by way of a thin-slice helps cut back the cognitive
load required from the group, thus stopping evaluation paralysis and
guaranteeing worth can be constantly delivered. To realize this, a
platform constructed across the Mainframe that gives higher management over
shoppers’ migration methods performs an important position. Utilizing patterns akin to
Darkish Launching and Canary
Launch would place us within the driver’s seat for a easy
transition to the Cloud. Our purpose was to realize a silent migration
course of, the place clients would seamlessly transition between methods
with none noticeable impression. This might solely be potential by way of
complete comparability testing and steady monitoring of outputs
from each methods.
With the above rules and necessities in thoughts, we opted for an
Incremental Legacy Displacement strategy at the side of Twin
Run. Successfully, for every slice of the system we had been rebuilding on the
Cloud, we had been planning to feed each the brand new and as-is system with the
identical inputs and run them in parallel. This permits us to extract each
methods’ outputs and verify if they’re the identical, or not less than inside an
acceptable tolerance. On this context, we outlined Incremental Twin
Run as: utilizing a Transitional
Structure to help slice-by-slice displacement of functionality
away from a legacy setting, thereby enabling goal and as-is methods
to run quickly in parallel and ship worth.
We determined to undertake this architectural sample to strike a stability
between delivering worth, discovering and managing dangers early on,
guaranteeing final result parity, and sustaining a easy transition for our
consumer all through the length of the programme.
Incremental Legacy Displacement strategy
To perform the offloading of capabilities to our goal
structure, the group labored intently with Mainframe SMEs (Topic Matter
Specialists) and our consumer’s engineers. This collaboration facilitated a
simply sufficient understanding of the present as-is panorama, when it comes to each
technical and enterprise capabilities; it helped us design a Transitional
Structure to attach the present Mainframe to the Cloud-based system,
the latter being developed by different supply workstreams within the
programme.
Our strategy started with the decomposition of the
Shopper subsystem into particular enterprise and technical domains, together with
information load, information retrieval & aggregation, and the product layer
accessible by way of external-facing APIs.
Due to our consumer’s enterprise
goal, we recognised early that we may exploit a serious technical boundary to organise our programme. The
consumer’s workload was largely analytical, processing largely exterior information
to provide perception which was offered on to shoppers. We due to this fact noticed an
alternative to separate our transformation programme in two elements, one round
information curation, the opposite round information serving and product use instances utilizing
information interactions as a seam. This was the primary excessive degree seam recognized.
Following that, we then wanted to additional break down the programme into
smaller increments.
On the info curation aspect, we recognized that the info units had been
managed largely independently of one another; that’s, whereas there have been
upstream and downstream dependencies, there was no entanglement of the datasets throughout curation, i.e.
ingested information units had a one to at least one mapping to their enter information.
.
We then collaborated intently with SMEs to establish the seams
inside the technical implementation (laid out beneath) to plan how we may
ship a cloud migration for any given information set, ultimately to the extent
the place they could possibly be delivered in any order (Database Writers Processing Pipeline Seam, Coarse Seam: Batch Pipeline Step Handoff as Seam,
and Most Granular: Knowledge Attribute
Seam). So long as up- and downstream dependencies may trade information
from the brand new cloud system, these workloads could possibly be modernised
independently of one another.
On the serving and product aspect, we discovered that any given product used
80% of the capabilities and information units that our consumer had created. We
wanted to discover a totally different strategy. After investigation of the way in which entry
was offered to clients, we discovered that we may take a “buyer section”
strategy to ship the work incrementally. This entailed discovering an
preliminary subset of shoppers who had bought a smaller proportion of the
capabilities and information, lowering the scope and time wanted to ship the
first increment. Subsequent increments would construct on prime of prior work,
enabling additional buyer segments to be minimize over from the as-is to the
goal structure. This required utilizing a unique set of seams and
transitional structure, which we focus on in Database Readers and Downstream processing as a Seam.
Successfully, we ran an intensive evaluation of the parts that, from a
enterprise perspective, functioned as a cohesive entire however had been constructed as
distinct parts that could possibly be migrated independently to the Cloud and
laid this out as a programme of sequenced increments.
Seams
Our transitional structure was largely influenced by the Legacy seams we may uncover inside the Mainframe. You
can consider them because the junction factors the place code, packages, or modules
meet. In a legacy system, they could have been deliberately designed at
strategic locations for higher modularity, extensibility, and
maintainability. If that is so, they may seemingly stand out
all through the code, though when a system has been beneath growth for
a variety of many years, these seams have a tendency to cover themselves amongst the
complexity of the code. Seams are significantly useful as a result of they will
be employed strategically to change the behaviour of purposes, for
instance to intercept information flows inside the Mainframe permitting for
capabilities to be offloaded to a brand new system.
Figuring out technical seams and useful supply increments was a
symbiotic course of; potentialities within the technical space fed the choices
that we may use to plan increments, which in flip drove the transitional
structure wanted to help the programme. Right here, we step a degree decrease
in technical element to debate options we deliberate and designed to allow
Incremental Legacy Displacement for our consumer. You will need to word that these had been constantly refined
all through our engagement as we acquired extra data; some went so far as being deployed to check
environments, while others had been spikes. As we undertake this strategy on different large-scale Mainframe modernisation
programmes, these approaches can be additional refined with our hottest hands-on expertise.
Exterior interfaces
We examined the exterior interfaces uncovered by the Mainframe to information
Suppliers and our consumer’s Prospects. We may apply Occasion Interception on these integration factors
to permit the transition of external-facing workload to the cloud, so the
migration can be silent from their perspective. There have been two varieties
of interfaces into the Mainframe: a file-based switch for Suppliers to
provide information to our consumer, and a web-based set of APIs for Prospects to
work together with the product layer.
Batch enter as seam
The primary exterior seam that we discovered was the file-transfer
service.
Suppliers may switch information containing information in a semi-structured
format through two routes: a web-based GUI (Graphical Person Interface) for
file uploads interacting with the underlying file switch service, or
an FTP-based file switch to the service immediately for programmatic
entry.
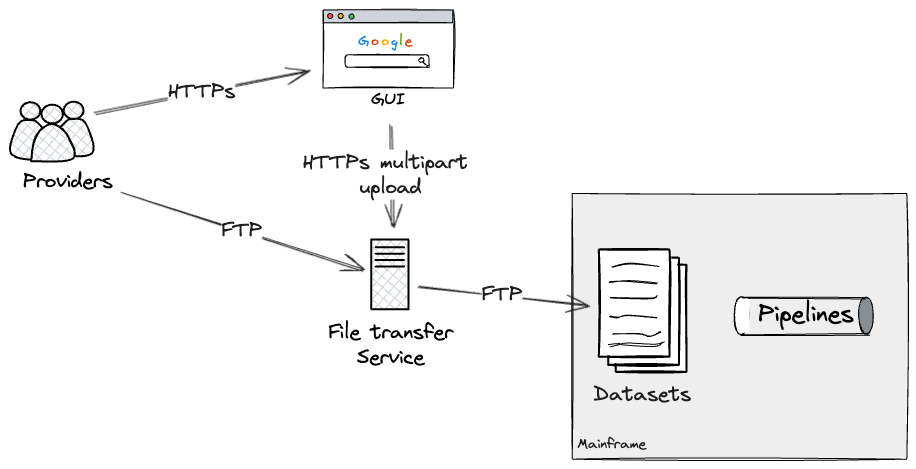
The file switch service decided, on a per supplier and file
foundation, what datasets on the Mainframe needs to be up to date. These would
in flip execute the related pipelines by way of dataset triggers, which
had been configured on the batch job scheduler.
Assuming we may rebuild every pipeline as an entire on the Cloud
(word that later we are going to dive deeper into breaking down bigger
pipelines into workable chunks), our strategy was to construct an
particular person pipeline on the cloud, and twin run it with the mainframe
to confirm they had been producing the identical outputs. In our case, this was
potential by way of making use of extra configurations on the File
switch service, which forked uploads to each Mainframe and Cloud. We
had been capable of check this strategy utilizing a production-like File switch
service, however with dummy information, operating on check environments.
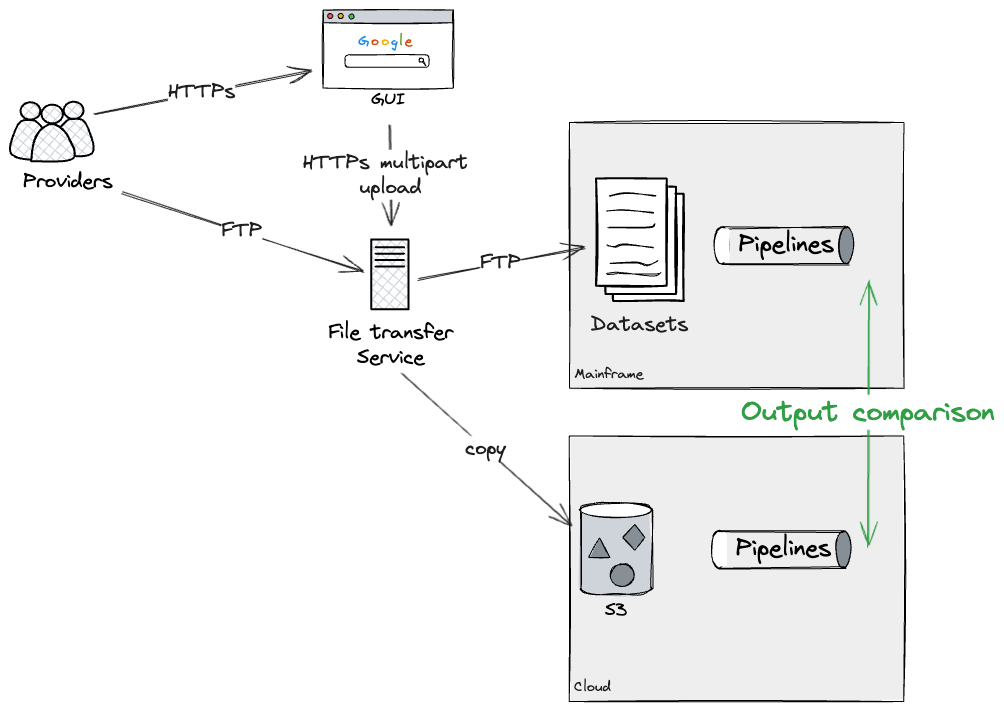
This may enable us to Twin Run every pipeline each on Cloud and
Mainframe, for so long as required, to realize confidence that there have been
no discrepancies. Ultimately, our strategy would have been to use an
extra configuration to the File switch service, stopping
additional updates to the Mainframe datasets, due to this fact leaving as-is
pipelines deprecated. We didn’t get to check this final step ourselves
as we didn’t full the rebuild of a pipeline finish to finish, however our
technical SMEs had been aware of the configurations required on the
File switch service to successfully deprecate a Mainframe
pipeline.
API Entry as Seam
Moreover, we adopted the same technique for the exterior going through
APIs, figuring out a seam across the pre-existing API Gateway uncovered
to Prospects, representing their entrypoint to the Shopper
Subsystem.
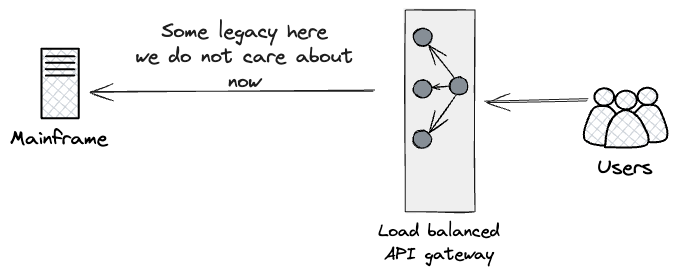
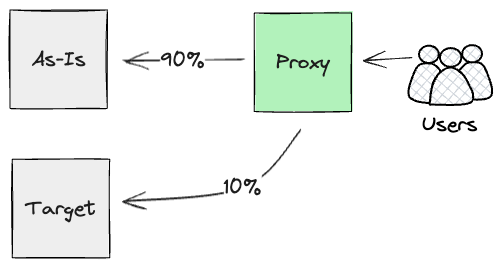
Drawing from Twin Run, the strategy we designed can be to place a
proxy excessive up the chain of HTTPS calls, as near customers as potential.
We had been on the lookout for one thing that would parallel run each streams of
calls (the As-Is mainframe and newly constructed APIs on Cloud), and report
again on their outcomes.

Successfully, we had been planning to make use of Darkish
Launching for the brand new Product layer, to realize early confidence
within the artefact by way of in depth and steady monitoring of their
outputs. We didn’t prioritise constructing this proxy within the first 12 months;
to take advantage of its worth, we wanted to have nearly all of performance
rebuilt on the product degree. Nevertheless, our intentions had been to construct it
as quickly as any significant comparability checks could possibly be run on the API
layer, as this part would play a key position for orchestrating darkish
launch comparability checks. Moreover, our evaluation highlighted we
wanted to be careful for any side-effects generated by the Merchandise
layer. In our case, the Mainframe produced uncomfortable side effects, akin to
billing occasions. Because of this, we’d have wanted to make intrusive
Mainframe code adjustments to stop duplication and make sure that
clients wouldn’t get billed twice.
Equally to the Batch enter seam, we may run these requests in
parallel for so long as it was required. Finally although, we’d
use Canary
Launch on the
proxy layer to chop over customer-by-customer to the Cloud, therefore
lowering, incrementally, the workload executed on the Mainframe.
Inside interfaces
Following that, we performed an evaluation of the interior parts
inside the Mainframe to pinpoint the particular seams we may leverage to
migrate extra granular capabilities to the Cloud.
Coarse Seam: Knowledge interactions as a Seam
One of many main areas of focus was the pervasive database
accesses throughout packages. Right here, we began our evaluation by figuring out
the packages that had been both writing, studying, or doing each with the
database. Treating the database itself as a seam allowed us to interrupt
aside flows that relied on it being the connection between
packages.
Database Readers
Concerning Database readers, to allow new Knowledge API growth in
the Cloud setting, each the Mainframe and the Cloud system wanted
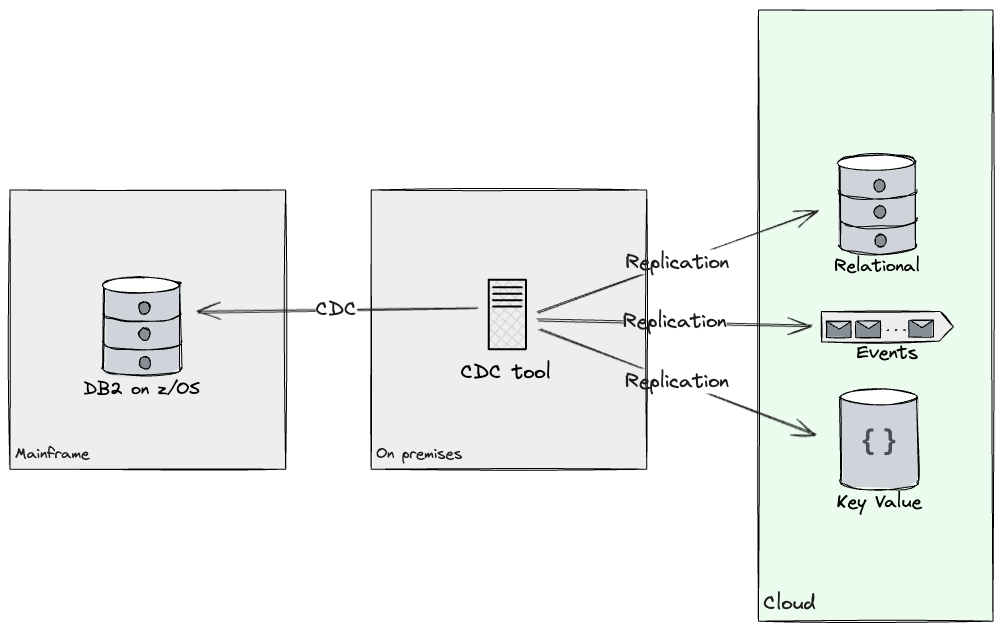
entry to the identical information. We analysed the database tables accessed by
the product we picked as a primary candidate for migrating the primary
buyer section, and labored with consumer groups to ship a knowledge
replication answer. This replicated the required tables from the check database to the Cloud utilizing Change
Knowledge Seize (CDC) methods to synchronise sources to targets. By
leveraging a CDC software, we had been capable of replicate the required
subset of information in a near-real time vogue throughout goal shops on
Cloud. Additionally, replicating information gave us alternatives to revamp its
mannequin, as our consumer would now have entry to shops that weren’t
solely relational (e.g. Doc shops, Occasions, Key-Worth and Graphs
had been thought of). Criterias akin to entry patterns, question complexity,
and schema flexibility helped decide, for every subset of information, what
tech stack to copy into. In the course of the first 12 months, we constructed
replication streams from DB2 to each Kafka and Postgres.
At this level, capabilities applied by way of packages
studying from the database could possibly be rebuilt and later migrated to
the Cloud, incrementally.
Database Writers
With regard to database writers, which had been largely made up of batch
workloads operating on the Mainframe, after cautious evaluation of the info
flowing by way of and out of them, we had been capable of apply Extract Product Strains to establish
separate domains that would execute independently of one another
(operating as a part of the identical circulation was simply an implementation element we
may change).
Working with such atomic models, and round their respective seams,
allowed different workstreams to start out rebuilding a few of these pipelines
on the cloud and evaluating the outputs with the Mainframe.

Along with constructing the transitional structure, our group was
answerable for offering a variety of companies that had been utilized by different
workstreams to engineer their information pipelines and merchandise. On this
particular case, we constructed batch jobs on Mainframe, executed
programmatically by dropping a file within the file switch service, that
would extract and format the journals that these pipelines had been
producing on the Mainframe, thus permitting our colleagues to have tight
suggestions loops on their work by way of automated comparability testing.
After guaranteeing that outcomes remained the identical, our strategy for the
future would have been to allow different groups to cutover every
sub-pipeline one after the other.
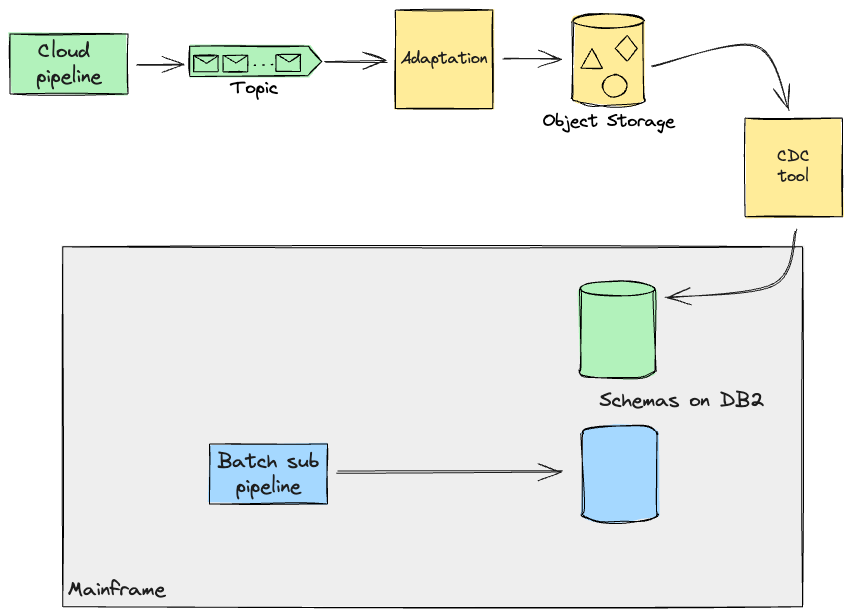
The artefacts produced by a sub-pipeline could also be required on the
Mainframe for additional processing (e.g. On-line transactions). Thus, the
strategy we opted for, when these pipelines would later be full
and on the Cloud, was to make use of Legacy Mimic
and replicate information again to the Mainframe, for so long as the potential dependant on this information can be
moved to Cloud too. To realize this, we had been contemplating using the identical CDC software for replication to the
Cloud. On this situation, data processed on Cloud can be saved as occasions on a stream. Having the
Mainframe devour this stream immediately appeared complicated, each to construct and to check the system for regressions,
and it demanded a extra invasive strategy on the legacy code. With a purpose to mitigate this threat, we designed an
adaption layer that will remodel the info again into the format the Mainframe may work with, as if that
information had been produced by the Mainframe itself. These transformation capabilities, if
simple, could also be supported by your chosen replication software, however
in our case we assumed we wanted customized software program to be constructed alongside
the replication software to cater for added necessities from the
Cloud. It is a frequent situation we see wherein companies take the
alternative, coming from rebuilding present processing from scratch,
to enhance them (e.g. by making them extra environment friendly).
In abstract, working intently with SMEs from the client-side helped
us problem the present implementation of Batch workloads on the
Mainframe, and work out various discrete pipelines with clearer
information boundaries. Be aware that the pipelines we had been coping with didn’t
overlap on the identical data, because of the boundaries we had outlined with
the SMEs. In a later part, we are going to look at extra complicated instances that
we’ve needed to cope with.
Coarse Seam: Batch Pipeline Step Handoff
Possible, the database gained’t be the one seam you’ll be able to work with. In
our case, we had information pipelines that, along with persisting their
outputs on the database, had been serving curated information to downstream
pipelines for additional processing.
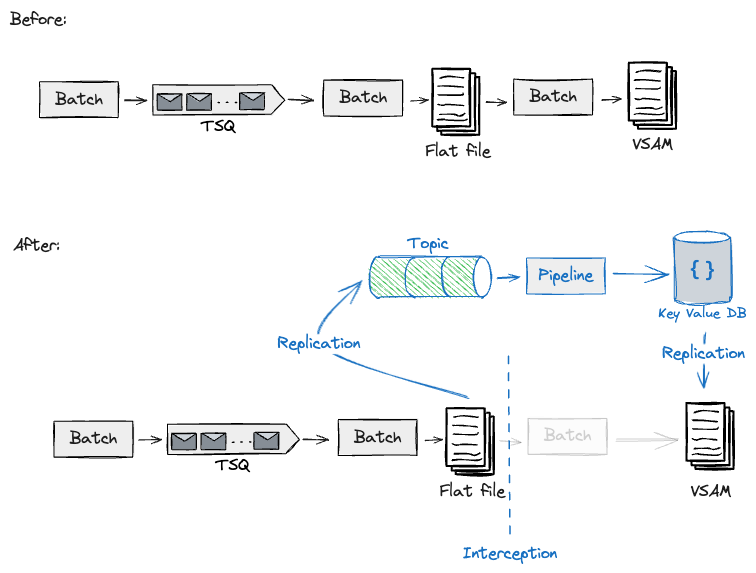
For these situations, we first recognized the handshakes between
pipelines. These consist normally of state persevered in flat / VSAM
(Digital Storage Entry Methodology) information, or probably TSQs (Momentary
Storage Queues). The next reveals these hand-offs between pipeline
steps.

For instance, we had been designs for migrating a downstream pipeline studying a curated flat file
saved upstream. This downstream pipeline on the Mainframe produced a VSAM file that will be queried by
on-line transactions. As we had been planning to construct this event-driven pipeline on the Cloud, we selected to
leverage the CDC software to get this information off the mainframe, which in flip would get transformed right into a stream of
occasions for the Cloud information pipelines to devour. Equally to what we’ve reported earlier than, our Transitional
Structure wanted to make use of an Adaptation layer (e.g. Schema translation) and the CDC software to repeat the
artefacts produced on Cloud again to the Mainframe.
Via using these handshakes that we had beforehand
recognized, we had been capable of construct and check this interception for one
exemplary pipeline, and design additional migrations of
upstream/downstream pipelines on the Cloud with the identical strategy,
utilizing Legacy
Mimic
to feed again the Mainframe with the required information to proceed with
downstream processing. Adjoining to those handshakes, we had been making
non-trivial adjustments to the Mainframe to permit information to be extracted and
fed again. Nevertheless, we had been nonetheless minimising dangers by reusing the identical
batch workloads on the core with totally different job triggers on the edges.
Granular Seam: Knowledge Attribute
In some instances the above approaches for inner seam findings and
transition methods don’t suffice, because it occurred with our undertaking
because of the measurement of the workload that we had been trying to cutover, thus
translating into greater dangers for the enterprise. In one in all our
situations, we had been working with a discrete module feeding off the info
load pipelines: Identification curation.
Shopper Identification curation was a
complicated area, and in our case it was a differentiator for our consumer;
thus, they might not afford to have an final result from the brand new system
much less correct than the Mainframe for the UK&I inhabitants. To
efficiently migrate the whole module to the Cloud, we would want to
construct tens of id search guidelines and their required database
operations. Due to this fact, we wanted to interrupt this down additional to maintain
adjustments small, and allow delivering often to maintain dangers low.
We labored intently with the SMEs and Engineering groups with the goal
to establish traits within the information and guidelines, and use them as
seams, that will enable us to incrementally cutover this module to the
Cloud. Upon evaluation, we categorised these guidelines into two distinct
teams: Easy and Advanced.
Easy guidelines may run on each methods, offered
they consumed totally different information segments (i.e. separate pipelines
upstream), thus they represented a possibility to additional break aside
the id module area. They represented the bulk (circa 70%)
triggered through the ingestion of a file. These guidelines had been accountable
for establishing an affiliation between an already present id,
and a brand new information document.
However, the Advanced guidelines had been triggered by instances the place
a knowledge document indicated the necessity for an id change, akin to
creation, deletion, or updation. These guidelines required cautious dealing with
and couldn’t be migrated incrementally. It’s because an replace to
an id will be triggered by a number of information segments, and working
these guidelines in each methods in parallel may result in id drift
and information high quality loss. They required a single system minting
identities at one time limit, thus we designed for an enormous bang
migration strategy.
In our unique understanding of the Identification module on the
Mainframe, pipelines ingesting information triggered adjustments on DB2 ensuing
in an updated view of the identities, information data, and their
associations.
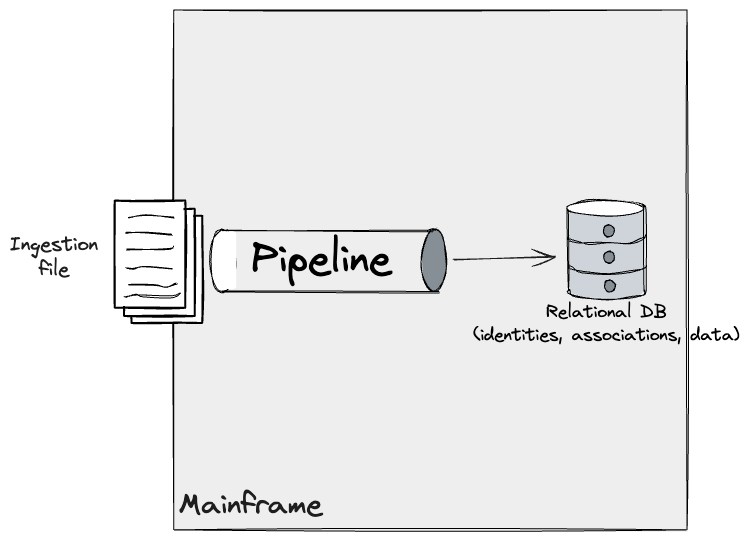
Moreover, we recognized a discrete Identification module and refined
this mannequin to replicate a deeper understanding of the system that we had
found with the SMEs. This module fed information from a number of information
pipelines, and utilized Easy and Advanced guidelines to DB2.
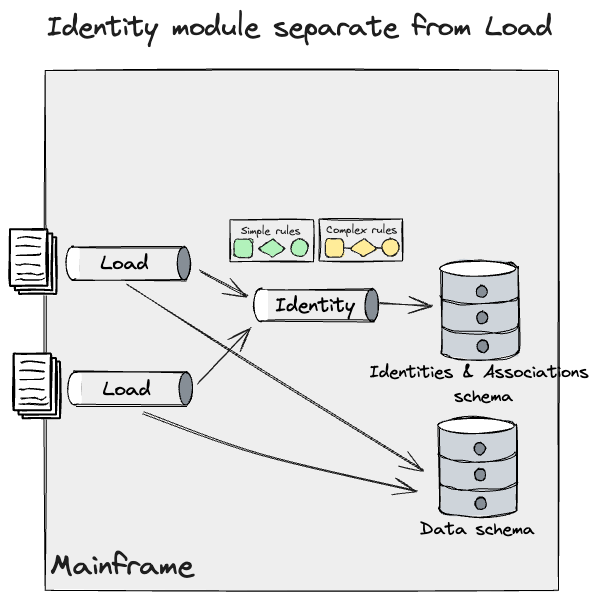
Now, we may apply the identical methods we wrote about earlier for
information pipelines, however we required a extra granular and incremental
strategy for the Identification one.
We deliberate to sort out the Easy guidelines that would run on each
methods, with a caveat that they operated on totally different information segments,
as we had been constrained to having just one system sustaining id
information. We labored on a design that used Batch Pipeline Step Handoff and
utilized Occasion Interception to seize and fork the info (quickly
till we will verify that no information is misplaced between system handoffs)
feeding the Identification pipeline on the Mainframe. This may enable us to
take a divide and conquer strategy with the information ingested, operating a
parallel workload on the Cloud which might execute the Easy guidelines
and apply adjustments to identities on the Mainframe, and construct it
incrementally. There have been many guidelines that fell beneath the Easy
bucket, due to this fact we wanted a functionality on the goal Identification module
to fall again to the Mainframe in case a rule which was not but
applied wanted to be triggered. This regarded just like the
following:
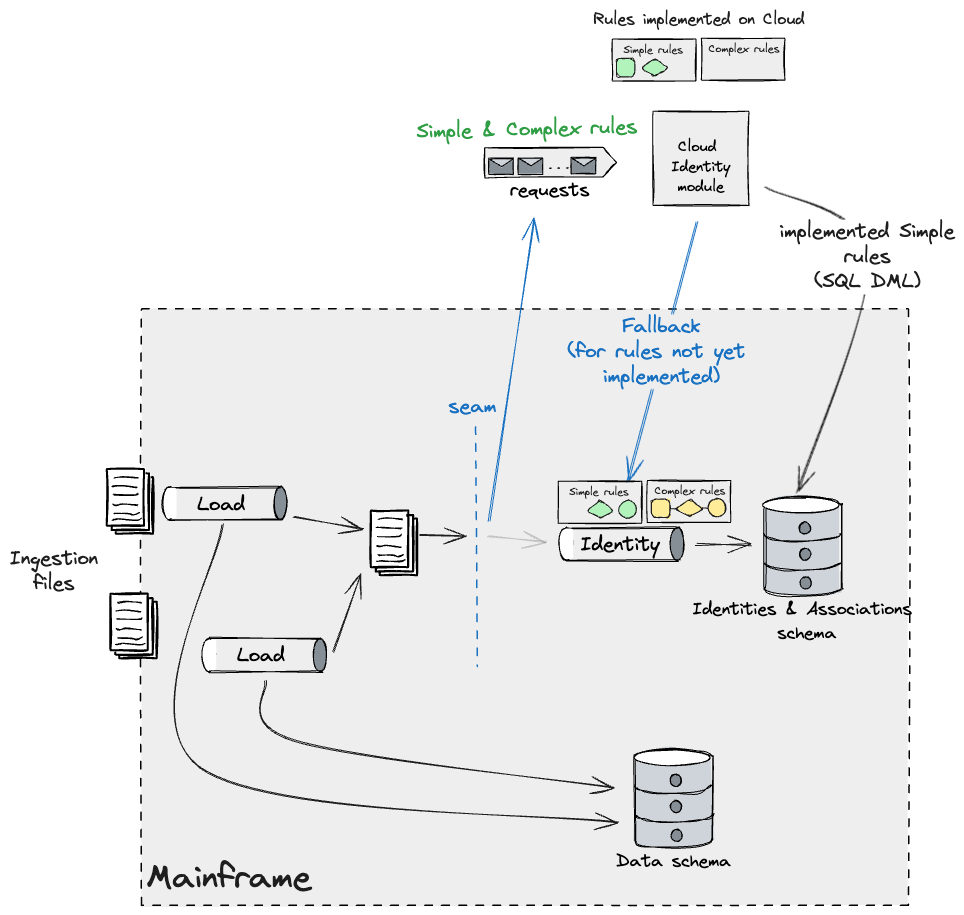
As new builds of the Cloud Identification module get launched, we’d
see much less guidelines belonging to the Easy bucket being utilized by way of
the fallback mechanism. Ultimately solely the Advanced ones can be
observable by way of that leg. As we beforehand talked about, these wanted
to be migrated multi functional go to minimise the impression of id drift.
Our plan was to construct Advanced guidelines incrementally in opposition to a Cloud
database reproduction and validate their outcomes by way of in depth
comparability testing.
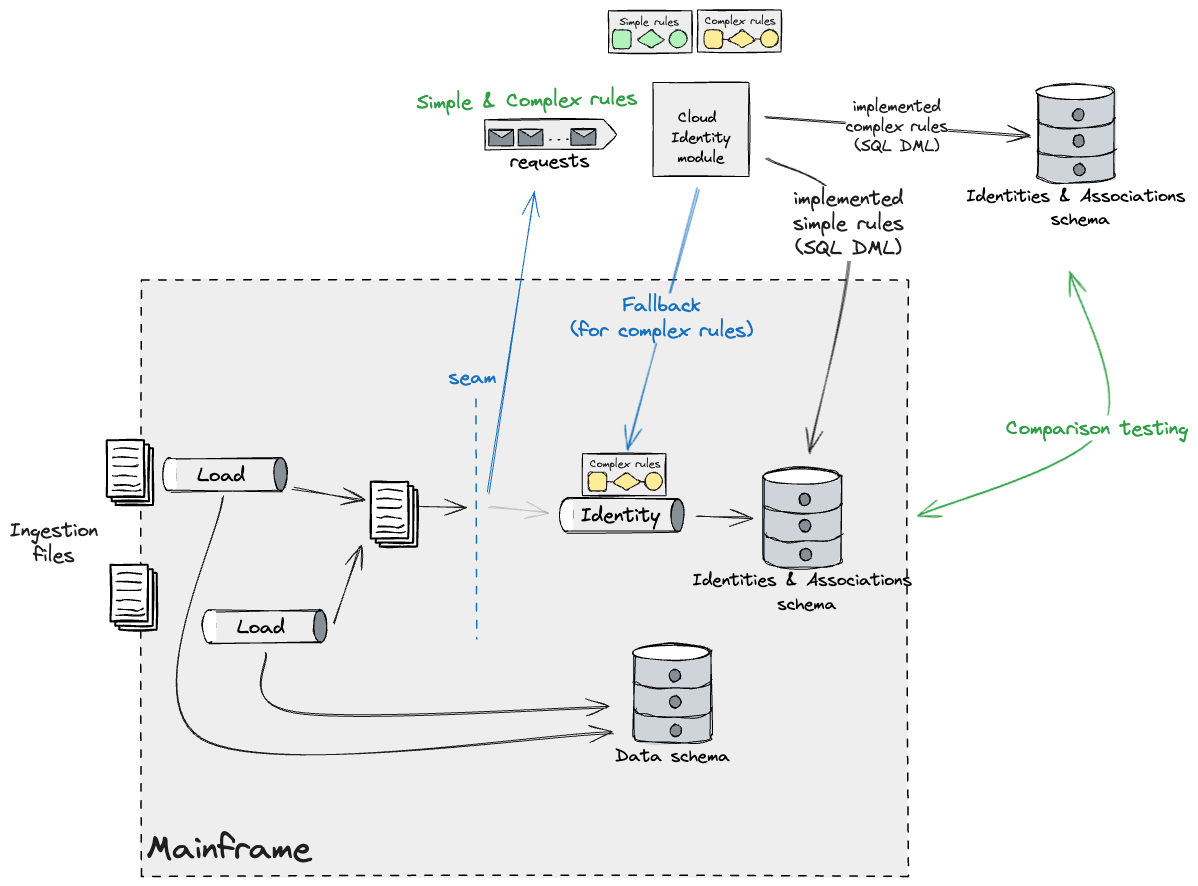
As soon as all guidelines had been constructed, we’d launch this code and disable
the fallback technique to the Mainframe. Keep in mind that upon
releasing this, the Mainframe Identities and Associations information turns into
successfully a reproduction of the brand new Main retailer managed by the Cloud
Identification module. Due to this fact, replication is required to maintain the
mainframe functioning as is.
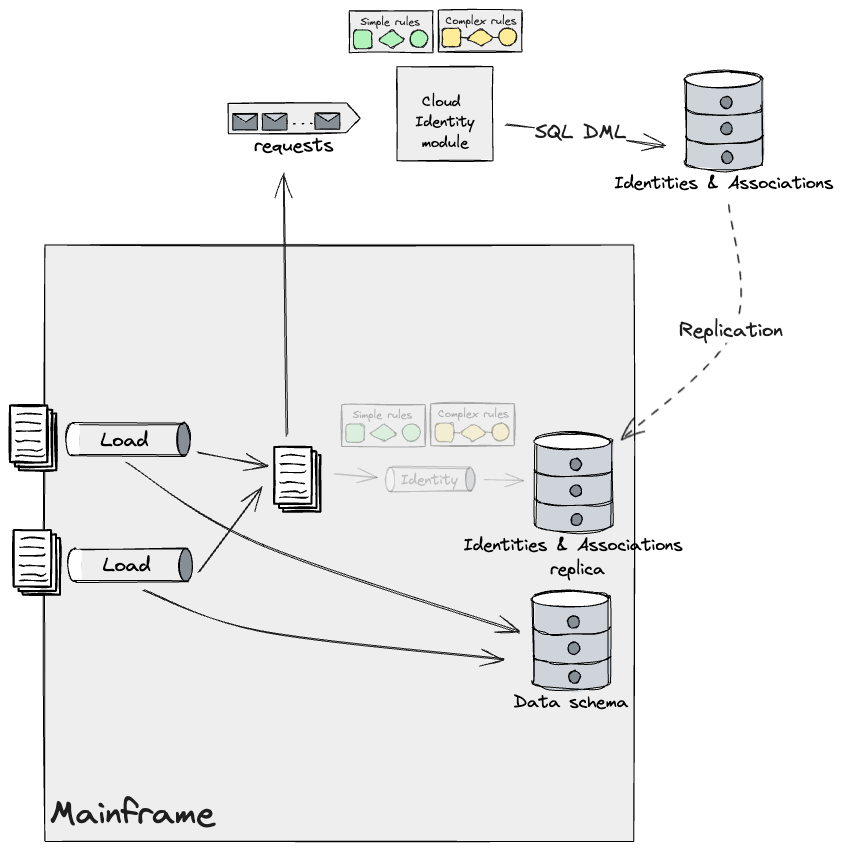
As beforehand talked about in different sections, our design employed
Legacy Mimic and an Anti-Corruption Layer that will translate information
from the Mainframe to the Cloud mannequin and vice versa. This layer
consisted of a sequence of Adapters throughout the methods, guaranteeing information
would circulation out as a stream from the Mainframe for the Cloud to devour
utilizing event-driven information pipelines, and as flat information again to the
Mainframe to permit present Batch jobs to course of them. For
simplicity, the diagrams above don’t present these adapters, however they
can be applied every time information flowed throughout methods, regardless
of how granular the seam was. Sadly, our work right here was largely
evaluation and design and we weren’t capable of take it to the subsequent step
and validate our assumptions finish to finish, aside from operating Spikes to
make sure that a CDC software and the File switch service could possibly be
employed to ship information out and in of the Mainframe, within the required
format. The time required to construct the required scaffolding across the
Mainframe, and reverse engineer the as-is pipelines to collect the
necessities was appreciable and past the timeframe of the primary
part of the programme.
Granular Seam: Downstream processing handoff
Much like the strategy employed for upstream pipelines to feed
downstream batch workloads, Legacy Mimic Adapters had been employed for
the migration of the On-line circulation. Within the present system, a buyer
API name triggers a sequence of packages producing side-effects, akin to
billing and audit trails, which get persevered in applicable
datastores (largely Journals) on the Mainframe.
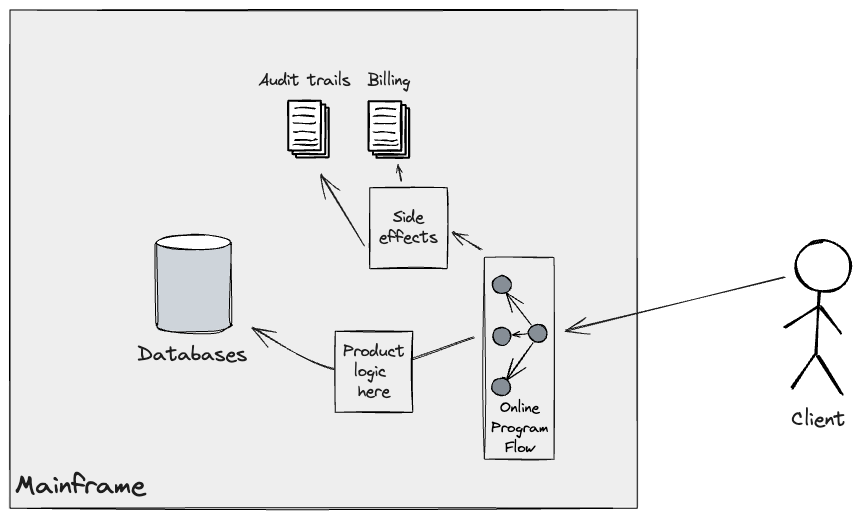
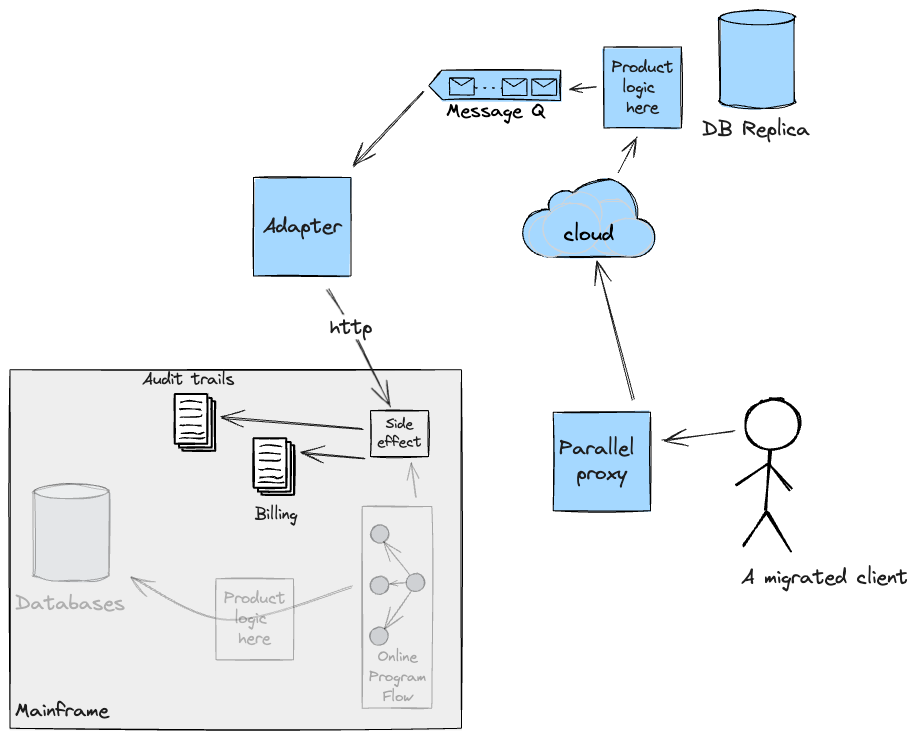
To efficiently transition incrementally the net circulation to the
Cloud, we wanted to make sure these side-effects would both be dealt with
by the brand new system immediately, thus rising scope on the Cloud, or
present adapters again to the Mainframe to execute and orchestrate the
underlying program flows answerable for them. In our case, we opted
for the latter utilizing CICS net companies. The answer we constructed was
examined for useful necessities; cross-functional ones (akin to
Latency and Efficiency) couldn’t be validated because it proved
difficult to get production-like Mainframe check environments within the
first part. The next diagram reveals, in keeping with the
implementation of our Adapter, what the circulation for a migrated buyer
would appear to be.
It’s value noting that Adapters had been deliberate to be short-term
scaffolding. They’d not have served a sound goal when the Cloud
was capable of deal with these side-effects by itself after which level we
deliberate to copy the info again to the Mainframe for so long as
required for continuity.
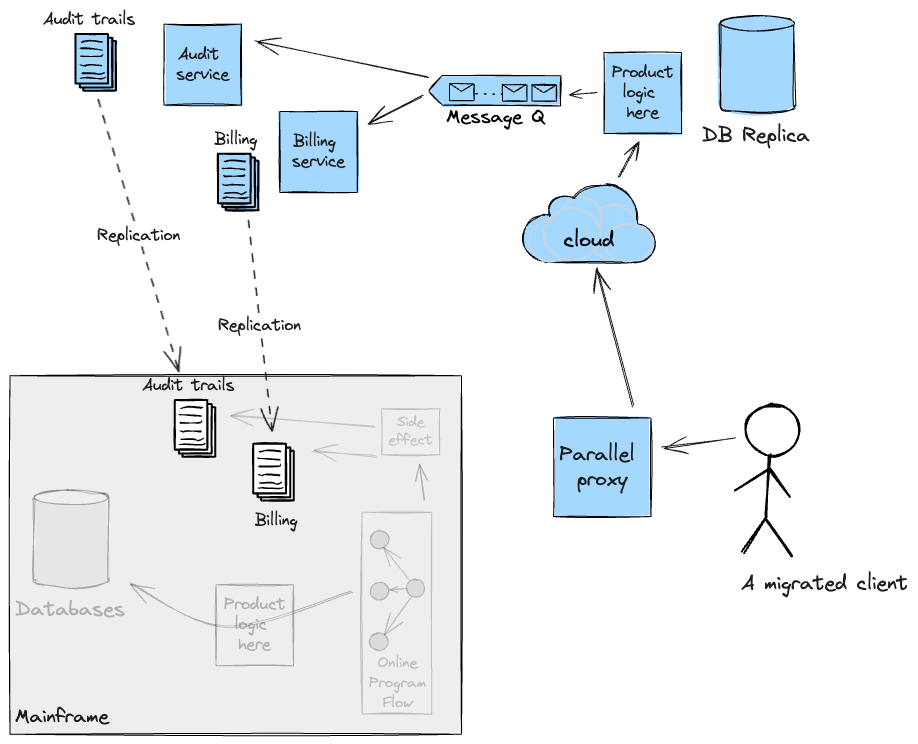
Knowledge Replication to allow new product growth
Constructing on the incremental strategy above, organisations could have
product concepts which might be based mostly totally on analytical or aggregated information
from the core information held on the Mainframe. These are sometimes the place there
is much less of a necessity for up-to-date info, akin to reporting use instances
or summarising information over trailing intervals. In these conditions, it’s
potential to unlock enterprise advantages earlier by way of the considered use of
information replication.
When completed effectively, this will allow new product growth by way of a
comparatively smaller funding earlier which in flip brings momentum to the
modernisation effort.
In our latest undertaking, our consumer had already departed on this journey,
utilizing a CDC software to copy core tables from DB2 to the Cloud.
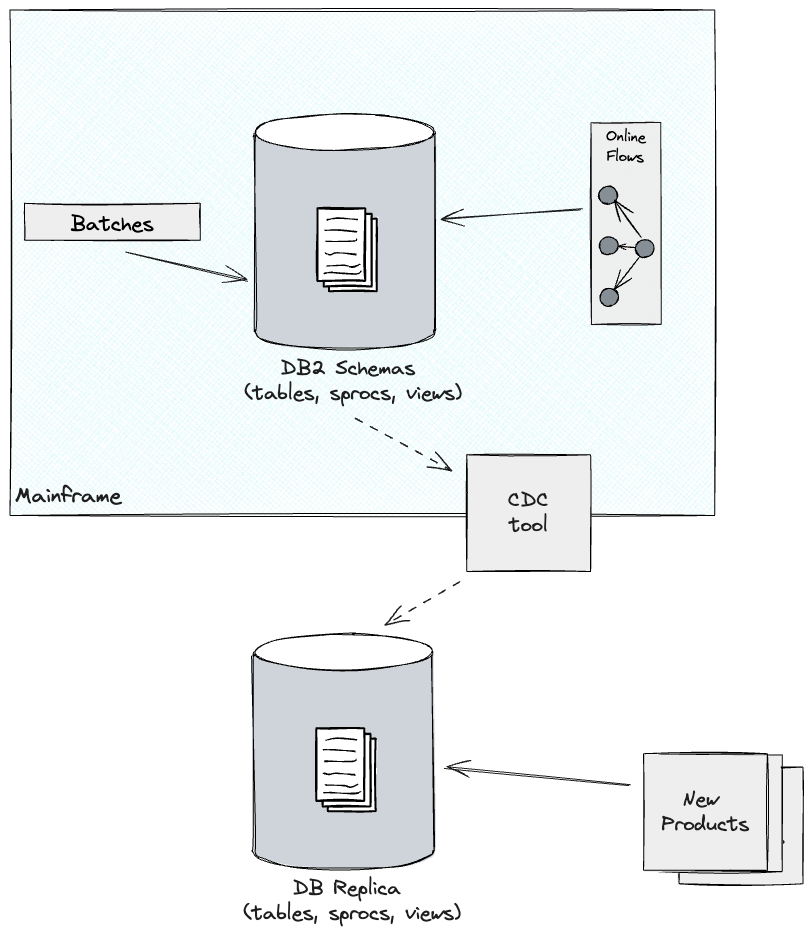
Whereas this was nice when it comes to enabling new merchandise to be launched,
it wasn’t with out its downsides.
Except you’re taking steps to summary the schema when replicating a
database, then your new cloud merchandise can be coupled to the legacy
schema as quickly as they’re constructed. It will seemingly hamper any subsequent
innovation that you could be want to do in your goal setting as you’ve
now received a further drag issue on altering the core of the applying;
however this time it’s worse as you gained’t wish to make investments once more in altering the
new product you’ve simply funded. Due to this fact, our proposed design consisted
of additional projections from the reproduction database into optimised shops and
schemas, upon which new merchandise can be constructed.
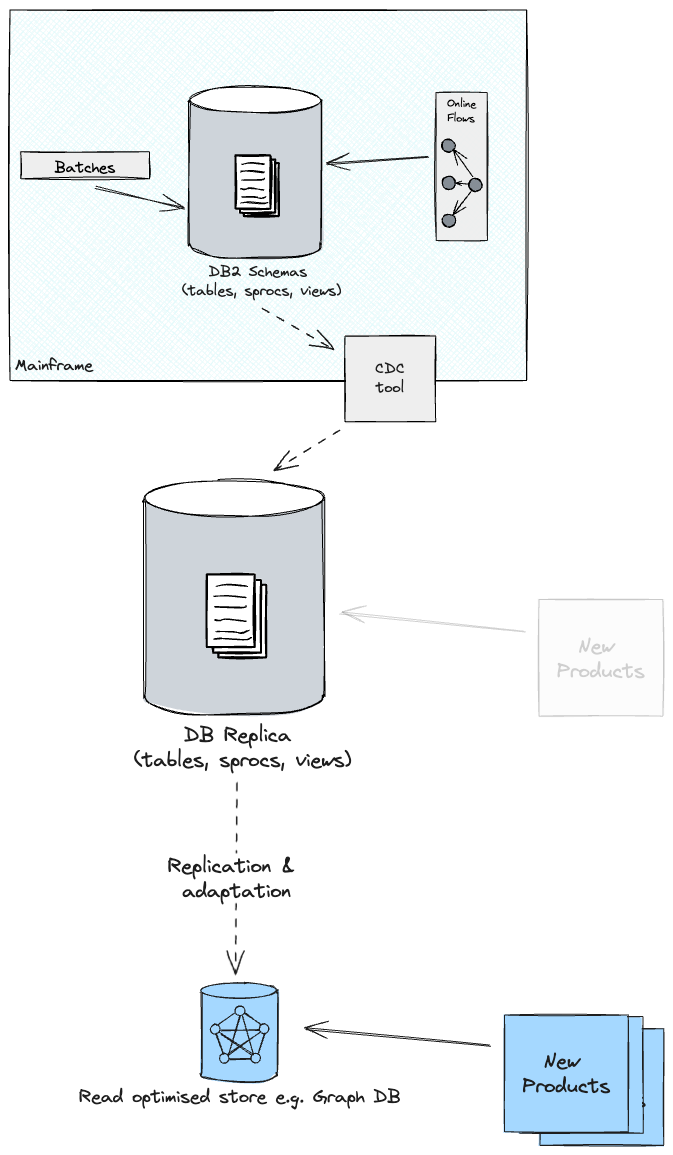
This may give us the chance to refactor the Schema, and at instances
transfer elements of the info mannequin into non-relational shops, which might
higher deal with the question patterns noticed with the SMEs.
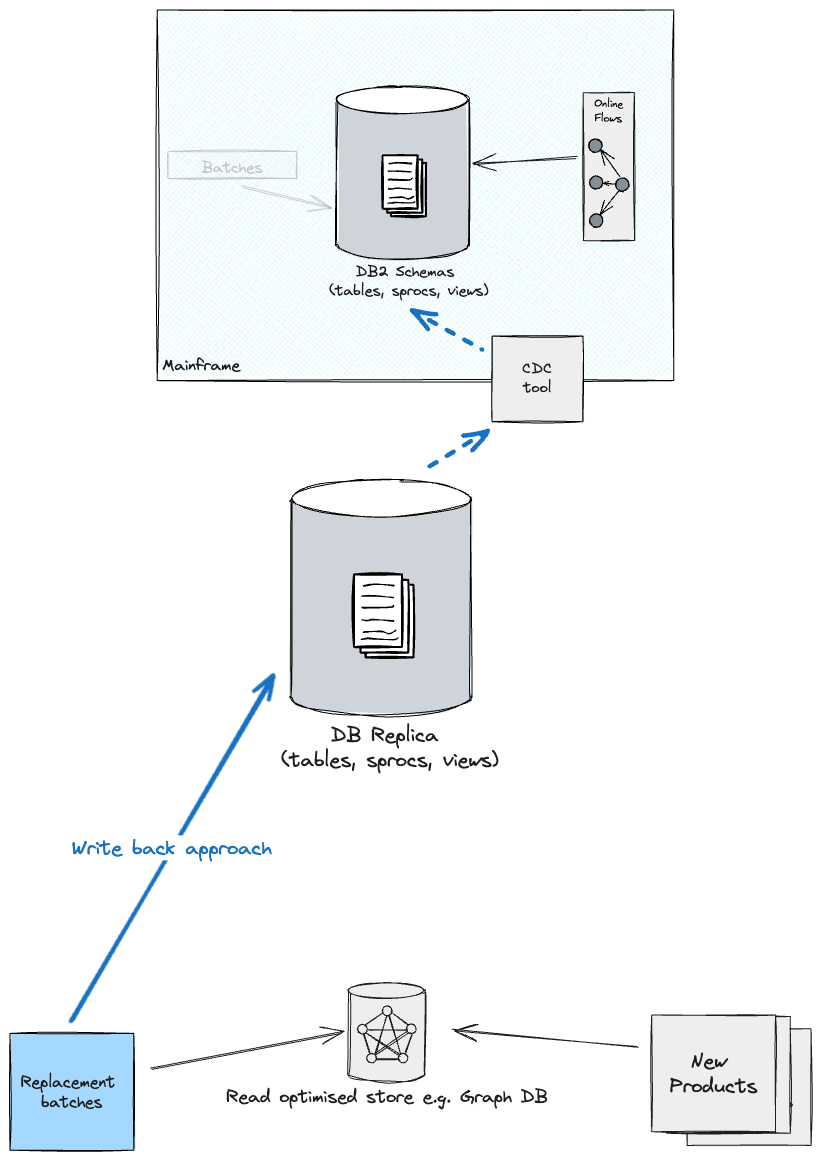
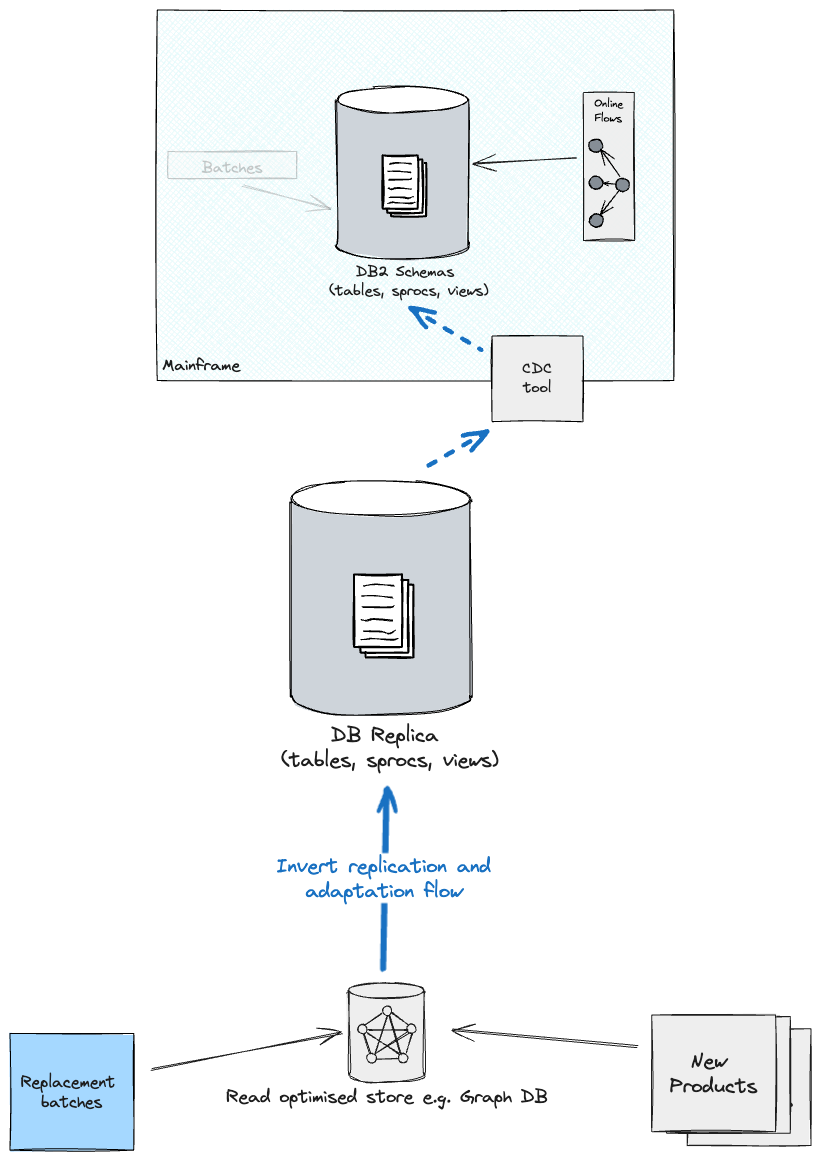
Upon
migration of batch workloads, with the intention to hold all shops in sync, you could
wish to think about both a write again technique to the brand new Main immediately
(what was beforehand often known as the Reproduction), which in flip feeds again DB2
on the Mainframe (although there can be greater coupling from the batches to
the outdated schema), or revert the CDC & Adaptation layer path from the
Optimised retailer as a supply and the brand new Main as a goal (you’ll
seemingly must handle replication individually for every information section i.e.
one information section replicates from Reproduction to Optimised retailer, one other
section the opposite approach round).
Conclusion
There are a number of issues to contemplate when offloading from the
mainframe. Relying on the scale of the system that you simply want to migrate
off the mainframe, this work can take a substantial period of time, and
Incremental Twin Run prices are non-negligible. How a lot this may value
is determined by numerous elements, however you can’t anticipate to avoid wasting on prices through
twin operating two methods in parallel. Thus, the enterprise ought to take a look at
producing worth early to get buy-in from stakeholders, and fund a
multi-year modernisation programme. We see Incremental Twin Run as an
enabler for groups to reply quick to the demand of the enterprise, going
hand in hand with Agile and Steady Supply practices.
Firstly, you must perceive the general system panorama and what
the entry factors to your system are. These interfaces play an important
position, permitting for the migration of exterior customers/purposes to the brand new
system you’re constructing. You’re free to revamp your exterior contracts
all through this migration, however it should require an adaptation layer between
the Mainframe and Cloud.
Secondly, you must establish the enterprise capabilities the Mainframe
system gives, and establish the seams between the underlying packages
implementing them. Being capability-driven helps guarantee that you’re not
constructing one other tangled system, and retains tasks and issues
separate at their applicable layers. One can find your self constructing a
sequence of Adapters that can both expose APIs, devour occasions, or
replicate information again to the Mainframe. This ensures that different methods
operating on the Mainframe can hold functioning as is. It’s best apply
to construct these adapters as reusable parts, as you’ll be able to make use of them in
a number of areas of the system, in keeping with the particular necessities you
have.
Thirdly, assuming the potential you are attempting emigrate is stateful, you’ll seemingly require a reproduction of the
information that the Mainframe has entry to. A CDC software to copy information will be employed right here. You will need to
perceive the CFRs (Cross Useful Necessities) for information replication, some information might have a quick replication
lane to the Cloud and your chosen software ought to present this, ideally. There at the moment are lots of instruments and frameworks
to contemplate and examine in your particular situation. There are a plethora of CDC instruments that may be assessed,
as an example we checked out Qlik Replicate for DB2 tables and Exactly Join extra particularly for VSAM shops.
Cloud Service Suppliers are additionally launching new choices on this space;
as an example, Twin Run by Google Cloud lately launched its personal
proprietary information replication strategy.
For a extra holistic view on mobilising a group of groups to ship a
programme of labor of this scale, please check with the article “Consuming the Elephant” by our colleague, Sophie
Holden.
Finally, there are different issues to contemplate which had been briefly
talked about as a part of this text. Amongst these, the testing technique
will play a job of paramount significance to make sure you are constructing the
new system proper. Automated testing shortens the suggestions loop for
supply groups constructing the goal system. Comparability testing ensures each
methods exhibit the identical behaviour from a technical perspective. These
methods, used at the side of Artificial information technology and
Manufacturing information obfuscation methods, give finer management over the
situations you propose to set off and validate their outcomes. Final however not
least, manufacturing comparability testing ensures the system operating in Twin
Run, over time, produces the identical final result because the legacy one by itself.
When wanted, outcomes are in contrast from an exterior observer’s level of
view at the least, akin to a buyer interacting with the system.
Moreover, we will evaluate middleman system outcomes.
Hopefully, this text brings to life what you would want to contemplate
when embarking on a Mainframe offloading journey. Our involvement was on the very first few months of a
multi-year programme and among the options we’ve mentioned had been at a really early stage of inception.
Nonetheless, we learnt a terrific deal from this work and we discover these concepts value sharing. Breaking down your
journey into viable useful steps will all the time require context, however we
hope our learnings and approaches may also help you getting began so you’ll be able to
take this the additional mile, into manufacturing, and allow your personal
roadmap.












