The Russian state-sponsored APT29 hacking group has been noticed utilizing the identical iOS and Android exploits created by industrial adware distributors in a collection of cyberattacks between November 2023 and July 2024.
The exercise was found by Google’s Menace Evaluation Group (TAG), who mentioned the n-day flaws have already been patched however stay efficient on gadgets that haven’t been up to date.
APT29, often known as “Midnight Blizzard”, focused a number of web sites of the Mongolian authorities and employed “watering gap” ways.
A watering gap is a cyberattack the place a official web site is compromised with malicious code designed to ship payloads to guests that meet particular standards, like machine structure or location (IP-based).
Apparently, TAG notes that APT29 used exploits that have been virtually equivalent to these utilized by industrial surveillance-ware distributors like NSO Group and Intellexa, who created and leveraged the issues as zero days when no repair was accessible.
Timeline of assaults
Google’s risk analysts notice that APT29 has an extended historical past of exploiting zero-day and n-day vulnerabilities.
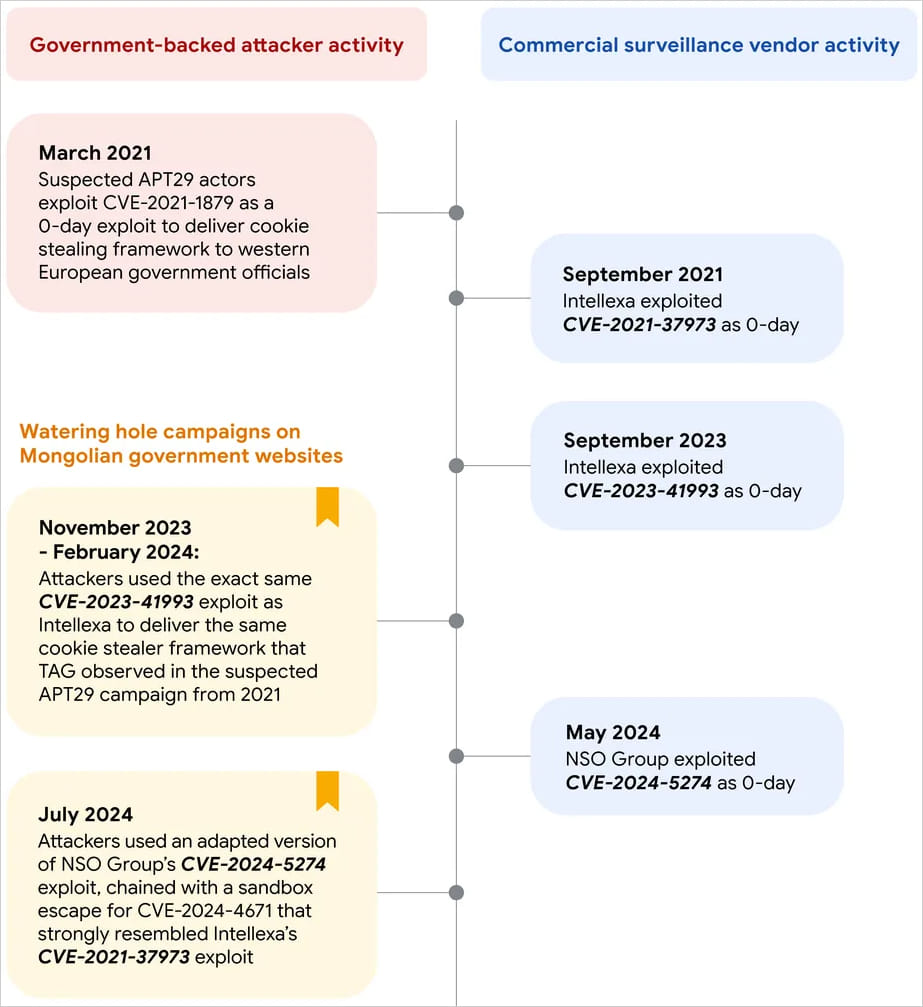
In 2021, the Russian cyber-operatives exploited CVE-2021-1879 as a zero-day, concentrating on authorities officers in Jap Europe, making an attempt to ship a cookie-stealing framework that snatched LinkedIn, Gmail, and Fb accounts.
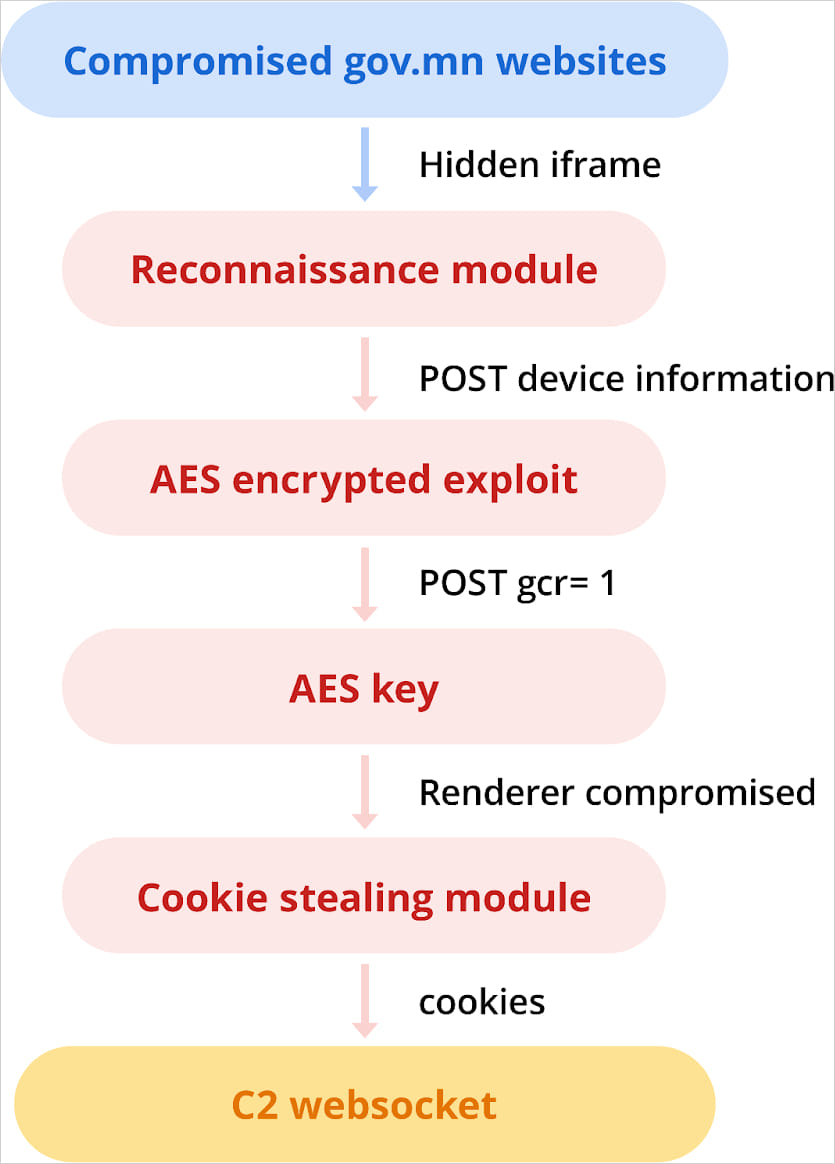
In November 2023, APT29 compromised Mongolian authorities websites ‘mfa.gov[.]mn’ and ‘cupboard.gov[.]mn’ so as to add a malicious iframe that delivered an exploit for CVE-2023-41993.
November 2023 assault chain Supply: Google
That is an iOS WebKit flaw that APT29 leveraged for stealing browser cookies from iPhone customers working iOS 16.6.1 and older.
TAG reviews that this exploit was precisely the identical because the one Intellexa utilized in September 2023, leveraging CVE-2023-41993 as a zero-day vulnerability on the time.
Exploit code overlaps (left is APT29) supply: Google
In February 2024, APT29 compromised one other Mongolian authorities web site, ‘mga.gov[.]mn,’ to inject a brand new iframe delivering the identical exploit.
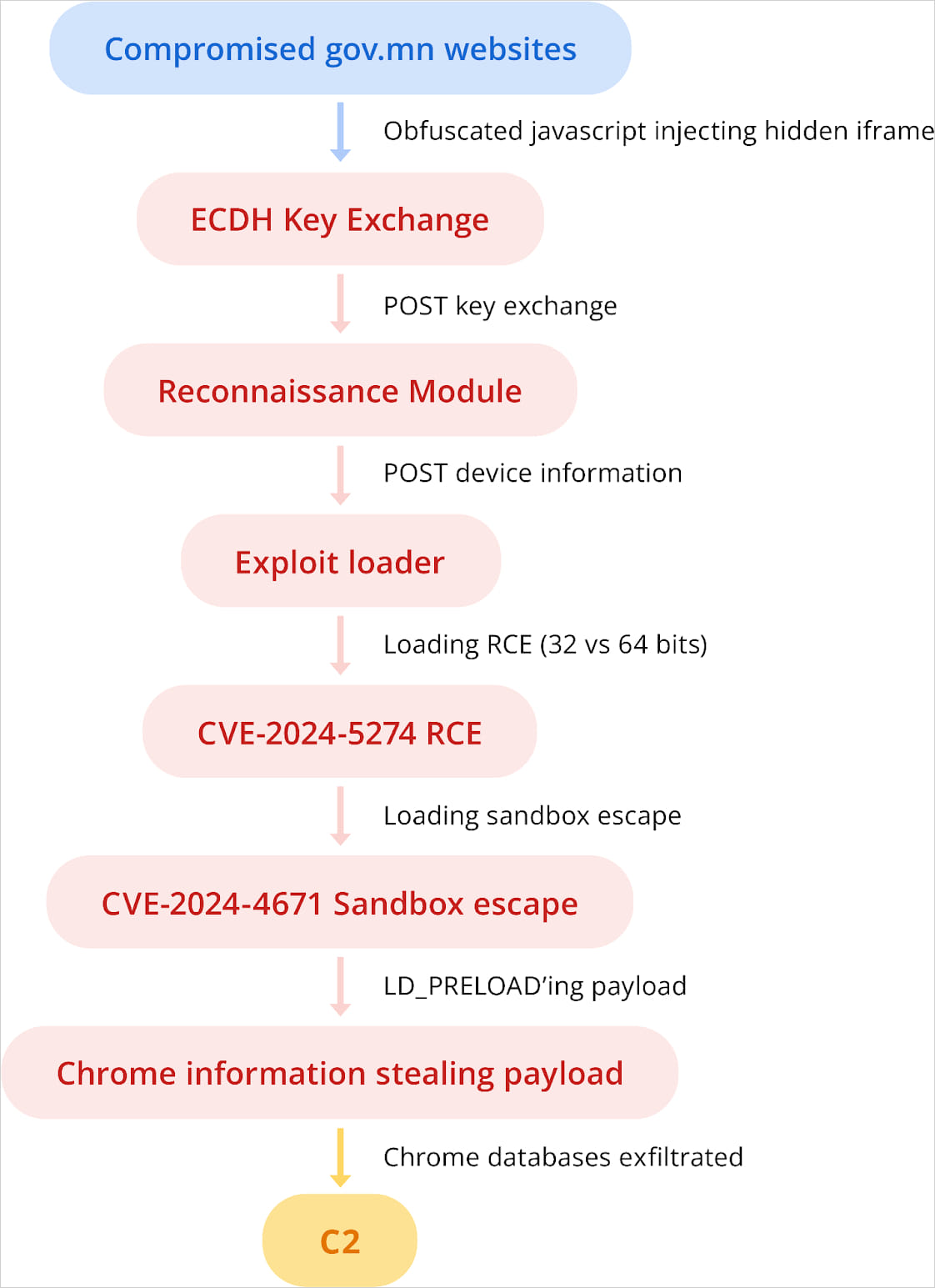
On July 2024, APT leveraged exploits for CVE-2024-5274 and CVE-2024-4671, impacting Google Chrome, to assault Android customers visiting ‘mga.gov[.]mn’.
Chaining two Google Chrome flaws supply: Google
The aim was to steal cookies, passwords, and different delicate knowledge saved on the victims’ Chrome browser.
The exploit used for CVE-2024-5274 is a barely modified model of that NSO Group used for zero-day exploitation in Could 2024, whereas the exploit for CVE-2024-4671 featured many similarities to Intellexa’s earlier exploits.
Timeline of exploitation supply: Google
Beforehand recognized solely to adware distributors
It’s unknown how the APT29 hackers gained entry to the exploits beforehand recognized solely to NSO Group and Intellexa. Nevertheless, independently creating their very own exploits with the restricted info appears unlikely.
Doable explanations embody APT29 hacking adware distributors, recruiting or bribing rogue insiders working at these corporations or sustaining a collaboration both straight or by way of an middleman.
One other risk is their buy from a vulnerability dealer who beforehand bought them to surveillance firms as zero-days.
Regardless of how these exploits attain subtle state-backed risk teams, the important thing situation is that they do. This makes it much more essential to promptly tackle zero-day vulnerabilities labeled as ‘underneath restricted scope exploitation’ in advisories—way more pressing than mainstream customers would possibly understand.
Greatest identified for his or her community hooked up options (like my beloved DS920+), Synology have lately launched a brand new product of their lineup, known as the Synology BeeStation.
The BeeStation goals to simplify the concept of a house NAS, providing a neighborhood community backup choice as a substitute for cloud options like iCloud and Dropbox. Right here’s the way it works.
Not like their extra conventional NAS units, the BeeStation is a sealed field with no accessible drive bays. Concerning the dimension of a thick hardback guide, the BeeStation resembles a compact black field that might slot in a nook of any room, maybe positioned subsequent to your Wi-Fi router (because it wants a wired Ethernet connection).
The BeeStation homes a 4 TB exhausting drive for the precise knowledge storage, of which about 3.5 TB is usable area. The highest of the BeeStation incorporates a discreet grille for warmth dissipation. Between the followers and the spinning inner exhausting drive, bear in mind it isn’t silent in operation. It’s quiet, however audible however, which is one thing to contemplate if you end up desirous about the place to place it in your house.
Setup
The BeeStation is focused at a extra mainstream viewers than Synology’s vary of NAS units, and it takes benefit of its streamlined performance to be as simple to make use of as potential. You received’t discover the same old Synology DiskStation fake windowed-operating-system-in-browser right here. You don’t need to handle storage volumes, set up apps, setup customers or companies.
The setup expertise is far more geared toward a normal shopper. You obtain a BeeStation app, plug within the energy and Ethernet cables, and comply with a few easy steps to configure the machine and affiliate it together with your Synology account.
The BeeStation app on the Mac is the primary shopper that may handle the info syncing. It manages the 2 major options, BeeFiles and BeePhotos. It is going to dwell in your menubar, largely out of sight and out of thoughts.
Apps for iOS and Android are additionally out there for cell entry. I ended up utilizing BeeStation Mac app for recordsdata syncing, and the BeePhotos iPhone app for picture syncing.
BeePhotos
The BeePhotos iPhone app permits you to again up photographs out of your machine’s picture library. For present libraries bigger than 15 GB, Synology suggest requesting an iCloud Privateness takeout ZIP file from Apple and importing that by means of the BeeStation internet app wizard.
My library is a bit larger than that; about 16,000 gadgets and measures about 30 GB in dimension.
However, I proceeded utilizing the BeePhotos iPhone app, which may switch from the Apple Photographs library on the machine. It takes time, however it dutifully copied over all my photographs to the BeeStation, wirelessly. It ended up taking all day, however it was painless — I simply left my cellphone dormant with the app open. The method is resilient sufficient that I’m assured it might deal with a lot bigger libraries, so long as you’re keen to attend.
Subsequent syncs take seconds, as a result of it is going to intelligently detect any new photographs taken and solely import these. Nonetheless, it doesn’t discover in case you delete photographs from the Apple Photographs library. They may stay in BeePhotos, and you must keep in mind to trash them once more inside BeePhotos too. This habits means you’re considerably compelled emigrate to utilizing the BeePhotos app full time going ahead, else have divergent libraries of photographs.
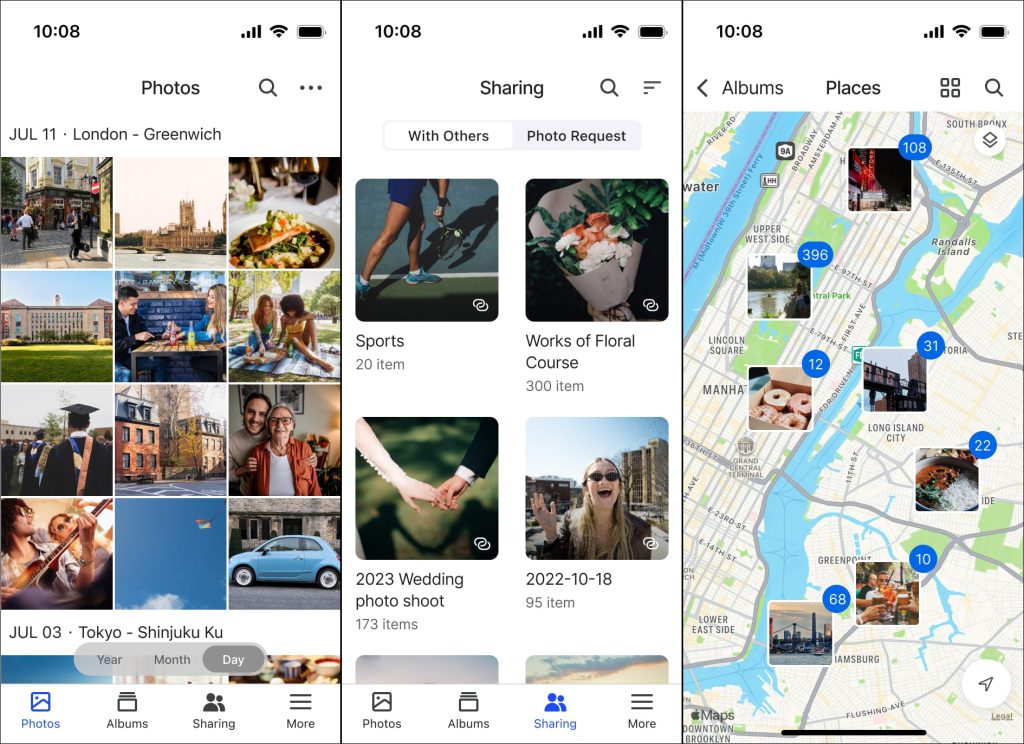
The BeePhotos app is completely practical. You may browse your library by date, with an analogous grid structure to the Apple Photographs app. BeePhotos will even do AI evaluation and tag your photographs into collections of individuals, pets, objects and landmarks. You may share elements of albums with different folks, with generated weblinks.
It’s wonderful, however is a bit of missing. The finesse and finer particulars of design are simply not there. The smoothness, the transitions, the little refinements. Maybe those that care much less about trivia of app design wouldn’t be bothered by this as a lot as I’m, however I missed the expertise of Apple Photographs. BeePhotos additionally doesn’t have issues like mechanically generated reminiscence motion pictures, or an iOS widget to indicate featured photographs on my iPhone’s dwelling display.
Equally, Synology doesn’t supply a local desktop app for searching your BeePhotos library. You should utilize the BeeStation Mac app because the sync engine, however it doesn’t have a consumer interface to really view your library. As an alternative, it redirects to you a (serviceable) internet app expertise. There’s additionally no Apple TV app, which is a giant deal in my family as I like utilizing the lounge TV to relive recollections from journeys and the like.
In sum, I’m not inclined to wish to use BeePhotos as my solely picture library app. I like the concept of not being beholden to a cloud subscription, in principle, however photographs are supposed to be loved, and I merely couldn’t take pleasure in them as effectively utilizing apps that aren’t Apple’s. Google Photographs is an honest substitute for iCloud, however once more that entails a cloud part. If BeePhotos app would deal with synced picture deletions, it could be extra versatile as I might use it as a secondary backup. As it’s, you must be keen to decide to BeeStation as your canonical picture storage, which is a step too far for me.
Replace August 30: The BeePhotos 2.0 cell app beta doubtlessly presents an answer, the place you’ll not get divergent libraries. The brand new app guarantees to sync deletes between the cellphone’s native app and BeePhotos, in addition to computerized backups of any edited photographs. Sadly, this performance was not out there for my unique overview and is at present in public beta solely.
BeeFiles
The BeeFiles providing is extra simple, as a result of there’s much less weight on the shoulders of the expertise of the file browser, in comparison with photographs. For BeeFiles, you may make your individual ‘Dropbox’ substitute with one button click on. A BeeStation location magically seems within the Mac Finder, and any recordsdata you set in that folder mechanically sync to the BeeStation unit.
You may open recordsdata and folders as in the event that they had been saved in your Mac’s inner disk. Any new recordsdata saved there will probably be uploaded within the background, with out the consumer having to do something particular. Somewhat cloud icon in Finder reviews an merchandise’s add standing to the BeeStation, similar to how iCloud Drive or Dropbox present related indicators.
In the event you right-click on the BeeStation merchandise, you’ll be able to drive offload recordsdata to release native area. I used to be fairly impressed by how seamless this all was. I might positively see giving a member of the family a BeeStation, turning this on, and simply telling them ‘save your stuff right here’, and leaving them to it.
Along with this synchronized location, you may as well elect to again up different folders in your Mac. Backup folders are merely mirrored to the BeeStation, with out two-way syncing. In case your Mac dies, or is misplaced within the discipline, you possibly can then go to the BeeStation and get better your paperwork and knowledge. All of those recordsdata are additionally accessible by means of the online app, if you should entry them on the go in a pinch, and you may make view hyperlinks to simply share recordsdata with others.
Conclusion
The Synology BeeStation ecosystem is there, for recordsdata and photographs. You may have private knowledge backup with out a month-to-month subscription, with all of your knowledge saved on a bit of web linked exhausting drive in your house. It really works. However it’s not with out some fairly huge tradeoffs.
I like my Synology NAS, as a result of I can configure it and set it up simply the best way I would like in order that it could actually work in live performance with the ecosystem I prefer to dwell in, and my cloud companies. Within the quest to simplify, the BeeStation is extra of an all-or-nothing proposition. And it simply doesn’t fairly work for me as a nerd, particularly so far as picture administration is anxious. For recordsdata, I in all probability would use the BeeStation as an on-site backup, if I didn’t have already got my Synology NAS for that goal.
For extra mainstream clients, it’s an interesting alternative, however admittedly so is utilizing a cloud service. The principle distinction is finally a private pricing resolution, as as to if you’d desire to pay as soon as for a linked exhausting drive in your house, or settle for a recurring subscription price to Apple or Google.
I do know I’ve members of the family who stubbornly refuse to subscribe to iCloud, however might actually do with having a second copy of their knowledge saved someplace if the worst occurs, and the BeeStation is a superb choice for them.
Medical ink is a collection of software program utilized in over a thousand medical trials to streamline the information assortment and administration course of, with the purpose of enhancing the effectivity and accuracy of trials. Its cloud-based digital information seize system permits medical trial information from greater than 2 million sufferers throughout 110 nations to be collected electronically in real-time from a wide range of sources, together with digital well being information and wearable gadgets.
With the COVID-19 pandemic forcing many medical trials to go digital, Medical ink has been an more and more precious answer for its capacity to help distant monitoring and digital medical trials. Quite than require trial members to come back onsite to report affected person outcomes they will shift their monitoring to the house. Consequently, trials take much less time to design, develop and deploy and affected person enrollment and retention will increase.
To successfully analyze information from medical trials within the new remote-first surroundings, medical trial sponsors got here to Medical ink with the requirement for a real-time 360-degree view of sufferers and their outcomes throughout the complete international examine. With a centralized real-time analytics dashboard outfitted with filter capabilities, medical groups can take fast motion on affected person questions and evaluations to make sure the success of the trial. The 360-degree view was designed to be the information epicenter for medical groups, offering a birds-eye view and strong drill down capabilities so medical groups might maintain trials on observe throughout all geographies.
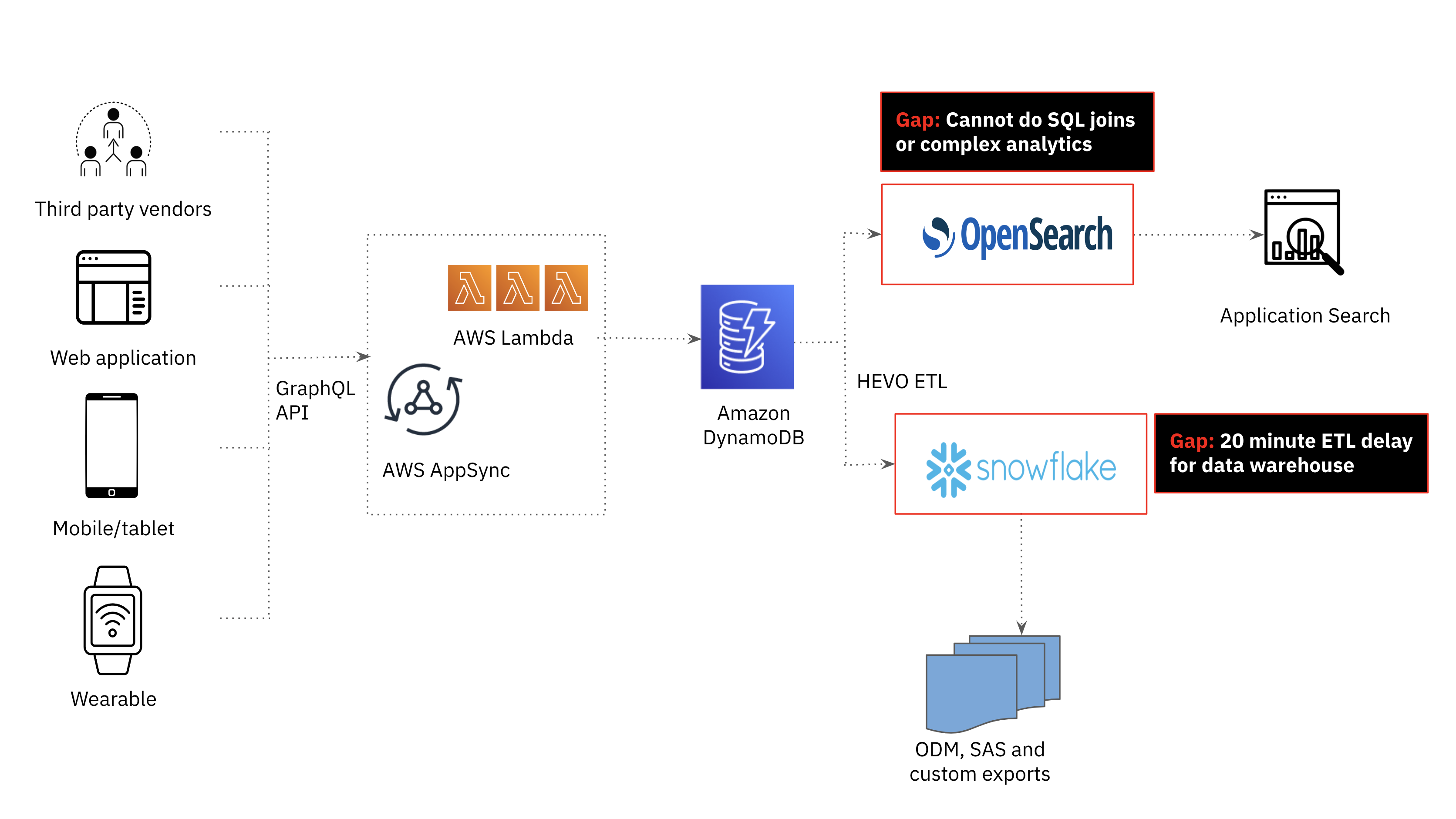
When the necessities for the brand new real-time examine participant monitoring got here to the engineering group, I knew that the present technical stack couldn’t help millisecond-latency advanced analytics on real-time information. Amazon OpenSearch, a fork of Elasticsearch used for our utility search, was quick however not purpose-built for advanced analytics together with joins. Snowflake, the strong cloud information warehouse utilized by our analyst group for performant enterprise intelligence workloads, noticed important information delays and couldn’t meet the efficiency necessities of the applying. This despatched us to the drafting board to provide you with a brand new structure; one which helps real-time ingest and complicated analytics whereas being resilient.
The Earlier than Structure
Medical ink earlier than structure for user-facing analytics
Amazon DynamoDB for Operational Workloads
Within the Medical ink platform, third get together vendor information, net purposes, cellular gadgets and wearable gadget information is saved in Amazon DynamoDB. Amazon DynamoDB’s versatile schema makes it straightforward to retailer and retrieve information in a wide range of codecs, which is especially helpful for Medical ink’s utility that requires dealing with dynamic, semi-structured information. DynamoDB is a serverless database so the group didn’t have to fret concerning the underlying infrastructure or scaling of the database as these are all managed by AWS.
Amazon Opensearch for Search Workloads
Whereas DynamoDB is a good alternative for quick, scalable and extremely out there transactional workloads, it’s not the perfect for search and analytics use instances. Within the first technology Medical ink platform, search and analytics was offloaded from DynamoDB to Amazon OpenSearch. As the quantity and number of information elevated, we realized the necessity for joins to help extra superior analytics and supply real-time examine affected person monitoring. Joins aren’t a firstclass citizen in OpenSearch, requiring quite a few operationally advanced and dear workarounds together with information denormalization, parent-child relationships, nested objects and application-side joins which can be difficult to scale.
We additionally encountered information and infrastructure operational challenges when scaling OpenSearch. One information problem we confronted centered on dynamic mapping in OpenSearch or the method of routinely detecting and mapping the information kinds of fields in a doc. Dynamic mapping was helpful as we had a lot of fields with various information sorts and had been indexing information from a number of sources with totally different schemas. Nonetheless, dynamic mapping generally led to surprising outcomes, similar to incorrect information sorts or mapping conflicts that pressured us to reindex the information.
On the infrastructure facet, despite the fact that we used managed Amazon Opensearch, we had been nonetheless chargeable for cluster operations together with managing nodes, shards and indexes. We discovered that as the dimensions of the paperwork elevated we wanted to scale up the cluster which is a handbook, time-consuming course of. Moreover, as OpenSearch has a tightly coupled structure with compute and storage scaling collectively, we needed to overprovision compute sources to help the rising variety of paperwork. This led to compute wastage and better prices and diminished effectivity. Even when we might have made advanced analytics work on OpenSearch, we might have evaluated extra databases as the information engineering and operational administration was important.
Snowflake for Information Warehousing Workloads
We additionally investigated the potential of our cloud information warehouse, Snowflake, to be the serving layer for analytics in our utility. Snowflake was used to offer weekly consolidated reviews to medical trial sponsors and supported SQL analytics, assembly the advanced analytics necessities of the applying. That mentioned, offloading DynamoDB information to Snowflake was too delayed; at a minimal, we might obtain a 20 minute information latency which fell exterior the time window required for this use case.
Necessities
Given the gaps within the present structure, we got here up with the next necessities for the alternative of OpenSearch because the serving layer:
Actual-time streaming ingest: Information modifications from DynamoDB have to be seen and queryable within the downstream database inside seconds
Millisecond-latency advanced analytics (together with joins): The database should be capable of consolidate international trial information on sufferers right into a 360-degree view. This consists of supporting advanced sorting and filtering of the information and aggregations of hundreds of various entities.
Extremely Resilient: The database is designed to keep up availability and reduce information loss within the face of assorted kinds of failures and disruptions.
Scalable: The database is cloud-native and may scale on the click on of a button or an API name with no downtime. We had invested in a serverless structure with Amazon DynamoDB and didn’t need the engineering group to handle cluster-level operations transferring ahead.
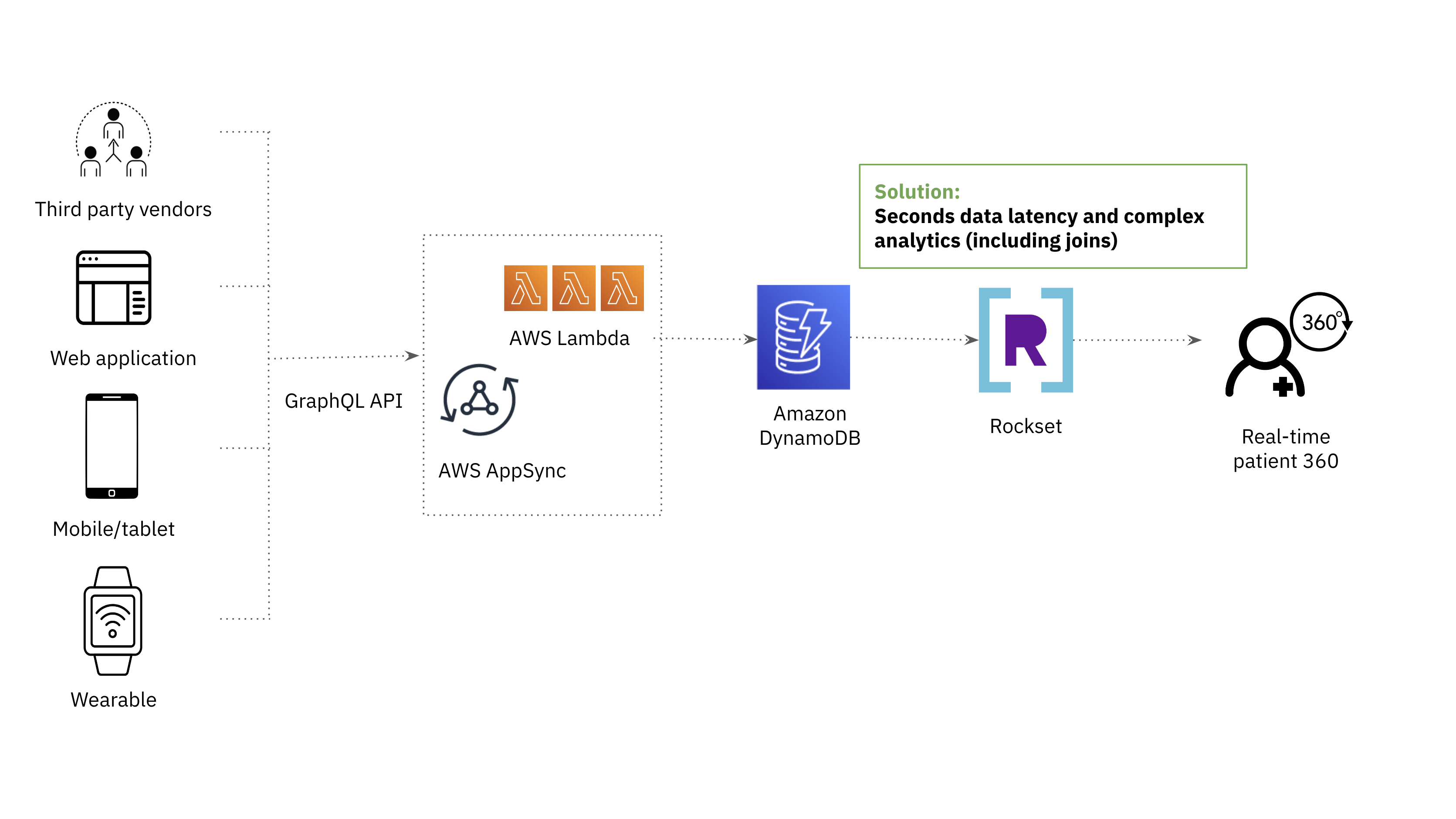
The After Structure
Medical ink after structure utilizing Rockset for real-time medical trial monitoring
Rockset initially got here on our radar as a alternative for OpenSearch for its help of advanced analytics on low latency information.
Each OpenSearch and Rockset use indexing to allow quick querying over giant quantities of knowledge. The distinction is that Rockset employs a Converged Index which is a mix of a search index, columnar retailer and row retailer for optimum question efficiency. The Converged Index helps a SQL-based question language, which permits us to satisfy the requirement for advanced analytics.
Along with Converged Indexing, there have been different options that piqued our curiosity and made it straightforward to begin efficiency testing Rockset on our personal information and queries.
Constructed-in connector to DynamoDB: New information from our DynamoDB tables are mirrored and made queryable in Rockset with only some seconds delay. This made it straightforward for Rockset to suit into our current information stack.
Potential to take a number of information sorts into the identical area: This addressed the information engineering challenges that we confronted with dynamic mapping in OpenSearch, guaranteeing that there have been no breakdowns in our ETL course of and that queries continued to ship responses even when there have been schema modifications.
Cloud-native structure: We’ve additionally invested in a serverless information stack for resource-efficiency and diminished operational overhead. We had been capable of scale ingest compute, question compute and storage independently with Rockset in order that we now not must overprovision sources.
Efficiency Outcomes
As soon as we decided that Rockset fulfilled the wants of our utility, we proceeded to evaluate the database’s ingestion and question efficiency. We ran the next assessments on Rockset by constructing a Lambda operate with Node.js:
Ingest Efficiency
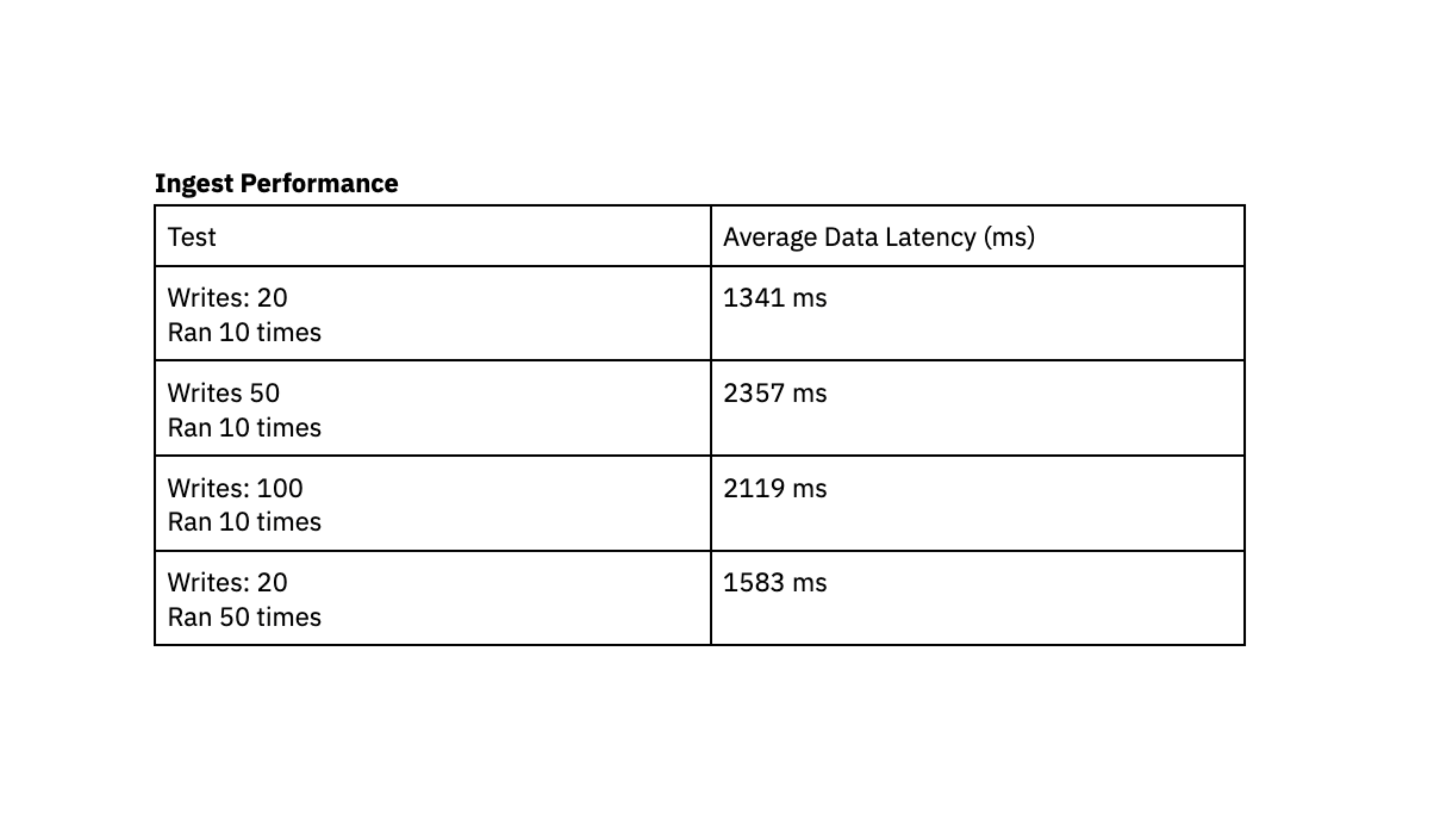
The frequent sample we see is quite a lot of small writes, ranging in measurement from 400 bytes to 2 kilobytes, grouped collectively and being written to the database steadily. We evaluated ingest efficiency by producing X writes into DynamoDB in fast succession and recording the typical time in milliseconds that it took for Rockset to sync that information and make it queryable, also called information latency.
To run this efficiency check, we used a Rockset medium digital occasion with 8 vCPU of compute and 64 GiB of reminiscence.
Streaming ingest efficiency on Rockset medium digital occasion with 8 vCPU and 64 GB RAM
The efficiency assessments point out that Rockset is able to attaining a information latency underneath 2.4 seconds, which represents the period between the technology of knowledge in DynamoDB and its availability for querying in Rockset. This load testing made us assured that we might constantly entry information roughly 2 seconds after writing to DynamoDB, giving customers up-to-date information of their dashboards. Previously, we struggled to realize predictable latency with Elasticsearch and had been excited by the consistency that we noticed with Rockset throughout load testing.
Question Efficiency
For question efficiency, we executed X queries randomly each 10-60 milliseconds. We ran two assessments utilizing queries with totally different ranges of complexity:
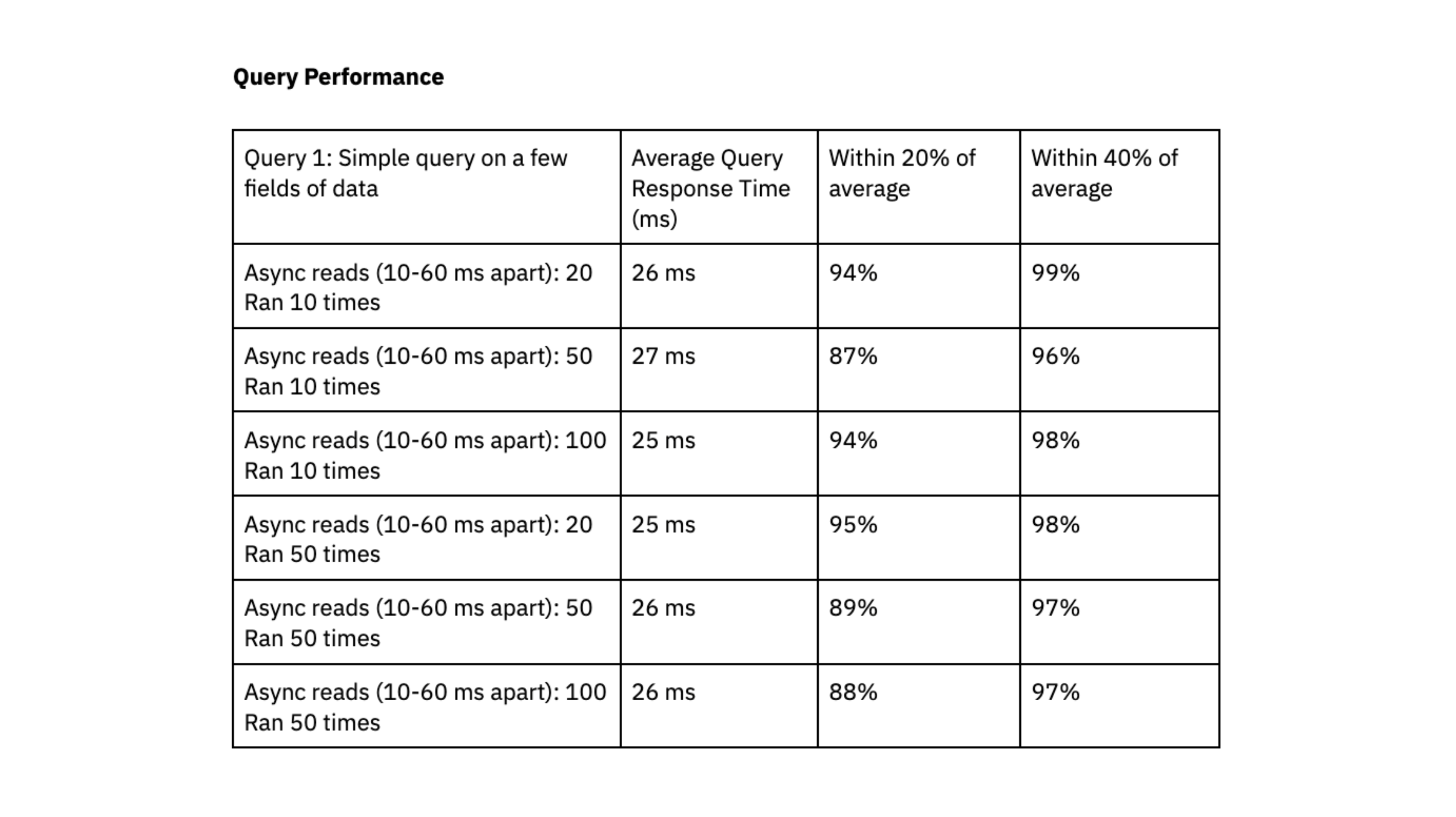
Question 1: Easy question on a couple of fields of knowledge. Dataset measurement of ~700K information and a pair of.5 GB.
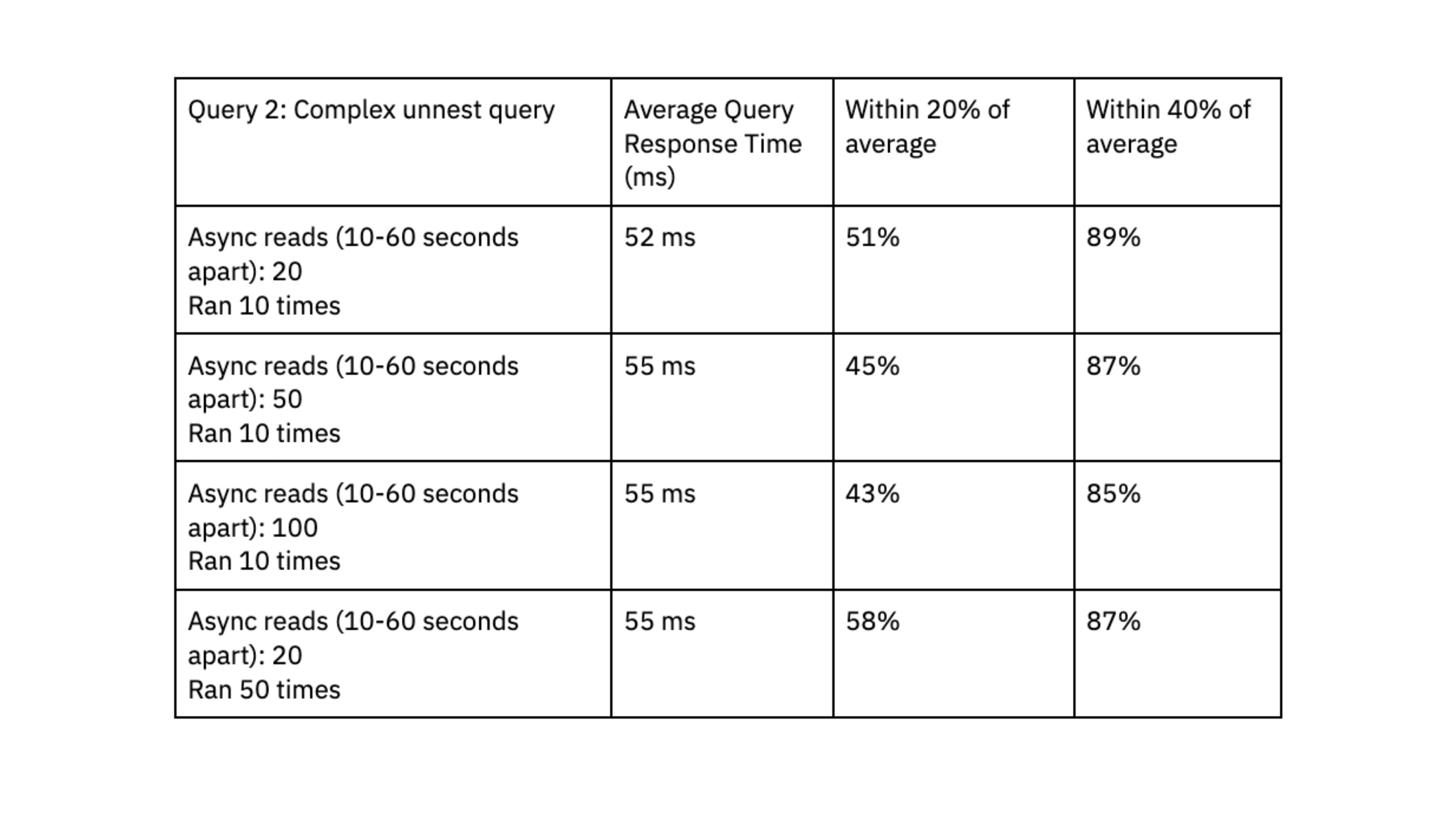
Question 2: Advanced question that expands arrays into a number of rows utilizing an unnest operate. Information is filtered on the unnested fields. Two datasets had been joined collectively: one dataset had 700K rows and a pair of.5 GB, the opposite dataset had 650K rows and 3GB.
We once more ran the assessments on a Rockset medium digital occasion with 8 vCPU of compute and 64 GiB of reminiscence.
Question efficiency of a easy question on a couple of fields of knowledge. Question was run on a Rockset digital occasion with 8 vCPU and 64 GB RAM.
Question efficiency of a fancy unnest question. Question was run on a Rockset digital occasion with 8 vCPU and 64 GB RAM.
Rockset was capable of ship question response occasions within the vary of double-digit milliseconds, even when dealing with workloads with excessive ranges of concurrency.
To find out if Rockset can scale linearly, we evaluated question efficiency on a small digital occasion, which had 4vCPU of compute and 32 GiB of reminiscence, towards the medium digital occasion. The outcomes confirmed that the medium digital occasion diminished question latency by an element of 1.6x for the primary question and 4.5x for the second question, suggesting that Rockset can scale effectively for our workload.
We appreciated that Rockset achieved predictable question efficiency, clustered inside 40% and 20% of the typical, and that queries constantly delivered in double-digit milliseconds; this quick question response time is crucial to our consumer expertise.
Conclusion
We’re presently phasing real-time medical trial monitoring into manufacturing as the brand new operational information hub for medical groups. We’ve been blown away by the pace of Rockset and its capacity to help advanced filters, joins, and aggregations. Rockset achieves double-digit millisecond latency queries and may scale ingest to help real-time updates, inserts and deletes from DynamoDB.
Not like OpenSearch, which required handbook interventions to realize optimum efficiency, Rockset has confirmed to require minimal operational effort on our half. Scaling up our operations to accommodate bigger digital situations and extra medical sponsors occurs with only a easy push of a button.
Over the following 12 months, we’re excited to roll out the real-time examine participant monitoring to all prospects and proceed our management within the digital transformation of medical trials.
Dice is a semantic layer between the info supply and knowledge functions. Artyom Keydunov is the founding father of Dice and he joins the present to speak in regards to the strategy Dice is taking.
This episode is hosted by Lee Atchison. Lee Atchison is a software program architect, writer, and thought chief on cloud computing and utility modernization. His best-selling e book, Architecting for Scale (O’Reilly Media), is an important useful resource for technical groups trying to keep excessive availability and handle threat of their cloud environments.
Lee is the host of his podcast, Trendy Digital Enterprise, an interesting and informative podcast produced for folks trying to construct and develop their digital enterprise with the assistance of contemporary functions and processes developed for in the present day’s fast-moving enterprise surroundings. Pay attention at mdb.fm. Observe Lee at softwarearchitectureinsights.com, and see all his content material at leeatchison.com.
Constructing event-driven functions simply obtained considerably simpler with Hookdeck, your go-to occasion gateway for managing webhooks and asynchronous messaging between first and third-party APIs and providers.
With Hookdeck you may obtain, remodel, and filter webhooks from third-party providers and throttle the supply to your individual infrastructure. You possibly can securely ship webhooks, triggered from your individual platform, to your buyer’s endpoints. Ingest occasions at scale from IoT units or SDKs, and use Hookdeck as your asynchronous API infrastructure. Irrespective of your use case, Hookdeck is constructed to help your full software program improvement life cycle.
Use the Hookdeck CLI to obtain occasions in your localhost. Automate dev, staging, and prod surroundings creation utilizing the Hookdeck API or Terraform Supplier. And, achieve full visibility of all occasions utilizing the Hookdeck logging and metrics within the Hookdeck dashboard. Begin constructing dependable and scalable event-driven functions in the present day. Go to hookdeck.com/sedaily and signal as much as get a 3 month trial of the Hookdeck Crew plan without cost.
WorkOS is a contemporary identification platform constructed for B2B SaaS. It offers seamless APIs for authentication, consumer identification, and complicated enterprise options like SSO and SCIM provisioning. It’s a drop-in substitute for Auth0 (auth-zero) and helps as much as 1 million month-to-month lively customers without cost.
It’s good for B2B SaaS firms annoyed with excessive prices, opaque pricing, and lack of enterprise capabilities supported by legacy auth distributors. The APIs are versatile and simple to make use of, designed to offer a simple expertise out of your first consumer all the best way to your largest enterprise buyer.
Right this moment, a whole bunch of high-growth scale-ups are already powered by WorkOS, together with ones you in all probability know, like Vercel, Webflow, and Loom. Try workos.com/SED to be taught extra.
Is your code getting dragged down by joins and lengthy question instances? The issue is likely to be your database. Strive simplifying the advanced with graphs. A graph database allows you to mannequin knowledge the best way it seems to be in the actual world as a substitute of forcing it into rows and columns.
Cease asking relational databases to do greater than they had been made for. Graphs work properly to be used instances with plenty of knowledge connections like provide chain, fraud detection, actual actual -time analytics, and Gen AI. With Neo4j, you may code in your favourite programming language and in opposition to any driver.
Plus, it’s simple to combine into your tech stack. Individuals are fixing a number of the world’s largest issues with graphs. Now it’s your flip. Go to https://neo4j.com/developer/
In a way, picture segmentation just isn’t that totally different from picture classification. It’s simply that as an alternative of categorizing a picture as an entire, segmentation ends in a label for each single pixel. And as in picture classification, the classes of curiosity rely upon the duty: Foreground versus background, say; various kinds of tissue; various kinds of vegetation; et cetera.
The current publish just isn’t the primary on this weblog to deal with that subject; and like all prior ones, it makes use of a U-Web structure to attain its purpose. Central traits (of this publish, not U-Web) are:
It demonstrates the way to carry out information augmentation for a picture segmentation job.
It makes use of luz, torch’s high-level interface, to coach the mannequin.
It JIT-traces the skilled mannequin and saves it for deployment on cell gadgets. (JIT being the acronym generally used for the torch just-in-time compiler.)
It consists of proof-of-concept code (although not a dialogue) of the saved mannequin being run on Android.
And should you suppose that this in itself just isn’t thrilling sufficient – our job right here is to seek out cats and canine. What could possibly be extra useful than a cell software ensuring you may distinguish your cat from the fluffy couch she’s reposing on?
As supplied by torchdatasets, the Oxford Pet Dataset comes with three variants of goal information to select from: the general class (cat or canine), the person breed (there are thirty-seven of them), and a pixel-level segmentation with three classes: foreground, boundary, and background. The latter is the default; and it’s precisely the kind of goal we want.
A name to oxford_pet_dataset(root = dir) will set off the preliminary obtain:
# want torch > 0.6.1# could must run remotes::install_github("mlverse/torch", ref = remotes::github_pull("713")) relying on once you learn thislibrary(torch)library(torchvision)library(torchdatasets)library(luz)dir<-"~/.torch-datasets/oxford_pet_dataset"ds<-oxford_pet_dataset(root =dir)
Photographs (and corresponding masks) come in numerous sizes. For coaching, nevertheless, we’ll want all of them to be the identical measurement. This may be completed by passing in remodel = and target_transform = arguments. However what about information augmentation (principally all the time a helpful measure to take)? Think about we make use of random flipping. An enter picture might be flipped – or not – in response to some likelihood. But when the picture is flipped, the masks higher had be, as properly! Enter and goal transformations should not impartial, on this case.
An answer is to create a wrapper round oxford_pet_dataset() that lets us “hook into” the .getitem() methodology, like so:
pet_dataset<-torch::dataset( inherit =oxford_pet_dataset, initialize =perform(..., measurement, normalize=TRUE, augmentation=NULL){self$augmentation<-augmentationinput_transform<-perform(x){x<-x%>%transform_to_tensor()%>%transform_resize(measurement)# we'll make use of pre-trained MobileNet v2 as a function extractor# => normalize with the intention to match the distribution of photos it was skilled withif(isTRUE(normalize))x<-x%>%transform_normalize(imply =c(0.485, 0.456, 0.406), std =c(0.229, 0.224, 0.225))x}target_transform<-perform(x){x<-torch_tensor(x, dtype =torch_long())x<-x[newaxis,..]# interpolation = 0 makes certain we nonetheless find yourself with integer lessonsx<-transform_resize(x, measurement, interpolation =0)}tremendous$initialize(..., remodel =input_transform, target_transform =target_transform)}, .getitem =perform(i){merchandise<-tremendous$.getitem(i)if(!is.null(self$augmentation))self$augmentation(merchandise)elsechecklist(x =merchandise$x, y =merchandise$y[1,..])})
All we’ve got to do now’s create a customized perform that lets us determine on what augmentation to use to every input-target pair, after which, manually name the respective transformation capabilities.
Right here, we flip, on common, each second picture, and if we do, we flip the masks as properly. The second transformation – orchestrating random adjustments in brightness, saturation, and distinction – is utilized to the enter picture solely.
augmentation<-perform(merchandise){vflip<-runif(1)>0.5x<-merchandise$xy<-merchandise$yif(isTRUE(vflip)){x<-transform_vflip(x)y<-transform_vflip(y)}x<-transform_color_jitter(x, brightness =0.5, saturation =0.3, distinction =0.3)checklist(x =x, y =y[1,..])}
We now make use of the wrapper, pet_dataset(), to instantiate the coaching and validation units, and create the respective information loaders.
The mannequin implements a traditional U-Web structure, with an encoding stage (the “down” go), a decoding stage (the “up” go), and importantly, a “bridge” that passes options preserved from the encoding stage on to corresponding layers within the decoding stage.
Encoder
First, we’ve got the encoder. It makes use of a pre-trained mannequin (MobileNet v2) as its function extractor.
The encoder splits up MobileNet v2’s function extraction blocks into a number of phases, and applies one stage after the opposite. Respective outcomes are saved in a listing.
The decoder is made up of configurable blocks. A block receives two enter tensors: one that’s the results of making use of the earlier decoder block, and one which holds the function map produced within the matching encoder stage. Within the ahead go, first the previous is upsampled, and handed by means of a nonlinearity. The intermediate result’s then prepended to the second argument, the channeled-through function map. On the resultant tensor, a convolution is utilized, adopted by one other nonlinearity.
Lastly, the top-level module generates the category rating. In our job, there are three pixel lessons. The score-producing submodule can then simply be a last convolution, producing three channels:
With luz, mannequin coaching is a matter of two verbs, setup() and match(). The training fee has been decided, for this particular case, utilizing luz::lr_finder(); you’ll doubtless have to vary it when experimenting with totally different types of information augmentation (and totally different information units).
mannequin<-mannequin%>%setup(optimizer =optim_adam, loss =nn_cross_entropy_loss())fitted<-mannequin%>%set_opt_hparams(lr =1e-3)%>%match(train_dl, epochs =10, valid_data =valid_dl)
Right here is an excerpt of how coaching efficiency developed in my case:
Numbers are simply numbers – how good is the skilled mannequin actually at segmenting pet photos? To search out out, we generate segmentation masks for the primary eight observations within the validation set, and plot them overlaid on the pictures. A handy approach to plot a picture and superimpose a masks is supplied by the raster bundle.
Pixel intensities must be between zero and one, which is why within the dataset wrapper, we’ve got made it so normalization will be switched off. To plot the precise photos, we simply instantiate a clone of valid_ds that leaves the pixel values unchanged. (The predictions, then again, will nonetheless must be obtained from the unique validation set.)
The traced mannequin may now be saved to be used with Python or C++, like so:
traced%>%jit_save("traced_model.pt")
Nonetheless, since we already know we’d prefer to deploy it on Android, we as an alternative make use of the specialised perform jit_save_for_mobile() that, moreover, generates bytecode:
The precise proof-of-concept code for this publish (which was used to generate the beneath image) could also be discovered right here: https://github.com/skeydan/ImageSegmentation. (Be warned although – it’s my first Android software!).
After all, we nonetheless must attempt to discover the cat. Right here is the mannequin, run on a tool emulator in Android Studio, on three photos (from the Oxford Pet Dataset) chosen for, firstly, a variety in problem, and secondly, properly … for cuteness:
The place’s my cat?
Thanks for studying!
Parkhi, Omkar M., Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. 2012. “Cats and Canines.” In IEEE Convention on Laptop Imaginative and prescient and Sample Recognition.
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Web: Convolutional Networks for Biomedical Picture Segmentation.”CoRR abs/1505.04597. http://arxiv.org/abs/1505.04597.