Ahead-looking: Nvidia will probably be showcasing its Blackwell tech stack at Scorching Chips 2024, with pre-event demonstrations this weekend and on the primary occasion subsequent week. It is an thrilling time for Nvidia lovers, who will get an in-depth have a look at a few of Staff Inexperienced’s newest expertise. Nevertheless, what stays unstated are the potential delays reported for the Blackwell GPUs, which might affect the timelines of a few of these merchandise.
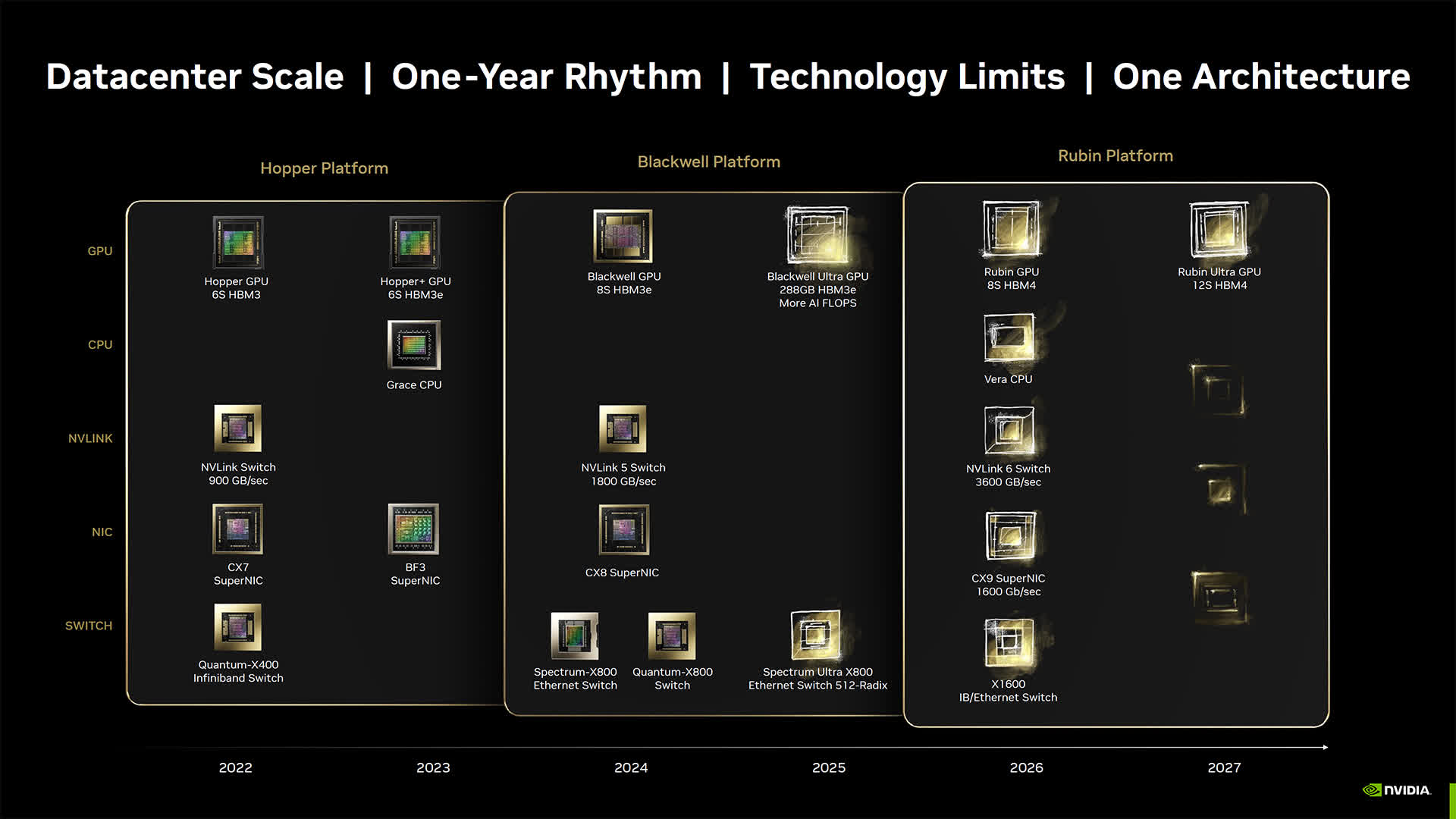
Nvidia is set to redefine the AI panorama with its Blackwell platform, positioning it as a complete ecosystem that goes past conventional GPU capabilities. Nvidia will showcase the setup and configuration of its Blackwell servers, in addition to the mixing of assorted superior parts, on the Scorching Chips 2024 convention.
A lot of Nvidia’s upcoming shows will cowl acquainted territory, together with their information heart and AI methods, together with the Blackwell roadmap. This roadmap outlines the discharge of the Blackwell Extremely subsequent 12 months, adopted by Vera CPUs and Rubin GPUs in 2026, and the Vera Extremely in 2027. This roadmap had already been shared by Nvidia at Computex final June.
For tech lovers wanting to dive deep into the Nvidia Blackwell stack and its evolving use instances, Scorching Chips 2024 will present a chance to discover Nvidia’s newest developments in AI {hardware}, liquid cooling improvements, and AI-driven chip design.
One of many key shows will supply an in-depth have a look at the Nvidia Blackwell platform, which consists of a number of Nvidia parts, together with the Blackwell GPU, Grace CPU, BlueField information processing unit, ConnectX community interface card, NVLink Change, Spectrum Ethernet change, and Quantum InfiniBand change.
Moreover, Nvidia will unveil its Quasar Quantization System, which merges algorithmic developments, Nvidia software program libraries, and Blackwell’s second-generation Transformer Engine to reinforce FP4 LLM operations. This improvement guarantees vital bandwidth financial savings whereas sustaining the high-performance requirements of FP16, representing a significant leap in information processing effectivity.
One other point of interest would be the Nvidia GB200 NVL72, a multi-node, liquid-cooled system that includes 72 Blackwell GPUs and 36 Grace CPUs. Attendees will even discover the NVLink interconnect expertise, which facilitates GPU communication with distinctive throughput and low-latency inference.
Nvidia’s progress in information heart cooling will even be a subject of debate. The corporate is investigating the usage of heat water liquid cooling, a technique that would scale back energy consumption by as much as 28%. This system not solely cuts vitality prices but in addition eliminates the need for under ambient cooling {hardware}, which Nvidia hopes will place it as a frontrunner in sustainable tech options.
According to these efforts, Nvidia’s involvement within the COOLERCHIPS program, a U.S. Division of Power initiative aimed toward advancing cooling applied sciences, will probably be highlighted. Via this mission, Nvidia is utilizing its Omniverse platform to develop digital twins that simulate vitality consumption and cooling effectivity.
In one other session, Nvidia will focus on its use of agent-based AI techniques able to autonomously executing duties for chip design. Examples of AI brokers in motion will embody timing report evaluation, cell cluster optimization, and code era. Notably, the cell cluster optimization work was just lately acknowledged as one of the best paper on the inaugural IEEE Worldwide Workshop on LLM-Aided Design.
This weblog put up is a follow-up to the session From Supernovas to LLMs at Knowledge + AI Summit 2024, the place I demonstrated how anybody can devour and course of publicly out there NASA satellite tv for pc knowledge from Apache Kafka.
In contrast to most Kafka demos, which aren’t simply reproducible or depend on simulated knowledge, I’ll present the right way to analyze a reside knowledge stream from NASA’s publicly accessible Gamma-ray Coordinates Community (GCN) which integrates knowledge from supernovas and black holes coming from numerous satellites.
Whereas it is doable to craft an answer utilizing solely open supply Apache Spark™ and Apache Kafka, I’ll present the numerous benefits of utilizing the Databricks Knowledge Intelligence Platform for this job. Additionally, the supply code for each approaches might be offered.
The answer constructed on the Knowledge Intelligence Platform leverages Delta Reside Tables with serverless compute for knowledge ingestion and transformation, Unity Catalog for knowledge governance and metadata administration, and the facility of AI/BI Genie for pure language querying and visualization of the NASA knowledge stream. The weblog additionally showcases the facility of Databricks Assistant for the era of advanced SQL transformations, debugging and documentation.
Supernovas, black holes and gamma-ray bursts
The evening sky will not be static. Cosmic occasions like supernovas and the formation of black holes occur steadily and are accompanied by highly effective gamma-ray bursts (GRBs). Such gamma-ray bursts usually final solely two seconds, and a two-second GRB usually releases as a lot power because the Solar’s throughout its total lifetime of some 10 billion years.
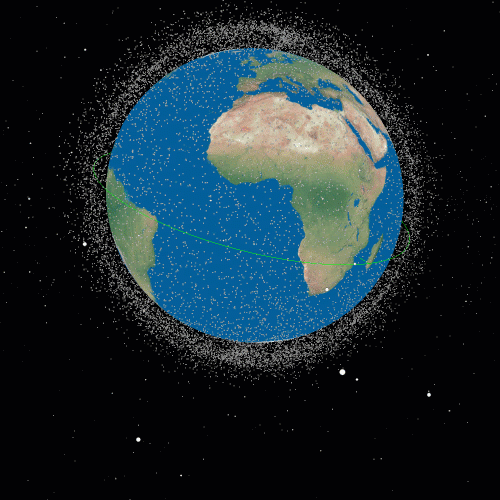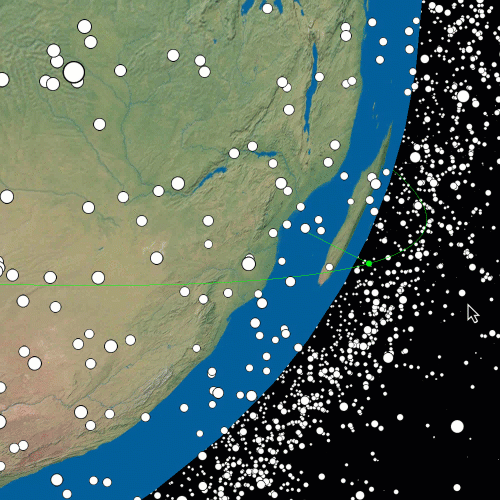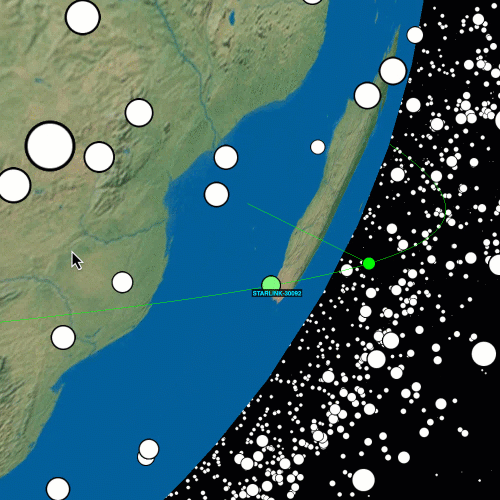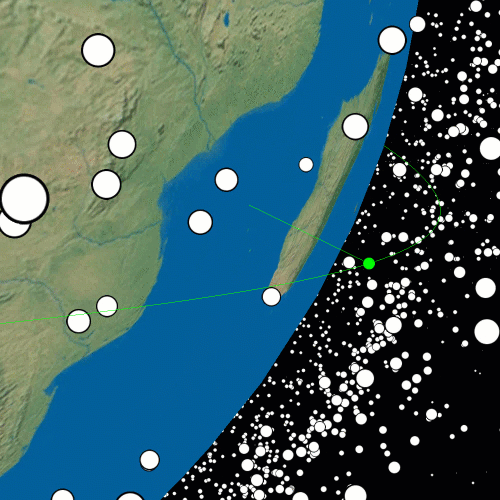
Throughout the Chilly Conflict, particular satellites constructed to detect covert nuclear weapon exams coincidentally found these intense flashes of gamma radiation originating from deep house. Immediately, NASA makes use of a fleet of satellites like Swift and Fermi to detect and examine these bursts that originated billions of years in the past in distant galaxies. The inexperienced line within the following animation exhibits the SWIFT satellite tv for pc’s orbit at 11 AM CEST on August 1, 2024, generated with Satellite tv for pc Tracker 3D, courtesy of Marko Andlar.
GRB 221009A, one of many brightest and most energetic GRBs ever recorded, blinded most devices due to its power. It originated from the constellation of Sagitta and is believed to have occurred roughly 1.9 billion years in the past. Nevertheless, because of the enlargement of the universe over time, the supply of the burst is now about 2.4 billion light-years away from Earth. GRB 221009A is proven within the picture beneath.
Trendy astronomy now embraces a multi-messenger strategy, capturing numerous alerts collectively corresponding to neutrinos along with gentle and gamma rays. The IceCube observatory on the South Pole, for instance, makes use of over 5,000 detectors embedded inside a cubic kilometer of Antarctic ice to detect neutrinos passing by the Earth.
The Gamma-ray Coordinates Community challenge connects these superior observatories — hyperlinks supernova knowledge from house satellites and neutrino knowledge from Antarctica — and makes NASA’s knowledge streams accessible worldwide.
Whereas analyzing knowledge from NASA satellites could appear daunting, I would prefer to show how simply any knowledge scientist can discover these scientific knowledge streams utilizing the Databricks Knowledge Intelligence Platform, due to its sturdy instruments and pragmatic abstractions.
As a bonus, you’ll find out about one of many coolest publicly out there knowledge streams you can simply reuse in your personal research.
Now, let me clarify the steps I took to deal with this problem.
Consuming Supernova Knowledge From Apache Kafka
Getting OICD token from GCN Quickstart
NASA presents the GCN knowledge streams as Apache Kafka matters the place the Kafka dealer requires authentication through an OIDC credential. Acquiring GCN credentials is simple:
Authenticate utilizing Gmail or different social media accounts
Obtain a shopper ID and shopper secret
The Quickstart will create a Python code snippet that makes use of the GCN Kafka dealer, which is constructed on the Confluent Kafka codebase.
It is essential to notice that whereas the GCN Kafka wrapper prioritizes ease of use, it additionally abstracts most technical particulars such because the Kafka connection parameters for OAuth authentication.
The open supply manner with Apache Spark™
To be taught extra about that supernova knowledge, I made a decision to start with essentially the most common open supply answer that may give me full management over all parameters and configurations. So I carried out a POC with a pocket book utilizing Spark Structured Streaming. At its core, it boils right down to the next line:
In fact, the essential element right here is within the **kafka_config connection particulars which I extracted from the GCN wrapper. The complete Spark pocket book is offered on GitHub (see repo on the finish of the weblog).
My final objective, nonetheless, was to summary the lower-level particulars and create a stellar knowledge pipeline that advantages from Databricks Delta Reside Tables (DLT) for knowledge ingestion and transformation.
Incrementally ingesting supernova knowledge from GCN Kafka with Delta Reside Tables
There have been a number of the reason why I selected DLT:
Declarative strategy: DLT permits me to give attention to writing the pipeline declaratively, abstracting a lot of the complexity. I can give attention to the info processing logic making it simpler to construct and keep my pipeline whereas benefiting from Databricks Assistant, Auto Loader and AI/BI.
Serverless infrastructure: With DLT, infrastructure administration is totally automated and compute assets are provisioned serverless, eliminating guide setup and configuration. This allows superior options corresponding to incremental materialized view computation and vertical autoscaling, permitting for environment friendly, scalable and cost-efficient knowledge processing.
This strategy allowed me to streamline the event course of and create a easy, scalable and serverless pipeline for cosmic knowledge with out getting slowed down in infrastructure particulars.
A DLT knowledge pipeline will be coded completely in SQL (Python is out there too, however solely required for some uncommon metaprogramming duties, i.e., if you wish to write code that creates pipelines).
With DLT’s new enhancements for builders, you possibly can write code in a pocket book and join it to a working pipeline. This integration brings the pipeline view and occasion log immediately into the pocket book, making a streamlined growth expertise. From there, you possibly can validate and run your pipeline, all inside a single, optimized interface — primarily a mini-IDE for DLT.
DLT streaming tables
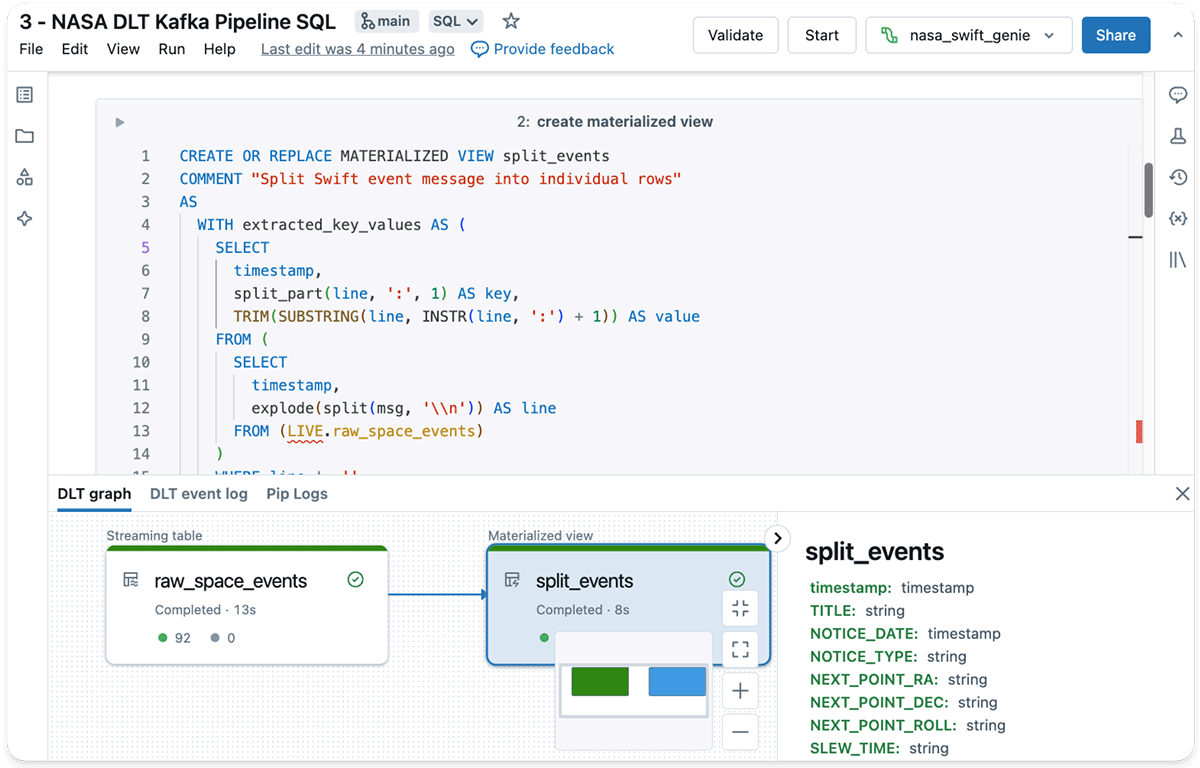
DLT makes use of streaming tables to ingest knowledge incrementally from all types of cloud object shops or message brokers. Right here, I take advantage of it with the read_kafka() operate in SQL to learn knowledge immediately from the GCN Kafka dealer right into a streaming desk.
That is the primary essential step within the pipeline to get knowledge off the Kafka dealer. On the Kafka dealer, knowledge lives for a set retention interval solely, however as soon as ingested to the lakehouse, the info is endured completely and can be utilized for any form of analytics or machine studying.
Ingesting a reside knowledge stream is feasible due to the underlying Delta knowledge format. Delta tables are the high-speed knowledge format for DWH functions, and you’ll concurrently stream knowledge to (or from) a Delta desk.
The code to devour the info from the Kafka dealer with Delta Reside Tables appears to be like as follows:
CREATEOR REPLACE STREAMING TABLE raw_space_events ASSELECToffset, timestamp, worth::string as msg
FROM STREAM read_kafka(
bootstrapServers =>'kafka.gcn.nasa.gov:9092',
subscribe =>'gcn.traditional.textual content.SWIFT_POINTDIR',
startingOffsets =>'earliest',
-- kafka connection particulars omitted for brevity );
For brevity, I omitted the connection setting particulars within the instance above (full code in GitHub).
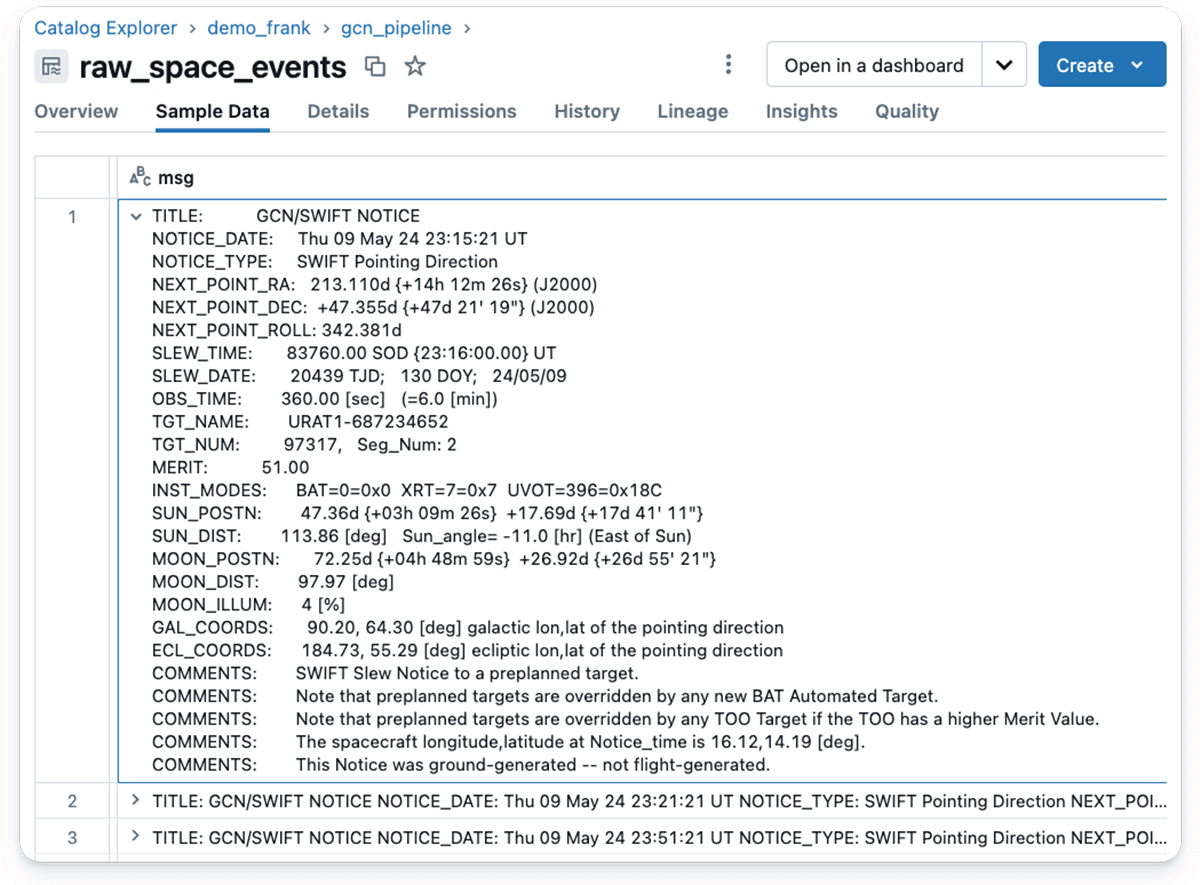
By clicking on Unity Catalog Pattern Knowledge within the UI, you possibly can view the contents of a Kafka message after it has been ingested:
As you possibly can see, the SQL retrieves the whole message as a single entity composed of traces, every containing a key phrase and worth.
Notice: The Swift messages include the main points of when and the way a satellite tv for pc slews into place to watch a cosmic occasion like a GRB.
As with my Kafka shopper above, a few of the largest telescopes on Earth, in addition to smaller robotic telescopes, decide up these messages. Based mostly on the advantage worth of the occasion, they determine whether or not to alter their predefined schedule to watch it or not.
The above Kafka message will be interpreted as follows:
The discover was issued on Thursday, Could 24, 2024, at 23:51:21 Common Time. It specifies the satellite tv for pc’s subsequent pointing path, which is characterised by its Proper Ascension (RA) and Declination (Dec) coordinates within the sky, each given in levels and within the J2000 epoch. The RA is 213.1104 levels, and the Dec is +47.355 levels. The spacecraft’s roll angle for this path is 342.381 levels. The satellite tv for pc will slew to this new place at 83760.00 seconds of the day (SOD), which interprets to 23:16:00.00 UT. The deliberate remark time is 60 seconds.
The title of the goal for this remark is “URAT1-687234652,” with a advantage worth of 51.00. The advantage worth signifies the goal’s precedence, which helps in planning and prioritizing observations, particularly when a number of potential targets can be found.
Latency and frequency
Utilizing the Kafka settings above with startingOffsets => 'earliest', the pipeline will devour all present knowledge from the Kafka subject. This configuration permits you to course of present knowledge instantly, with out ready for brand spanking new messages to reach.
Whereas gamma-ray bursts are uncommon occasions, occurring roughly as soon as per million years in a given galaxy, the huge variety of galaxies within the observable universe ends in frequent detections. Based mostly alone observations, new messages usually arrive each 10 to twenty minutes, offering a gentle stream of knowledge for evaluation.
Streaming knowledge is usually misunderstood as being solely about low latency, nevertheless it’s really about processing an unbounded circulate of messages incrementally as they arrive. This permits for real-time insights and decision-making.
The GCN state of affairs demonstrates an excessive case of latency. The occasions we’re analyzing occurred billions of years in the past, and their gamma rays solely reached us now.
It is possible essentially the most dramatic instance of event-time to ingestion-time latency you will encounter in your profession. But, the GCN state of affairs stays an important streaming knowledge use case!
DLT materialized views for advanced transformations
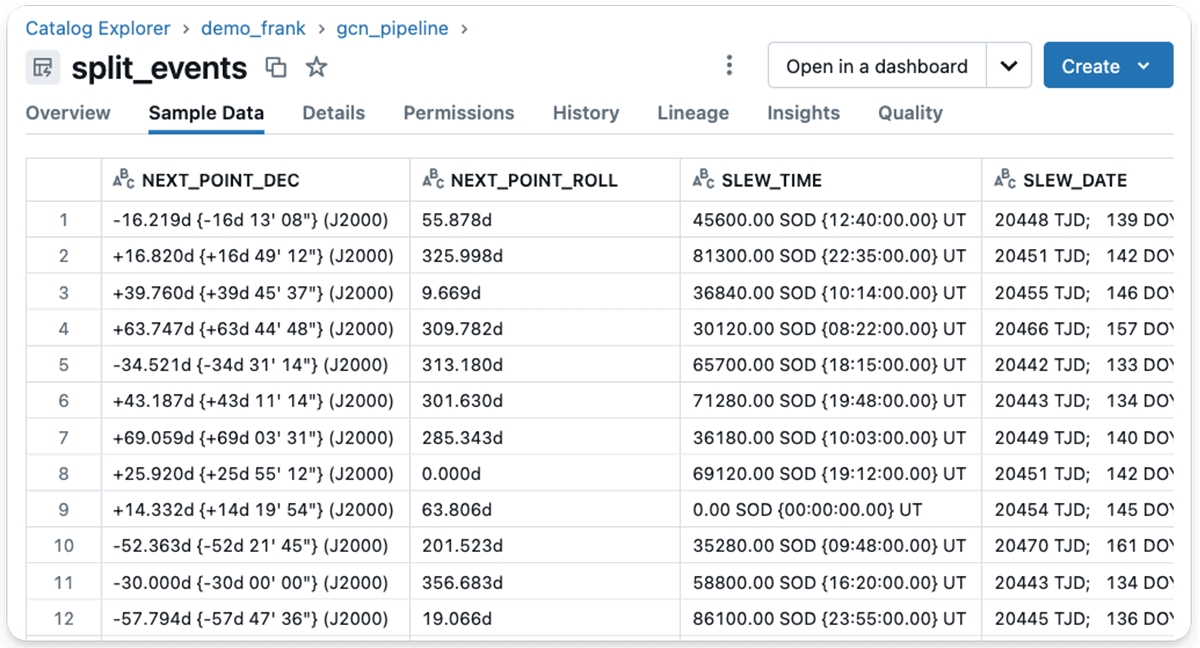
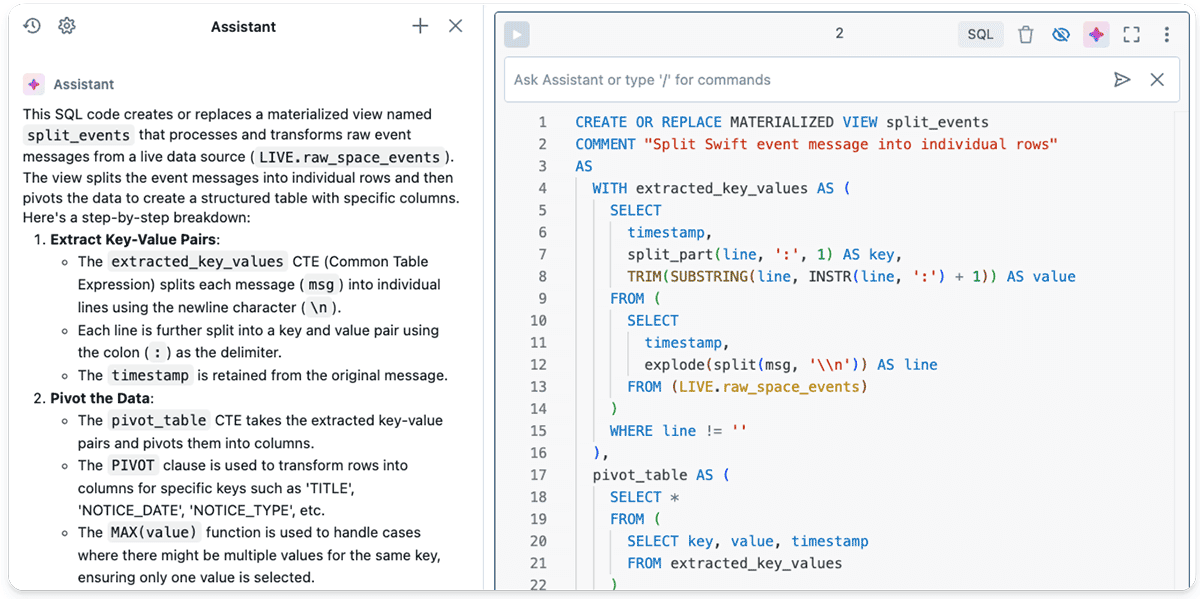
Within the subsequent step, I needed to get this Character Massive OBject (CLOB) of a Kafka message right into a schema to have the ability to make sense of the info. So I wanted a SQL answer to first cut up every message into traces after which cut up every line into key/worth pairs utilizing the pivot methodology in SQL.
I utilized the Databricks Assistant and our personal DBRX massive language mannequin (LLM) from the Databricks playground for help. Whereas the ultimate answer is a little more advanced with the total code out there within the repo, a fundamental skeleton constructed on a DLT materialized view is proven beneath:
CREATEOR REPLACE MATERIALIZED VIEW split_events
-- Break up Swift occasion message into particular person rowsASWITH-- Extract key-value pairs from uncooked occasions extracted_key_values AS (
-- cut up traces and extract key-value pairs from LIVE.raw_space_events ...
),
-- Pivot desk to remodel key-value pairs into columns pivot_table AS (
-- pivot extracted_key_values into columns for particular keys ...
)
SELECTtimestamp, TITLE, CAST(NOTICE_DATE ASTIMESTAMP) ASNOTICE_DATE, NOTICE_TYPE, NEXT_POINT_RA, NEXT_POINT_DEC,
NEXT_POINT_ROLL, SLEW_TIME, SLEW_DATE, OBS_TIME, TGT_NAME, TGT_NUM,
CAST(MERIT ASDECIMAL) AS MERIT, INST_MODES, SUN_POSTN, SUN_DIST,
MOON_POSTN, MOON_DIST, MOON_ILLUM, GAL_COORDS, ECL_COORDS, COMMENTS
FROM pivot_table
The strategy above makes use of a materialized view that divides every message into correct columns, as seen within the following screenshot.
Materialized views in Delta Reside Tables are notably helpful for advanced knowledge transformations that should be carried out repeatedly. Materialized views enable for quicker knowledge evaluation and dashboards with decreased latency.
Databricks Assistant for code era
Instruments just like the Databricks Assistant will be extremely helpful for producing advanced transformations. These instruments can simply outperform your SQL expertise (or not less than mine!) for such use instances.
Professional tip: Helpers just like the Databricks Assistant or the Databricks DBRX LLM do not simply assist you discover a answer; you may as well ask them to stroll you thru their answer step-by-step utilizing a simplified dataset. Personally, I discover this tutoring functionality of generative AI much more spectacular than its code era expertise!
Analyzing Supernova Knowledge With AI/BI Genie
In case you attended the Knowledge + AI Summit this 12 months, you’d have heard quite a bit about AI/BI. Databricks AI/BI is a brand new kind of enterprise intelligence product constructed to democratize analytics and insights for anybody in your group. It consists of two complementary capabilities, Genie and Dashboards, that are constructed on high of Databricks SQL. AI/BI Genie is a strong software designed to simplify and improve knowledge evaluation and visualization throughout the Databricks Platform.
At its core, Genie is a pure language interface that enables customers to ask questions on their knowledge and obtain solutions within the type of tables or visualizations. Genie leverages the wealthy metadata out there within the Knowledge Intelligence Platform, additionally coming from its unified governance system Unity Catalog, to feed machine studying algorithms that perceive the intent behind the consumer’s query. These algorithms then remodel the consumer’s question into SQL, producing a response that’s each related and correct.
What I like most is Genie’s transparency: It shows the generated SQL code behind the outcomes relatively than hiding it in a black field.
Having constructed a pipeline to ingest and remodel the info in DLT, I used to be then capable of begin analyzing my streaming desk and materialized view. I requested Genie quite a few questions to raised perceive the info. Here is a small pattern of what I explored:
What number of GRB occasions occurred within the final 30 days?
What’s the oldest occasion?
What number of occurred on a Monday? (It remembers the context. I used to be speaking in regards to the variety of occasions, and it is aware of the right way to apply temporal situations on an information stream.)
What number of occurred on common per day?
Give me a histogram of the advantage worth!
What’s the most advantage worth?
Not too way back, I’d have coded questions like “on common per day” as window capabilities utilizing advanced Spark, Kafka and even Flink statements. Now, it is plain English!
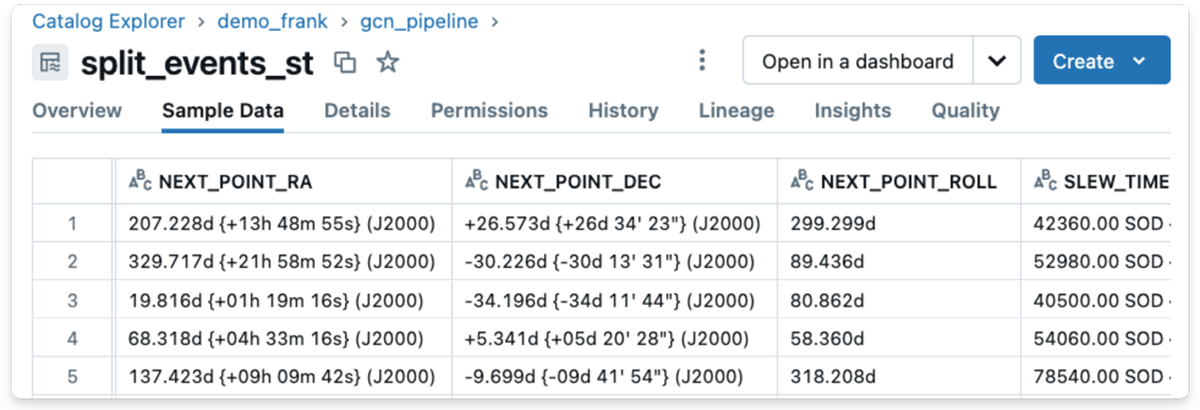
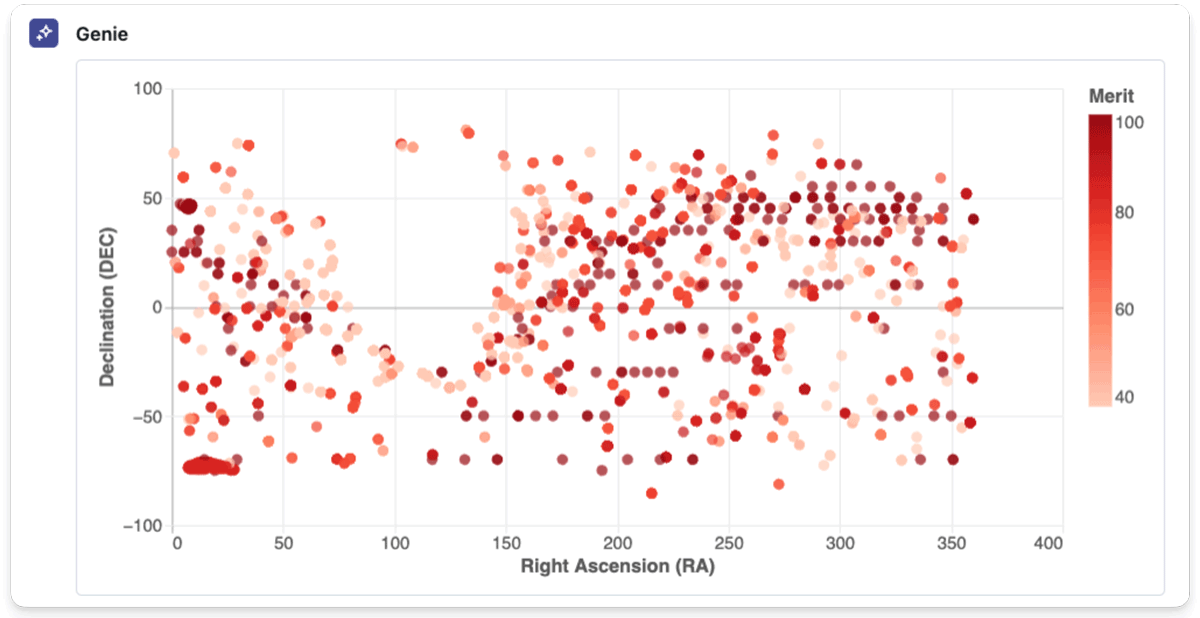
Final however not least, I created a 2D plot of the cosmic occasions utilizing their coordinates. As a result of complexity of filtering and extracting the info, I first carried out it in a separate pocket book, as a result of the coordinate knowledge is saved within the celestial system utilizing by some means redundant strings. The unique knowledge will be seen within the following screenshot of the info catalog:
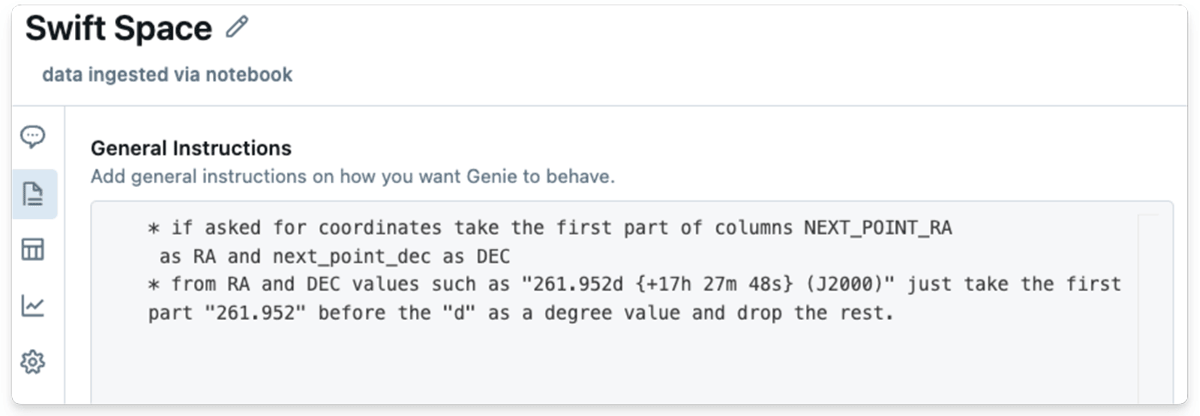
You may present directions in pure language or pattern queries to boost AI/BI’s understanding of jargon, logic and ideas like the actual coordinate system. So I attempted this out, and I offered a single instruction to AI/BI on retrieving floating-point values from the saved string knowledge and likewise gave it an instance.
Apparently, I defined the duty to AI/BI as I’d to a colleague, demonstrating the system’s means to know pure, conversational language.
To my shock, Genie was capable of recreate the whole plot — which had initially taken me a complete pocket book to code manually — with ease.
This demonstrated Genie’s means to generate advanced visualizations from pure language directions, making knowledge exploration extra accessible and environment friendly.
Abstract
NASA’s GCN community supplies superb reside knowledge to everybody. Whereas I used to be diving deep into supernova knowledge on this weblog, there are actually a whole bunch of different (Kafka) matters on the market ready to be explored.
I offered the total code so you possibly can run your personal Kafka shopper consuming the info stream and dive into the Knowledge Intelligence Platform or use open supply Apache Spark.
With the Knowledge Intelligence Platform, accessing supernova knowledge from NASA satellites is as simple as copying and pasting a single SQL command.
Knowledge engineers, scientists and analysts can simply ingest Kafka knowledge streams from SQL utilizing read_kafka().
DLT with AI/BI is the underestimated energy couple within the streaming world. I wager you will notice way more of it sooner or later.
Windowed stream processing, usually carried out with Apache Kafka, Spark or Flink utilizing advanced statements, might be drastically simplified with Genie on this case. By exploring your tables in a Genie knowledge room, you need to use pure language queries, together with temporal qualifiers like “during the last month” or “on common on a Monday,” to simply analyze and perceive your knowledge stream.
Assets
All options described on this weblog can be found on GitHub. To entry the challenge, clone the TMM repo with the cone sample NASA-swift-genie
For extra context, please watch my Knowledge + AI Summit session From Supernovas to LLMs which features a demonstration of a compound AI software that learns from 36,000 NASA circulars utilizing RAG with DBRX and Llama with LangChain (take a look at the mini weblog).
Solved. Due to AmMilinPatel’s nice assist. to me it is nice!!
Utilizing the assistance,I(user56534)accomplished my remaining supply code and share for others’s reference. However it have a bug that I do not know the rationale.If anybody know,please beneficiant to me. [URL-1!] https://datacentersupport.lenovo.com/ch/ko/warrantylookup#/ [URL-2!] https://datacentersupport.lenovo.com/ch/ko/merchandise/servers/thinksystem/sr650/7×06/7x06cto1ww/j30a7xlg/guarantee Bug description:The VBA clicks URL-1, then get URL-2 routinely nicely most case. However in an important whereas,between URL-1 and URL-2, a alert window(see connected picture) pop up. In that solid, I have to click on one among two choices. I wish to do it in Code. I attempted chd.SwitchToAlert.Settle for with out success. My new objective: how can click on one among two choices between URL-1 and URL-2.
Picture desc: Due to not figuring out the way to add picture,I describe in textual content. Primarily based on IP,though bodily consumer is in Switzerland,this web site is in US. Both ahead to Switzerland or proceed with this US web site. After which beneath, there’re two icons. one is for Switzerland and the opposite is for US.
'My new revised full code
Sub ScrapeWTY_Solved()
Dim ss As String
Dim i, j
Dim chd As New Selenium.ChromeDriver
Dim arr As Variant, merchandise As Variant
arr = Array("j30a7xlg", "J303A3DB")
chd.Get "https://datacentersupport.lenovo.com/us/ko/warrantylookup#/"
For i = 1 To 10
For j = LBound(arr) To UBound(arr)
chd.FindElementByClass("button-placeholder__input").SendKeys arr(j)
'-----------------------------------------
' Look ahead to the submit button to turn out to be clickable
'chd.WaitElementPresentByCss("#app-standalone-warrantylookup button", timeout:=5000) 'Not working, Why?
chd.Wait 5000
'chd.SwitchToAlert.Settle for 'Not working
' Click on the submit button
chd.FindElementByCss("#app-standalone-warrantylookup button").Click on
chd.Wait 5000
Debug.Print i, j, arr(j), chd.FindElementByCss("#app-psp-warranty > div.psp-warranty__body > div > div.psp-warranty__status > div > div.warranty-status__content > div > div.chart-time-bucket > div.chart-expires > p:nth-child(2) > sturdy").Textual content
chd.GoBack
Subsequent j
Subsequent i
Finish Sub
AI is likely one of the hottest issues within the tech trade. Like knowledge engineering, AI engineering has turn out to be well-liked as a result of this growing demand for AI merchandise.
However to be an AI engineer, what instruments should you recognize? This checklist, which incorporates AI instruments, may need been increasing due to growing reputation, however you have to preserve up to date and achieve abilities about these instruments.
On this article, we’ll discover these instruments collectively, however first, let’s deal with AI Engineering; let’s begin!
What’s an AI Engineer?
An AI engineer is an individual who builds, maintains, and optimizes AI programs or purposes. Such practices require specialists who combine software program improvement with machine studying to construct clever programs designed to carry out human-like duties.
They design predictive fashions and develop autonomous programs, so their data consists of not simply theoretical data however sensible abilities that may be utilized to real-world issues.
After all, to do this, they should know learn how to program programs, which requires programming data.
Programming Information
Robust programming data is a should for an AI engineer to shine. That is why you will need to excel at just a few key languages.
Python
Python has dynamic libraries, equivalent to TensorFlow and PyTorch, which are nice for AI mannequin coaching. These libraries have lively communities that preserve them up to date.
This high-level, general-purpose programming that permits freedom for speedy prototyping and quick iteration over the codes is what makes Python a best choice amongst AI engineers.
One other essential language is R, particularly in statistical evaluation and knowledge visualization. It has robust data-handling capabilities and is utilized in academia and analysis. R is a device for heavy statistical duties and graphics necessities.
You may see many arguments between R and Python when individuals talk about discovering the very best programming language for knowledge science. Knowledge Science may be a distinct subject. Nonetheless, to turn out to be an AI engineer, you have to do many duties {that a} Knowledge Scientist does.
That’s why you may want to search out a solution to this previous debate too: which is healthier, R or Python? To see the comparability, try this one.
Java
Java has been used to construct massive programs and purposes. It’s not as well-liked for AI-specific duties however is essential in deploying AI options on present enterprise programs. Java’s energy and scalability make it a helpful weapon for an AI engineer.
SQL
You can’t handle databases with out SQL. As an AI engineer, working with relational databases might be most of your work as a result of it entails coping with and cleansing massive datasets.
That is the place SQL is available in that will help you extract, manipulate, and analyze this knowledge rapidly. Doing so helps present clear, thinned-out structured data you can ahead to your fashions.
Machine studying may be the core a part of this operation. However earlier than studying machine studying, you’ll want to find out about math, statistics, and linear algebra.
Math
Understanding machine studying strategies will depend on a robust mathematical basis. Necessary sections cowl chance idea and calculus. Whereas chance idea clarifies fashions like Bayesian networks, calculus helps optimization strategies.
Take a look at this one to apply your data of Math with Python and study extra about coding libraries utilized in Math.
Statistics
Statistics are important for deciphering knowledge and verifying fashions. Speculation testing, regression, and distribution are the foundations of a statistical examine. Understanding these permits you to assess mannequin efficiency and make data-driven selections.
Linear algebra is the language of machine studying. It’s utilized in strategies utilizing vectors and matrices, that are fundamental in knowledge illustration and transformations.
Understanding algorithms equivalent to PCA (Principal Element Evaluation) and SVD (Singular Worth Decomposition) will depend on a data of key concepts equivalent to matrix multiplication, eigenvalues, and eigenvectors.
Right here is the very best video sequence from 3Blue1Brown, the place you’ll be able to perceive linear algebra utterly.
Large Knowledge
AI Options depend on the AI scene, which huge knowledge helps. Particularly, it talks concerning the terabytes of knowledge generated on daily basis. Synthetic intelligence designers have to deal with this knowledge appropriately and successfully. The under examples showcase huge knowledge companies.
Hadoop
Hadoop is an open-source software program framework for storing and processing massive datasets in a distributed file system throughout pc nodes. It scales to run on 1000’s of servers, providing native computation and storage, making it ultimate for high-scale coaching.
This structure has capabilities that enable for environment friendly dealing with of huge knowledge and allow it to be dependable and scalable.
Spark
Apache Spark is a quick and general-purpose cluster computing system for giant knowledge. It supplies high-level APIs in Java, Scala, Python, and R and an optimized engine that helps basic execution graphs. Advantages are;
Good Efficiency
Simple to make use of ( Spark)
Able to processing enormous quantities of knowledge at lightning pace and suitable with varied programming languages
It’s a highly effective weapon within the fingers of an AI engineer. If you wish to know extra about PySpark, a Python Apache Spark interface, try “What Is PySpark?”.
NoSQL Databases
They’re designed to retailer and course of huge lots of unstructured knowledge, known as NoSQL databases—e.g., MongoDB or Cassandra. Not like conventional SQL’s, NoSQL databases are scaleable and versatile, so you’ll be able to retailer knowledge extra effectively, becoming into complicated knowledge constructions for AI.
This, in flip, permits AI engineers to retailer and higher use massive datasets, which is critical to provide highly effective prediction fashions (machine studying) and decision-making that requires quick knowledge processing pace.
If you wish to know extra about Large Knowledge and the way it works, try this one.
Cloud Companies
Many Cloud Companies can be found, nevertheless it’s finest to familiarize your self with essentially the most used ones.
Amazon Internet Companies (AWS)
AWS affords a variety of cloud companies, from storage to server capability and machine studying fashions. Key companies embrace:
S3 (Easy Storage Service): For giant dataset storage.
EC2 (Elastic Compute Cloud): For scalable computing sources.
Google Cloud Platform (GCP)
GCP is tailor-made for AI and large knowledge. Key companies embrace:
BigQuery: A completely managed knowledge warehouse for executing SQL queries rapidly utilizing Google’s infrastructure.
TensorFlow and AutoML: AI and machine studying instruments for creating and deploying fashions.
Microsoft Azure
Azure supplies a number of companies for AI and large knowledge, together with:
Azure Blob Storage: Massively scalable object storage for just about limitless unstructured knowledge.
Azure Machine Studying: Instruments for internet hosting varied ML fashions, together with quick coaching or custom-coded fashions.
Follow: The Means of Turning into a Grasp
AI Mastery is Greater than Idea Initiatives are essential to realize sensible expertise. So listed here are just a few shortcuts to apply and enhance your AUTHORICIENT abilities:
Constructing a predictive mannequin in each Machine Studying and Deep Studying
These initiatives give hands-on expertise in knowledge fetching, cleansing, exploratory evaluation, and modeling. They put together you for real-life issues.
Kaggle Competitions
Kaggle competitions are one of the best ways of cracking Knowledge initiatives if you’re initially of the street. They won’t solely give lots of datasets, however some competitions may be an actual motivation for you as a result of some supply greater than $100K.
Open Supply Contributions
Open-source contributions could be one of the best ways to really feel assured and competent. Even newbie programmers can discover bugs in very complicated codes.
As an illustration langchain, it’s a means of utilizing totally different language fashions collectively. Be at liberty to go to this open-source GitHub repository and begin exploring.
You probably have hassle loading or putting in any of their options, report a problem and be lively locally.
On-line Programs and Tutorials
If you wish to see a program tailor-made to your ability set and earn a certification from well-known institutes, be at liberty to go to web sites like Coursera, Edx, and Udacity. They’ve many machine studying and AI programs that may concurrently provide you with theoretical and sensible data.
Ultimate Ideas
On this article, we explored what AI Engineers imply and which instruments they need to know, from programming to cloud companies.
To wrap up, studying Python, R, huge knowledge frameworks, and cloud companies equips AI engineers with the instruments wanted to construct strong AI options that meet fashionable challenges head-on.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from prime corporations. Nate writes on the most recent traits within the profession market, provides interview recommendation, shares knowledge science initiatives, and covers every thing SQL.
Biocomputing is likely one of the most weird frontiers in rising expertise, made potential by the truth that our neurons understand the world and act on it talking the identical language as computer systems do – electrical indicators. Human mind cells, grown in giant numbers onto silicon chips, can obtain electrical indicators from a pc, attempt to make sense of them, and discuss again.
Extra importantly, they’ll be taught. The primary time we encountered the idea was within the DishBrain challenge at Monash College, Australia. In what should’ve felt like a Dr. Frankenstein second, researchers grew about 800,000 mind cells onto a chip, put it right into a simulated atmosphere, and watched this horrific cyborg abomination be taught to play Pong inside about 5 minutes. The challenge was shortly funded by the Australian army, and spun out into an organization known as Cortical Labs.
Cortical Labs has prototyped computing modules constructed round human mind cells, and is trying to commercialize this hybrid studying intelligence
Cortical Labs
When we interviewed Cortical Labs’ Chief Scientific Officer Brett Kagan, he advised us that even at an early stage, human neuron-enhanced biocomputers seem to be taught a lot quicker, utilizing a lot much less energy, than right this moment’s AI machine studying chips, whereas demonstrating “extra instinct, perception and creativity.” Our brains, in spite of everything, eat only a tiny 20 watts to run nature’s strongest necktop computer systems.
“We have achieved exams in opposition to reinforcement studying,” Kagan advised us, “and we discover that by way of how shortly the variety of samples the system has to see earlier than it begins to indicate significant studying, it is chalk and cheese. The organic techniques, at the same time as primary and janky as they’re proper now, are nonetheless outperforming one of the best deep studying algorithms that folks have generated. That is fairly wild.”
One draw back – other than some clearly thorny ethics – is that the “wetware” parts must be saved alive. Meaning conserving them fed, watered, temperature-controlled and protected against germs and viruses. Cortical’s document again in 2023 was about 12 months.
4 human mind organoids, every with round 10,000 dwelling human mind cells, wired right into a biocomputing array in FinalSpark’ s Neuroplatform
If that is the primary time you’ve got heard about this brain-on-a-chip stuff, do choose your jaw up off the ground and browse a couple of of these hyperlinks – that is completely staggering work. And now Chinese language researchers say they’re taking it to the following stage.
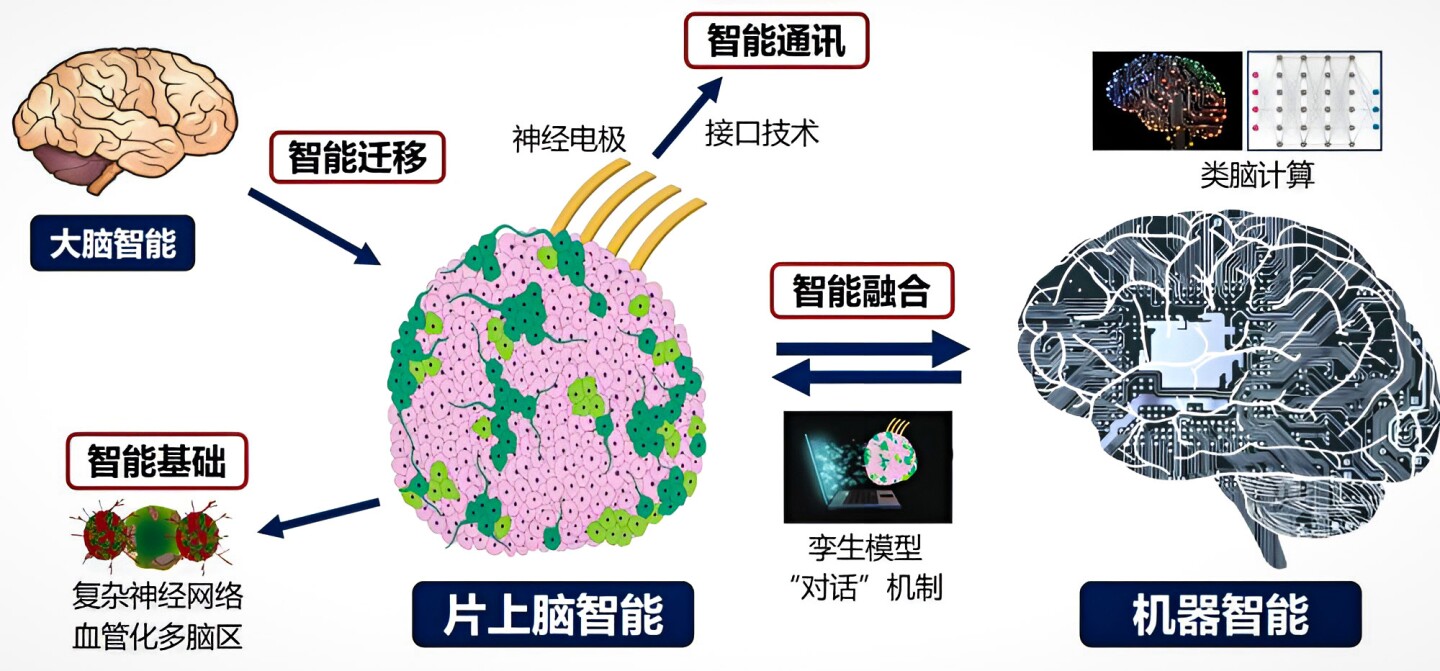
The MetaBOC (BOC for brain-on-chip, after all) challenge brings collectively researchers from Tianjin College’s Haihe Laboratory of Mind-Pc Interplay and Human-Pc Integration with different groups from the Southern College of Science and Know-how.
Key parts of brain-on-chip applied sciences, helpfully labelled in Chinese language
Tianjin College
It is an open-source piece of software program designed to behave as an interface between brain-on-a-chip biocomputers and different digital gadgets, giving the mind organoid the flexibility to understand the world by digital indicators, function on it by no matter controls it is given entry to, and be taught to grasp sure duties.
The Tianjin crew says it is utilizing ball-shaped organoids, very similar to the Brainoware crew at Indiana, since their three-dimensional bodily construction permits them to kind extra complicated neural connections, very similar to they do in our brains. These organoids are grown underneath low-intensity centered ultrasound stimulation, which the researchers say appears to present them a greater clever basis to construct on.
The MetaBOC system additionally tries to satisfy intelligence with intelligence, utilizing AI algorithms inside the software program to speak with the mind cells’ organic intelligence.
The Tianjin crew particularly mentions robotics as an integration goal, and gives the quite foolish photos above, as if intentionally attempting to undermine the credibility of the work. A brain-on-a-chip biocomputer, says the crew, can now be taught to drive a robotic, determining the controls and trying duties like avoiding obstacles, monitoring targets, or studying to make use of arms and fingers to understand numerous objects.
As a result of the mind organoid is simply in a position to ‘see’ the world by {the electrical} indicators offered to it, it could actually theoretically prepare itself up on the way to pilot its mini-gundam in a completely simulated atmosphere, permitting it to get most of its falling and crashing out of the best way with out jeopardizing its fleshy intelligence engine.
No, the organoids in all probability will not be that large to start with. They may, nonetheless, require all types of help gear, together with fluid and nutrient strains, anti-pathogenic seals, temperature-control and shock-proofing techniques
Tianjin College
Now, to be crystal clear, the absolutely uncovered, pink lollipop-style mind organoids within the robotic photos above are mockups – “demonstration diagrams of future software eventualities” – quite than brain-controlled prototypes. Maybe the picture beneath, from Cortical Labs, is a greater illustration of what these sorts of brains on chips will seem like in the true world.
Cortical Labs’ “wetware,” wanting significantly moist after a check session
Cortical Labs
However both approach, if you happen to constructed a small robotic with applicable sensing and motor capabilities, we see no purpose why human mind cells could not quickly be in there attempting to get the cling of driving it.
It is a phenomenal time for science and expertise, with tasks like Neuralink aiming to hook high-bandwidth pc interfaces straight into your mind, whereas tasks like MetaBOC develop human mind cells into computer systems, and the surging AI business makes an attempt to overhaul one of the best of organic intelligence with some unusual facsimile constructed totally in silicon.
Science and tech are pressured to get philosophical as they slam up in opposition to the bounds of our understanding; are dish-brains acutely aware? Are AIs acutely aware? Each could conceivably find yourself being indistinguishable from sentient beings in some unspecified time in the future within the close to future. What are the ethics as soon as that occurs? Are they totally different for organic and silicon-based intelligences?
“As an example,” says Kagan in our intensive interview, “that these techniques do develop consciousness – in my view, most unlikely, however for example it does occur. Then it’s worthwhile to determine, properly, is it truly ethically proper to check with them or not? As a result of we do check on acutely aware creatures. , we check on animals, which I believe have a stage of consciousness, with none fear … We eat animals, many people, with little or no fear, nevertheless it’s justifiable.”
Frankly, I can hardly imagine what I am writing; that humanity is beginning to take the bodily constructing blocks of its personal thoughts, and use them to construct cyborg minds able to intelligently controlling machines.
However that is life in 2024, as we speed up full-throttle towards the mysterious technological singularity, the purpose the place AI intelligence surpasses our personal, and begins creating issues even quicker than people can. The purpose the place technological progress – which is already taking place at unprecedented velocity – accelerates towards a vertical line, and we lose management of it altogether.
What a time to be alive – and never as a clump of cells wired to a chip in a dish. Effectively, so far as we all know.