As a UX skilled in in the present day’s data-driven panorama, it’s more and more seemingly that you just’ve been requested to design a customized digital expertise, whether or not it’s a public web site, consumer portal, or native software. But whereas there continues to be no scarcity of selling hype round personalization platforms, we nonetheless have only a few standardized approaches for implementing customized UX.
Article Continues Beneath
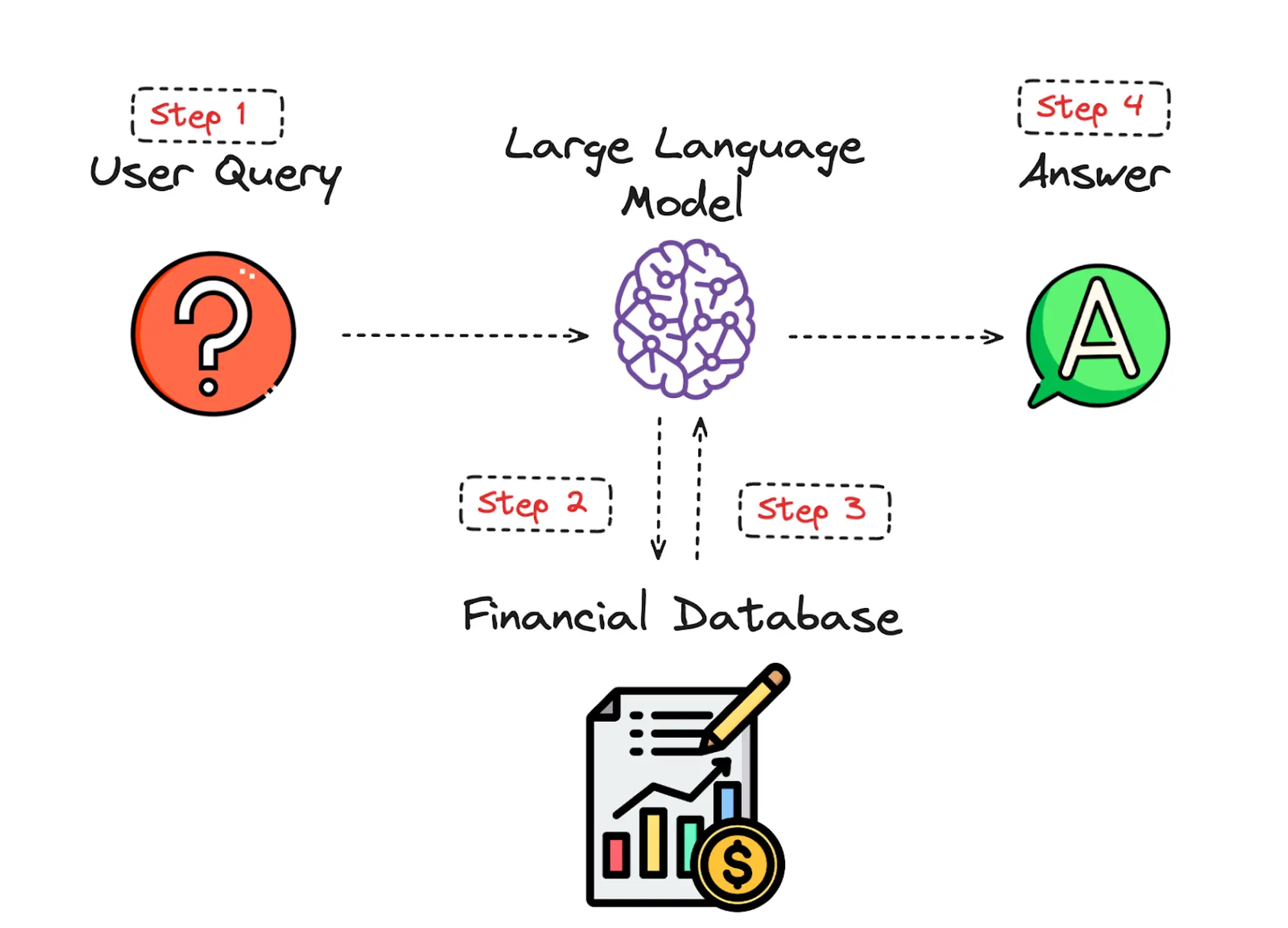
That’s the place we are available. After finishing dozens of personalization tasks over the previous few years, we gave ourselves a objective: might you create a holistic personalization framework particularly for UX practitioners? The Personalization Pyramid is a designer-centric mannequin for standing up human-centered personalization packages, spanning knowledge, segmentation, content material supply, and general targets. By utilizing this strategy, it is possible for you to to grasp the core parts of a up to date, UX-driven personalization program (or on the very least know sufficient to get began).

Rising instruments for personalization: In keeping with a Dynamic Yield survey, 39% of respondents felt assist is accessible on-demand when a enterprise case is made for it (up 15% from 2020).
Supply: “The State of Personalization Maturity – This fall 2021” Dynamic Yield performed its annual maturity survey throughout roles and sectors within the Americas (AMER), Europe and the Center East (EMEA), and the Asia-Pacific (APAC) areas. This marks the fourth consecutive 12 months publishing our analysis, which incorporates greater than 450 responses from people within the C-Suite, Advertising, Merchandising, CX, Product, and IT.
For the sake of this text, we’ll assume you’re already aware of the fundamentals of digital personalization. A superb overview will be discovered right here: Web site Personalization Planning. Whereas UX tasks on this space can tackle many alternative kinds, they usually stem from comparable beginning factors.
Frequent eventualities for beginning a personalization challenge:
- Your group or consumer bought a content material administration system (CMS) or advertising and marketing automation platform (MAP) or associated know-how that helps personalization
- The CMO, CDO, or CIO has recognized personalization as a objective
- Buyer knowledge is disjointed or ambiguous
- You’re working some remoted concentrating on campaigns or A/B testing
- Stakeholders disagree on personalization strategy
- Mandate of buyer privateness guidelines (e.g. GDPR) requires revisiting present consumer concentrating on practices

No matter the place you start, a profitable personalization program would require the identical core constructing blocks. We’ve captured these because the “ranges” on the pyramid. Whether or not you’re a UX designer, researcher, or strategist, understanding the core parts can assist make your contribution profitable.

From high to backside, the degrees embrace:
- North Star: What bigger strategic goal is driving the personalization program?
- Objectives: What are the precise, measurable outcomes of this system?
- Touchpoints: The place will the customized expertise be served?
- Contexts and Campaigns: What personalization content material will the consumer see?
- Person Segments: What constitutes a novel, usable viewers?
- Actionable Knowledge: What dependable and authoritative knowledge is captured by our technical platform to drive personalization?
- Uncooked Knowledge: What wider set of information is conceivably out there (already in our setting) permitting you to personalize?
We’ll undergo every of those ranges in flip. To assist make this actionable, we created an accompanying deck of playing cards as an example particular examples from every degree. We’ve discovered them useful in personalization brainstorming classes, and can embrace examples for you right here.

Beginning on the Prime#section3
The parts of the pyramid are as follows:
North Star#section4
A north star is what you might be aiming for general together with your personalization program (huge or small). The North Star defines the (one) general mission of the personalization program. What do you want to accomplish? North Stars forged a shadow. The larger the star, the larger the shadow. Instance of North Begins may embrace:
- Operate: Personalize based mostly on fundamental consumer inputs. Examples: “Uncooked” notifications, fundamental search outcomes, system consumer settings and configuration choices, normal customization, fundamental optimizations
- Function: Self-contained personalization componentry. Examples: “Cooked” notifications, superior optimizations (geolocation), fundamental dynamic messaging, personalized modules, automations, recommenders
- Expertise: Customized consumer experiences throughout a number of interactions and consumer flows. Examples: Electronic mail campaigns, touchdown pages, superior messaging (i.e. C2C chat) or conversational interfaces, bigger consumer flows and content-intensive optimizations (localization).
- Product: Extremely differentiating customized product experiences. Examples: Standalone, branded experiences with personalization at their core, just like the “algotorial” playlists by Spotify reminiscent of Uncover Weekly.



Objectives#section5
As in any good UX design, personalization can assist speed up designing with buyer intentions. Objectives are the tactical and measurable metrics that may show the general program is profitable. A superb place to begin is together with your present analytics and measurement program and metrics you may benchmark in opposition to. In some instances, new targets could also be applicable. The important thing factor to recollect is that personalization itself is just not a objective, relatively it’s a means to an finish. Frequent targets embrace:
- Conversion
- Time on job
- Web promoter rating (NPS)
- Buyer satisfaction



Touchpoints#section6
Touchpoints are the place the personalization occurs. As a UX designer, this might be considered one of your largest areas of duty. The touchpoints out there to you’ll rely upon how your personalization and related know-how capabilities are instrumented, and must be rooted in bettering a consumer’s expertise at a specific level within the journey. Touchpoints will be multi-device (cellular, in-store, web site) but additionally extra granular (net banner, net pop-up and so forth.). Listed here are some examples:
Channel-level Touchpoints
- Electronic mail: Position
- Electronic mail: Time of open
- In-store show (JSON endpoint)
- Native app
- Search
Wireframe-level Touchpoints
- Internet overlay
- Internet alert bar
- Internet banner
- Internet content material block
- Internet menu



For those who’re designing for net interfaces, for instance, you’ll seemingly want to incorporate customized “zones” in your wireframes. The content material for these will be offered programmatically in touchpoints based mostly on our subsequent step, contexts and campaigns.


Supply: “Important Information to Finish-to-Finish Personaliztion” by Kibo.
Contexts and Campaigns#section7
When you’ve outlined some touchpoints, you may think about the precise customized content material a consumer will obtain. Many personalization instruments will refer to those as “campaigns” (so, for instance, a marketing campaign on an internet banner for brand spanking new guests to the web site). These will programmatically be proven at sure touchpoints to sure consumer segments, as outlined by consumer knowledge. At this stage, we discover it useful to contemplate two separate fashions: a context mannequin and a content material mannequin. The context helps you think about the extent of engagement of the consumer on the personalization second, for instance a consumer casually looking info vs. doing a deep-dive. Consider it when it comes to info retrieval behaviors. The content material mannequin can then assist you to decide what sort of personalization to serve based mostly on the context (for instance, an “Enrich” marketing campaign that reveals associated articles could also be an acceptable complement to extant content material).
Personalization Context Mannequin:
- Browse
- Skim
- Nudge
- Feast
Personalization Content material Mannequin:
- Alert
- Make Simpler
- Cross-Promote
- Enrich
We’ve written extensively about every of those fashions elsewhere, so in case you’d prefer to learn extra you may take a look at Colin’s Personalization Content material Mannequin and Jeff’s Personalization Context Mannequin.



Person Segments#section8
Person segments will be created prescriptively or adaptively, based mostly on consumer analysis (e.g. by way of guidelines and logic tied to set consumer behaviors or by way of A/B testing). At a minimal you’ll seemingly want to contemplate how you can deal with the unknown or first-time customer, the visitor or returning customer for whom you might have a stateful cookie (or equal post-cookie identifier), or the authenticated customer who’s logged in. Listed here are some examples from the personalization pyramid:
- Unknown
- Visitor
- Authenticated
- Default
- Referred
- Position
- Cohort
- Distinctive ID



Actionable Knowledge#section9
Each group with any digital presence has knowledge. It’s a matter of asking what knowledge you may ethically accumulate on customers, its inherent reliability and worth, as to how are you going to use it (typically often known as “knowledge activation.”) Happily, the tide is popping to first-party knowledge: a latest examine by Twilio estimates some 80% of companies are utilizing at the very least some sort of first-party knowledge to personalize the client expertise.

First-party knowledge represents a number of benefits on the UX entrance, together with being comparatively easy to gather, extra more likely to be correct, and fewer inclined to the “creep issue” of third-party knowledge. So a key a part of your UX technique must be to find out what the very best type of knowledge assortment is in your audiences. Listed here are some examples:




There’s a development of profiling in the case of recognizing and making decisioning about totally different audiences and their indicators. It tends to maneuver in direction of extra granular constructs about smaller and smaller cohorts of customers as time and confidence and knowledge quantity develop.
Whereas some mixture of implicit / express knowledge is mostly a prerequisite for any implementation (extra generally known as first celebration and third-party knowledge) ML efforts are sometimes not cost-effective immediately out of the field. It is because a powerful knowledge spine and content material repository is a prerequisite for optimization. However these approaches must be thought-about as a part of the bigger roadmap and should certainly assist speed up the group’s general progress. Usually at this level you’ll associate with key stakeholders and product house owners to design a profiling mannequin. The profiling mannequin contains defining strategy to configuring profiles, profile keys, profile playing cards and sample playing cards. A multi-faceted strategy to profiling which makes it scalable.
Whereas the playing cards comprise the place to begin to a list of kinds (we offer blanks so that you can tailor your individual), a set of potential levers and motivations for the type of personalization actions you aspire to ship, they’re extra priceless when considered in a grouping.
In assembling a card “hand”, one can start to hint your entire trajectory from management focus down by a strategic and tactical execution. Additionally it is on the coronary heart of the way in which each co-authors have performed workshops in assembling a program backlog—which is a advantageous topic for an additional article.
Within the meantime, what’s necessary to notice is that every coloured class of card is useful to survey in understanding the vary of decisions probably at your disposal, it’s threading by and making concrete selections about for whom this decisioning might be made: the place, when, and the way.

Any sustainable personalization technique should think about close to, mid and long-term targets. Even with the main CMS platforms like Sitecore and Adobe or essentially the most thrilling composable CMS DXP on the market, there may be merely no “simple button” whereby a personalization program will be stood up and instantly view significant outcomes. That mentioned, there’s a widespread grammar to all personalization actions, identical to each sentence has nouns and verbs. These playing cards try and map that territory.
 App")